 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of LSTM and BERT for Small Corpus
Sep 11, 2020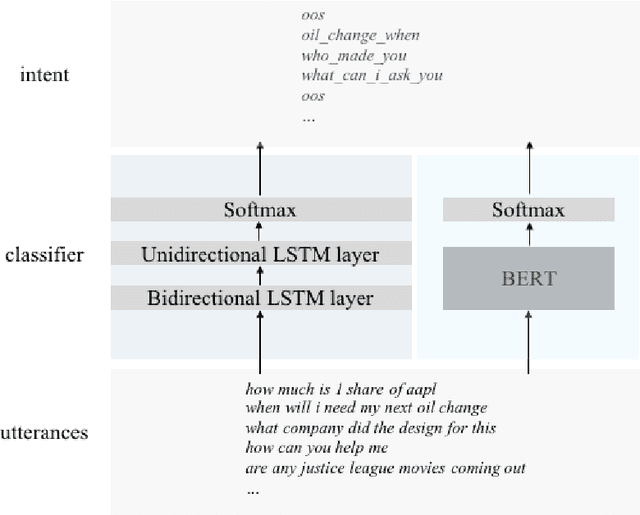
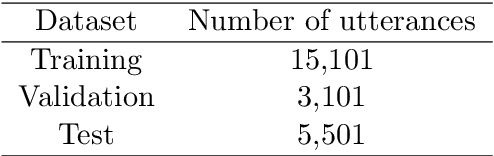
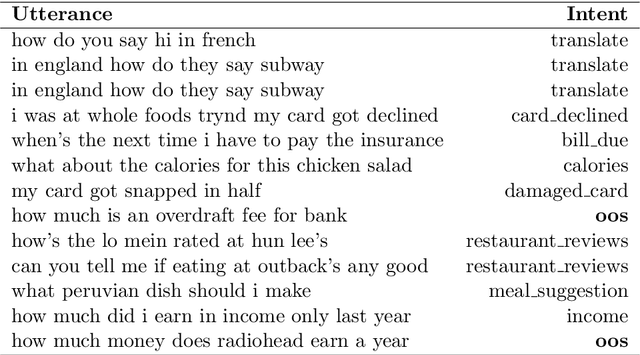
Recent advancements in the NLP field showed that transfer learning helps with achieving state-of-the-art results for new tasks by tuning pre-trained models instead of starting from scratch. Transformers have made a significant improvement in creating new state-of-the-art results for many NLP tasks including but not limited to text classification, text generation, and sequence labeling. Most of these success stories were based on large datasets. In this paper we focus on a real-life scenario that scientists in academia and industry face frequently: given a small dataset, can we use a large pre-trained model like BERT and get better results than simple models? To answer this question, we use a small dataset for intent classification collected for building chatbots and compare the performance of a simple bidirectional LSTM model with a pre-trained BERT model. Our experimental results show that bidirectional LSTM models can achieve significantly higher results than a BERT model for a small dataset and these simple models get trained in much less time than tuning the pre-trained counterparts. We conclude that the performance of a model is dependent on the task and the data, and therefore before making a model choice, these factors should be taken into consideration instead of directly choosing the most popular model.
ParkingSticker: A Real-World Object Detection Dataset
Feb 12, 2020
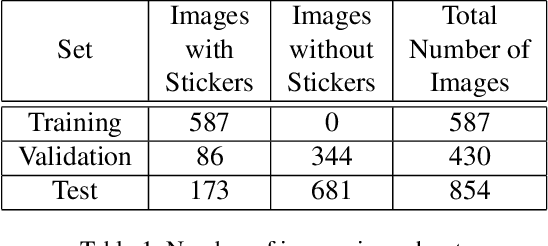

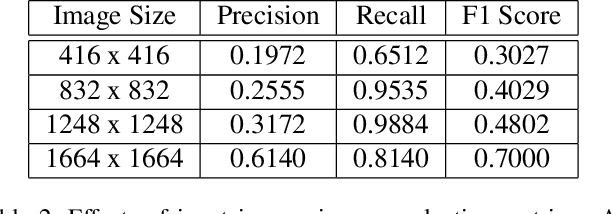
We present a new and challenging object detection dataset, ParkingSticker, which mimics the type of data available in industry problems more closely than popular existing datasets like PASCAL VOC. ParkingSticker contains 1,871 images that come from a security camera's video footage. The objective is to identify parking stickers on cars approaching a gate that the security camera faces. Bounding boxes are drawn around parking stickers in the images. The parking stickers are much smaller on average than the objects in other popular object detection datasets; this makes ParkingSticker a challenging test for object detection methods. This dataset also very realistically represents the data available in many industry problems where a customer presents a few video frames and asks for a solution to a very difficult problem. Performance of various object detection pipelines using a YOLOv2 architecture are presented and indicate that identifying the parking stickers in ParkingSticker is challenging yet feasible. We believe that this dataset will challenge researchers to solve a real-world problem with real-world constraints such as non-ideal camera positioning and small object-size-to-image-size ratios.
The Effect of Data Ordering in Image Classification
Jan 08, 2020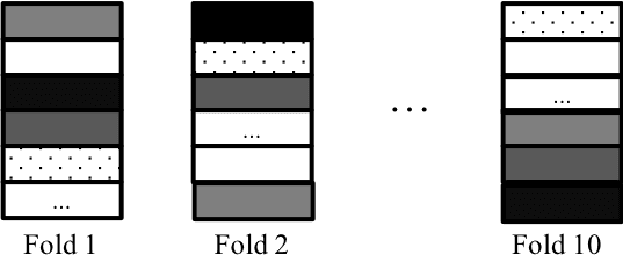

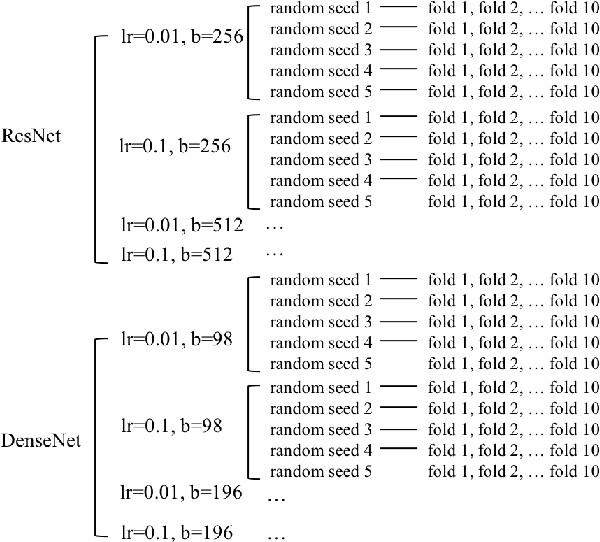
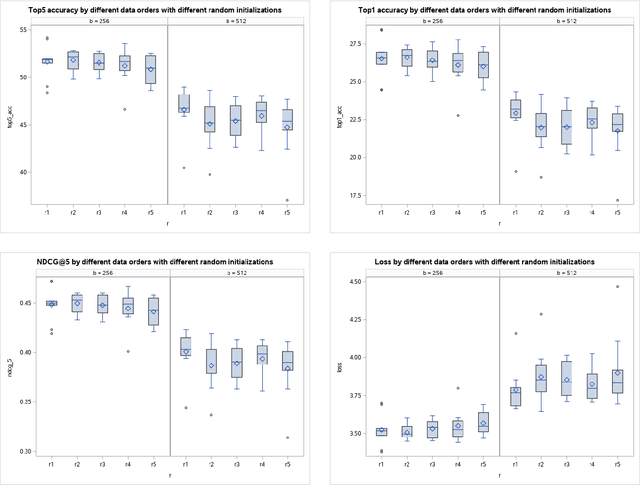
The success stories from deep learning models increase every day spanning different tasks from image classification to natural language understanding. With the increasing popularity of these models, scientists spend more and more time finding the optimal parameters and best model architectures for their tasks. In this paper, we focus on the ingredient that feeds these machines: the data. We hypothesize that the data ordering affects how well a model performs. To that end, we conduct experiments on an image classification task using ImageNet dataset and show that some data orderings are better than others in terms of obtaining higher classification accuracies. Experimental results show that independent of model architecture, learning rate and batch size, ordering of the data significantly affects the outcome. We show these findings using different metrics: NDCG, accuracy @ 1 and accuracy @ 5. Our goal here is to show that not only parameters and model architectures but also the data ordering has a say in obtaining better results.
Multilingual Sentiment Analysis: An RNN-Based Framework for Limited Data
Jun 08, 2018



Sentiment analysis is a widely studied NLP task where the goal is to determine opinions, emotions, and evaluations of users towards a product, an entity or a service that they are reviewing. One of the biggest challenges for sentiment analysis is that it is highly language dependent. Word embeddings, sentiment lexicons, and even annotated data are language specific. Further, optimizing models for each language is very time consuming and labor intensive especially for recurrent neural network models. From a resource perspective, it is very challenging to collect data for different languages. In this paper, we look for an answer to the following research question: can a sentiment analysis model trained on a language be reused for sentiment analysis in other languages, Russian, Spanish, Turkish, and Dutch, where the data is more limited? Our goal is to build a single model in the language with the largest dataset available for the task, and reuse it for languages that have limited resources. For this purpose, we train a sentiment analysis model using recurrent neural networks with reviews in English. We then translate reviews in other languages and reuse this model to evaluate the sentiments. Experimental results show that our robust approach of single model trained on English reviews statistically significantly outperforms the baselines in several different languages.