 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaoyuan Wang
AvatarGPT: All-in-One Framework for Motion Understanding, Planning, Generation and Beyond
Nov 28, 2023
Large Language Models(LLMs) have shown remarkable emergent abilities in unifying almost all (if not every) NLP tasks. In the human motion-related realm, however, researchers still develop siloed models for each task. Inspired by InstuctGPT, and the generalist concept behind Gato, we introduce AvatarGPT, an All-in-One framework for motion understanding, planning, generations as well as other tasks such as motion in-between synthesis. AvatarGPT treats each task as one type of instruction fine-tuned on the shared LLM. All the tasks are seamlessly interconnected with language as the universal interface, constituting a closed-loop within the framework. To achieve this, human motion sequences are first encoded as discrete tokens, which serve as the extended vocabulary of LLM. Then, an unsupervised pipeline to generate natural language descriptions of human action sequences from in-the-wild videos is developed. Finally, all tasks are jointly trained. Extensive experiments show that AvatarGPT achieves SOTA on low-level tasks, and promising results on high-level tasks, demonstrating the effectiveness of our proposed All-in-One framework. Moreover, for the first time, AvatarGPT enables a principled approach by iterative traversal of the tasks within the closed-loop for unlimited long-motion synthesis.
HAVE-FUN: Human Avatar Reconstruction from Few-Shot Unconstrained Images
Nov 27, 2023As for human avatar reconstruction, contemporary techniques commonly necessitate the acquisition of costly data and struggle to achieve satisfactory results from a small number of casual images. In this paper, we investigate this task from a few-shot unconstrained photo album. The reconstruction of human avatars from such data sources is challenging because of limited data amount and dynamic articulated poses. For handling dynamic data, we integrate a skinning mechanism with deep marching tetrahedra (DMTet) to form a drivable tetrahedral representation, which drives arbitrary mesh topologies generated by the DMTet for the adaptation of unconstrained images. To effectively mine instructive information from few-shot data, we devise a two-phase optimization method with few-shot reference and few-shot guidance. The former focuses on aligning avatar identity with reference images, while the latter aims to generate plausible appearances for unseen regions. Overall, our framework, called HaveFun, can undertake avatar reconstruction, rendering, and animation. Extensive experiments on our developed benchmarks demonstrate that HaveFun exhibits substantially superior performance in reconstructing the human body and hand. Project website: https://seanchenxy.github.io/HaveFunWeb/.
DialCoT Meets PPO: Decomposing and Exploring Reasoning Paths in Smaller Language Models
Oct 23, 2023


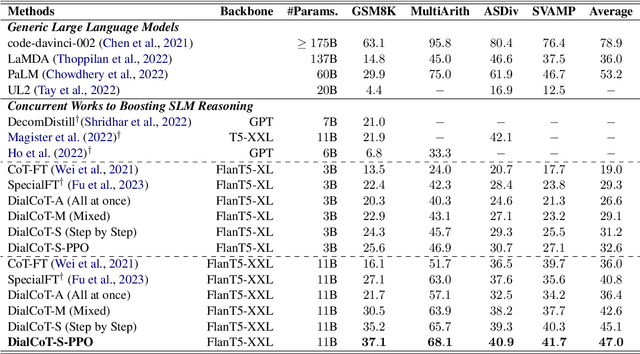
Chain-of-Thought (CoT) prompting has proven to be effective in enhancing the reasoning capabilities of Large Language Models (LLMs) with at least 100 billion parameters. However, it is ineffective or even detrimental when applied to reasoning tasks in Smaller Language Models (SLMs) with less than 10 billion parameters. To address this limitation, we introduce Dialogue-guided Chain-of-Thought (DialCoT) which employs a dialogue format to generate intermediate reasoning steps, guiding the model toward the final answer. Additionally, we optimize the model's reasoning path selection using the Proximal Policy Optimization (PPO) algorithm, further enhancing its reasoning capabilities. Our method offers several advantages compared to previous approaches. Firstly, we transform the process of solving complex reasoning questions by breaking them down into a series of simpler sub-questions, significantly reducing the task difficulty and making it more suitable for SLMs. Secondly, we optimize the model's reasoning path selection through the PPO algorithm. We conduct comprehensive experiments on four arithmetic reasoning datasets, demonstrating that our method achieves significant performance improvements compared to state-of-the-art competitors.
MDSC: Towards Evaluating the Style Consistency Between Music and
Sep 04, 2023We propose MDSC(Music-Dance-Style Consistency), the first evaluation metric which assesses to what degree the dance moves and music match. Existing metrics can only evaluate the fidelity and diversity of motion and the degree of rhythmic matching between music and motion. MDSC measures how stylistically correlated the generated dance motion sequences and the conditioning music sequences are. We found that directly measuring the embedding distance between motion and music is not an optimal solution. We instead tackle this through modelling it as a clustering problem. Specifically, 1) we pre-train a music encoder and a motion encoder, then 2) we learn to map and align the motion and music embedding in joint space by jointly minimizing the intra-cluster distance and maximizing the inter-cluster distance, and 3) for evaluation purpose, we encode the dance moves into embedding and measure the intra-cluster and inter-cluster distances, as well as the ratio between them. We evaluate our metric on the results of several music-conditioned motion generation methods, combined with user study, we found that our proposed metric is a robust evaluation metric in measuring the music-dance style correlation. The code is available at: https://github.com/zixiangzhou916/MDSC.
Controlling Character Motions without Observable Driving Source
Aug 11, 2023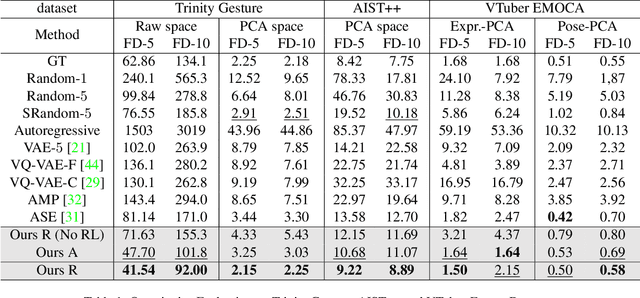
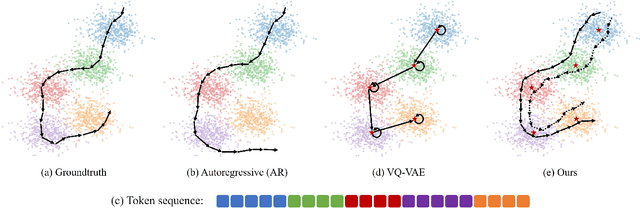
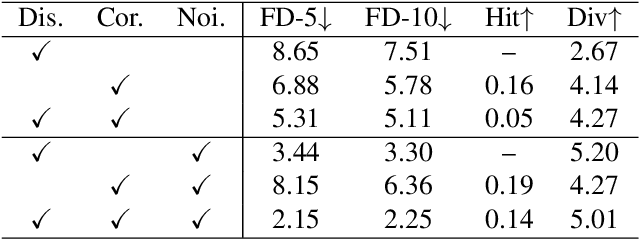
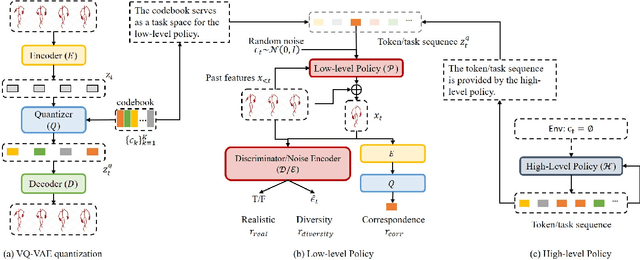
How to generate diverse, life-like, and unlimited long head/body sequences without any driving source? We argue that this under-investigated research problem is non-trivial at all, and has unique technical challenges behind it. Without semantic constraints from the driving sources, using the standard autoregressive model to generate infinitely long sequences would easily result in 1) out-of-distribution (OOD) issue due to the accumulated error, 2) insufficient diversity to produce natural and life-like motion sequences and 3) undesired periodic patterns along the time. To tackle the above challenges, we propose a systematic framework that marries the benefits of VQ-VAE and a novel token-level control policy trained with reinforcement learning using carefully designed reward functions. A high-level prior model can be easily injected on top to generate unlimited long and diverse sequences. Although we focus on no driving sources now, our framework can be generalized for controlled synthesis with explicit driving sources. Through comprehensive evaluations, we conclude that our proposed framework can address all the above-mentioned challenges and outperform other strong baselines very significantly.
Reinforced Disentanglement for Face Swapping without Skip Connection
Aug 03, 2023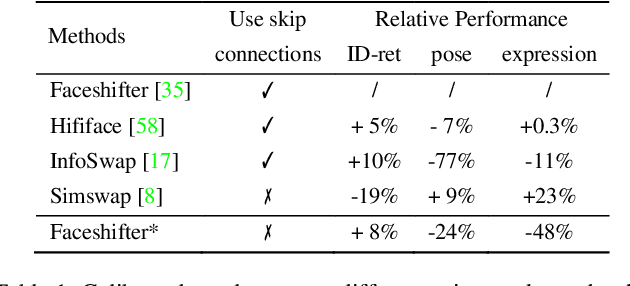
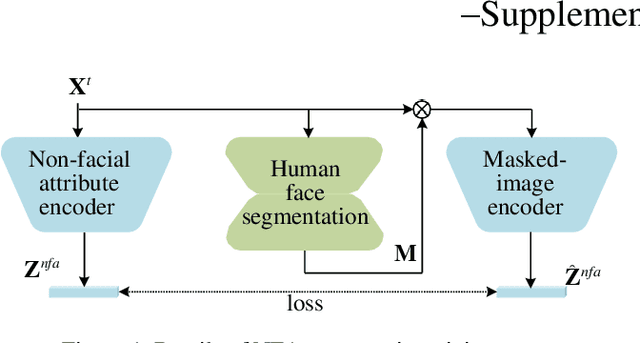

The SOTA face swap models still suffer the problem of either target identity (i.e., shape) being leaked or the target non-identity attributes (i.e., background, hair) failing to be fully preserved in the final results. We show that this insufficient disentanglement is caused by two flawed designs that were commonly adopted in prior models: (1) counting on only one compressed encoder to represent both the semantic-level non-identity facial attributes(i.e., pose) and the pixel-level non-facial region details, which is contradictory to satisfy at the same time; (2) highly relying on long skip-connections between the encoder and the final generator, leaking a certain amount of target face identity into the result. To fix them, we introduce a new face swap framework called 'WSC-swap' that gets rid of skip connections and uses two target encoders to respectively capture the pixel-level non-facial region attributes and the semantic non-identity attributes in the face region. To further reinforce the disentanglement learning for the target encoder, we employ both identity removal loss via adversarial training (i.e., GAN) and the non-identity preservation loss via prior 3DMM models like [11]. Extensive experiments on both FaceForensics++ and CelebA-HQ show that our results significantly outperform previous works on a rich set of metrics, including one novel metric for measuring identity consistency that was completely neglected before.
Visual Instruction Tuning with Polite Flamingo
Jul 03, 2023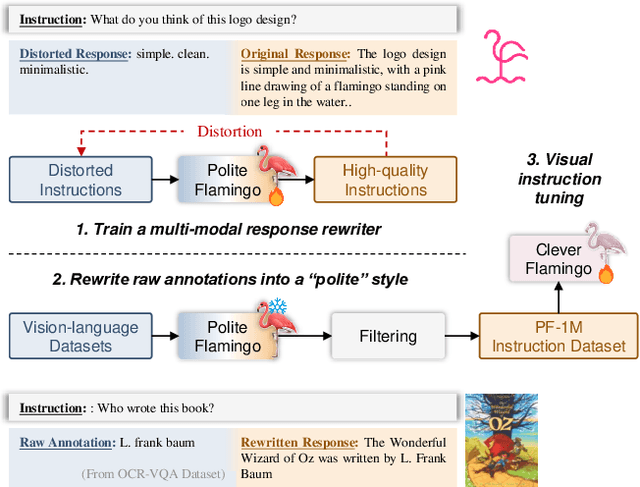
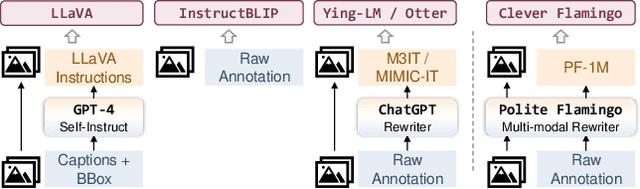
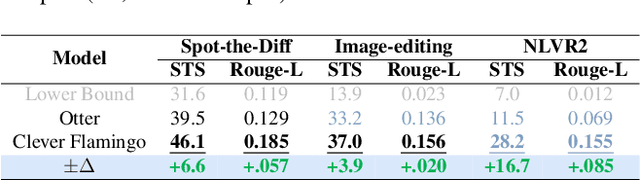
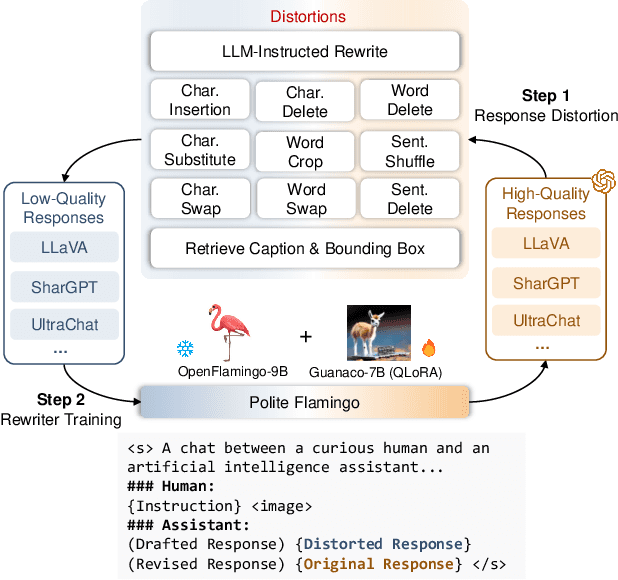
Recent research has demonstrated that the multi-task fine-tuning of multi-modal Large Language Models (LLMs) using an assortment of annotated downstream vision-language datasets significantly enhances their performance. Yet, during this process, a side effect, which we termed as the "multi-modal alignment tax", surfaces. This side effect negatively impacts the model's ability to format responses appropriately -- for instance, its "politeness" -- due to the overly succinct and unformatted nature of raw annotations, resulting in reduced human preference. In this paper, we introduce Polite Flamingo, a multi-modal response rewriter that transforms raw annotations into a more appealing, "polite" format. Polite Flamingo is trained to reconstruct high-quality responses from their automatically distorted counterparts and is subsequently applied to a vast array of vision-language datasets for response rewriting. After rigorous filtering, we generate the PF-1M dataset and further validate its value by fine-tuning a multi-modal LLM with it. Combined with novel methodologies including U-shaped multi-stage tuning and multi-turn augmentation, the resulting model, Clever Flamingo, demonstrates its advantages in both multi-modal understanding and response politeness according to automated and human evaluations.