 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA note on the lack of symmetry in the graphical lasso
Jul 23, 2012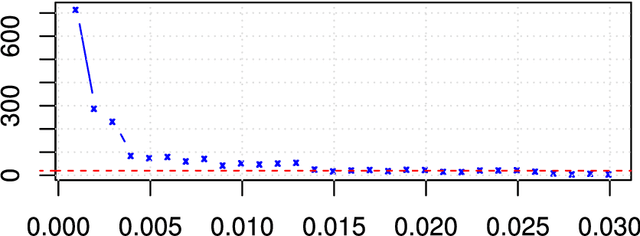

The graphical lasso (glasso) is a widely-used fast algorithm for estimating sparse inverse covariance matrices. The glasso solves an L1 penalized maximum likelihood problem and is available as an R library on CRAN. The output from the glasso, a regularized covariance matrix estimate a sparse inverse covariance matrix estimate, not only identify a graphical model but can also serve as intermediate inputs into multivariate procedures such as PCA, LDA, MANOVA, and others. The glasso indeed produces a covariance matrix estimate which solves the L1 penalized optimization problem in a dual sense; however, the method for producing the inverse covariance matrix estimator after this optimization is inexact and may produce asymmetric estimates. This problem is exacerbated when the amount of L1 regularization that is applied is small, which in turn is more likely to occur if the true underlying inverse covariance matrix is not sparse. The lack of symmetry can potentially have consequences. First, it implies that the covariance and inverse covariance estimates are not numerical inverses of one another, and second, asymmetry can possibly lead to negative or complex eigenvalues,rendering many multivariate procedures which may depend on the inverse covariance estimator unusable. We demonstrate this problem, explain its causes, and propose possible remedies.
Large Scale Correlation Screening
Jun 26, 2011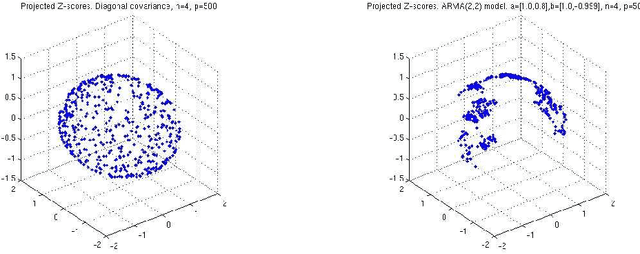

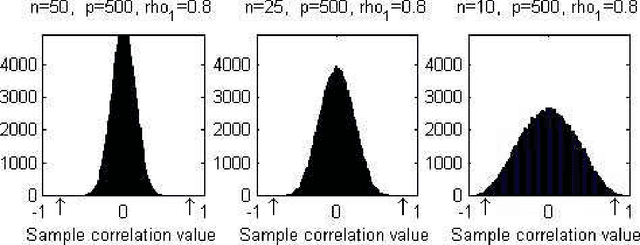
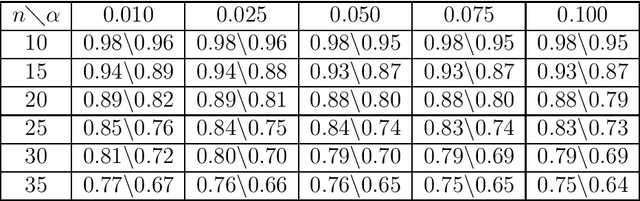
This paper treats the problem of screening for variables with high correlations in high dimensional data in which there can be many fewer samples than variables. We focus on threshold-based correlation screening methods for three related applications: screening for variables with large correlations within a single treatment (autocorrelation screening); screening for variables with large cross-correlations over two treatments (cross-correlation screening); screening for variables that have persistently large auto-correlations over two treatments (persistent-correlation screening). The novelty of correlation screening is that it identifies a smaller number of variables which are highly correlated with others, as compared to identifying a number of correlation parameters. Correlation screening suffers from a phase transition phenomenon: as the correlation threshold decreases the number of discoveries increases abruptly. We obtain asymptotic expressions for the mean number of discoveries and the phase transition thresholds as a function of the number of samples, the number of variables, and the joint sample distribution. We also show that under a weak dependency condition the number of discoveries is dominated by a Poisson random variable giving an asymptotic expression for the false positive rate. The correlation screening approach bears tremendous dividends in terms of the type and strength of the asymptotic results that can be obtained. It also overcomes some of the major hurdles faced by existing methods in the literature as correlation screening is naturally scalable to high dimension. Numerical results strongly validate the theory that is presented in this paper. We illustrate the application of the correlation screening methodology on a large scale gene-expression dataset, revealing a few influential variables that exhibit a significant amount of correlation over multiple treatments.