 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsli Celikyilmaz
Evaluation of Text Generation: A Survey
Jun 26, 2020

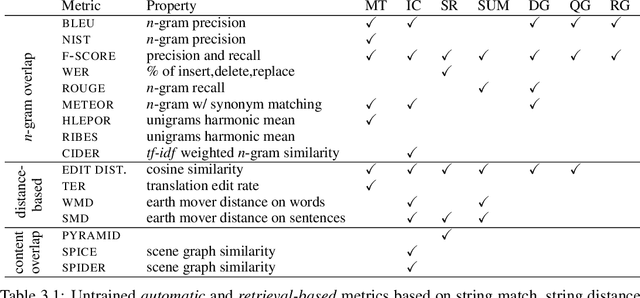
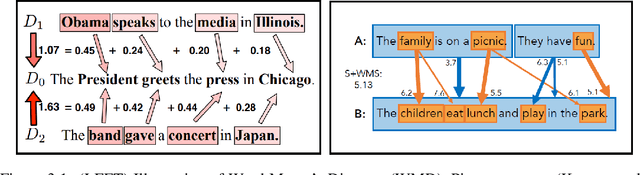
The paper surveys evaluation methods of natural language generation (NLG) systems that have been developed in the last few years. We group NLG evaluation methods into three categories: (1) human-centric evaluation metrics, (2) automatic metrics that require no training, and (3) machine-learned metrics. For each category, we discuss the progress that has been made and the challenges still being faced, with a focus on the evaluation of recently proposed NLG tasks and neural NLG models. We then present two case studies of automatic text summarization and long text generation, and conclude the paper by proposing future research directions.
Reparameterized Variational Divergence Minimization for Stable Imitation
Jun 18, 2020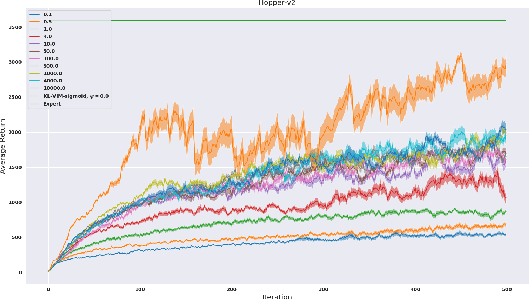

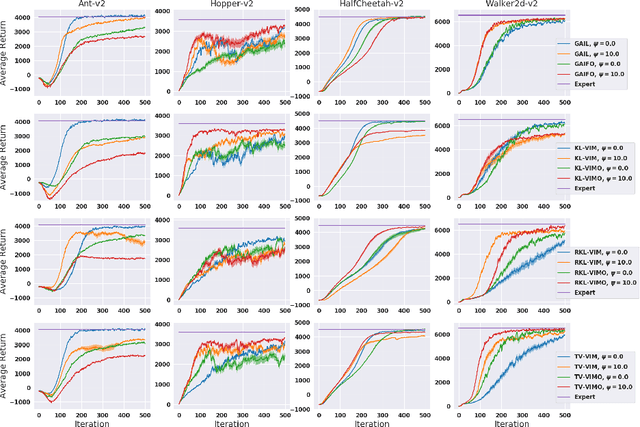
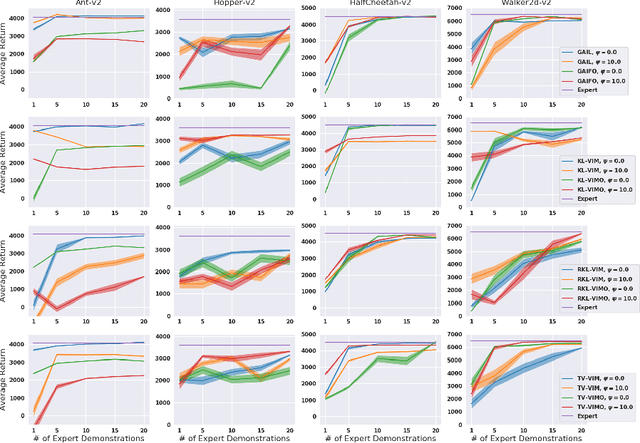
While recent state-of-the-art results for adversarial imitation-learning algorithms are encouraging, recent works exploring the imitation learning from observation (ILO) setting, where trajectories \textit{only} contain expert observations, have not been met with the same success. Inspired by recent investigations of $f$-divergence manipulation for the standard imitation learning setting(Ke et al., 2019; Ghasemipour et al., 2019), we here examine the extent to which variations in the choice of probabilistic divergence may yield more performant ILO algorithms. We unfortunately find that $f$-divergence minimization through reinforcement learning is susceptible to numerical instabilities. We contribute a reparameterization trick for adversarial imitation learning to alleviate the optimization challenges of the promising $f$-divergence minimization framework. Empirically, we demonstrate that our design choices allow for ILO algorithms that outperform baseline approaches and more closely match expert performance in low-dimensional continuous-control tasks.
A Recipe for Creating Multimodal Aligned Datasets for Sequential Tasks
May 19, 2020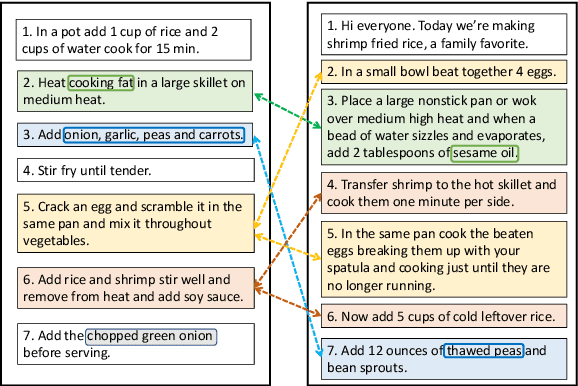
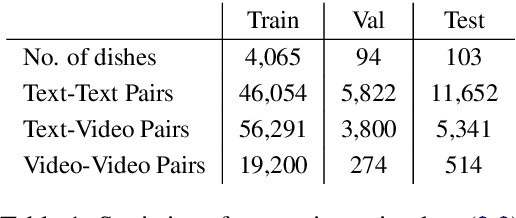
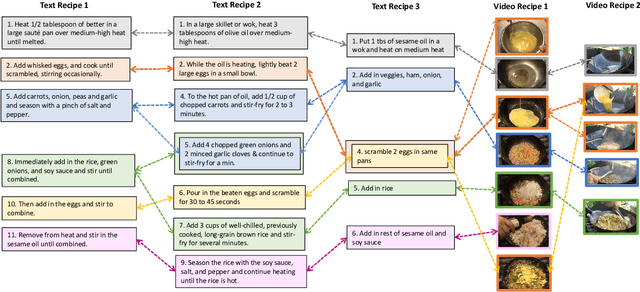
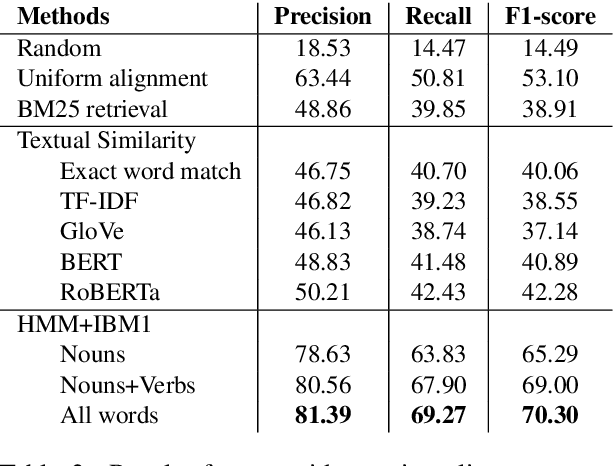
Many high-level procedural tasks can be decomposed into sequences of instructions that vary in their order and choice of tools. In the cooking domain, the web offers many partially-overlapping text and video recipes (i.e. procedures) that describe how to make the same dish (i.e. high-level task). Aligning instructions for the same dish across different sources can yield descriptive visual explanations that are far richer semantically than conventional textual instructions, providing commonsense insight into how real-world procedures are structured. Learning to align these different instruction sets is challenging because: a) different recipes vary in their order of instructions and use of ingredients; and b) video instructions can be noisy and tend to contain far more information than text instructions. To address these challenges, we first use an unsupervised alignment algorithm that learns pairwise alignments between instructions of different recipes for the same dish. We then use a graph algorithm to derive a joint alignment between multiple text and multiple video recipes for the same dish. We release the Microsoft Research Multimodal Aligned Recipe Corpus containing 150K pairwise alignments between recipes across 4,262 dishes with rich commonsense information.
* This paper has been accepted to be published at ACL 2020
Artemis: A Novel Annotation Methodology for Indicative Single Document Summarization
May 14, 2020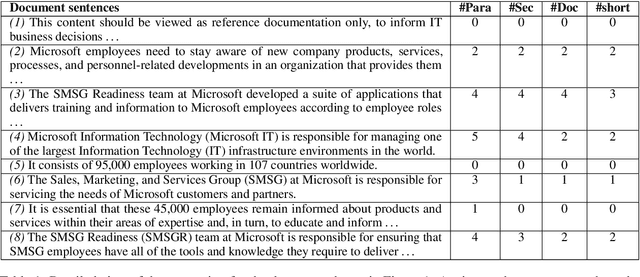
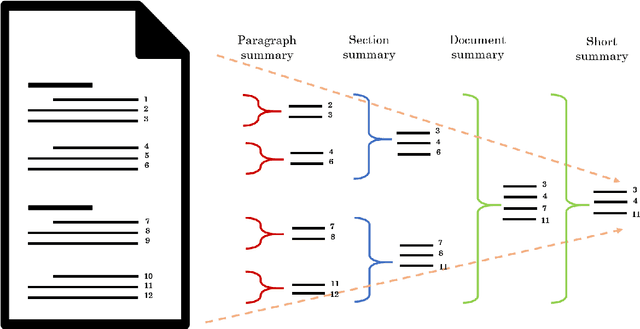
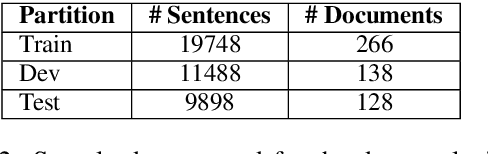

We describe Artemis (Annotation methodology for Rich, Tractable, Extractive, Multi-domain, Indicative Summarization), a novel hierarchical annotation process that produces indicative summaries for documents from multiple domains. Current summarization evaluation datasets are single-domain and focused on a few domains for which naturally occurring summaries can be easily found, such as news and scientific articles. These are not sufficient for training and evaluation of summarization models for use in document management and information retrieval systems, which need to deal with documents from multiple domains. Compared to other annotation methods such as Relative Utility and Pyramid, Artemis is more tractable because judges don't need to look at all the sentences in a document when making an importance judgment for one of the sentences, while providing similarly rich sentence importance annotations. We describe the annotation process in detail and compare it with other similar evaluation systems. We also present analysis and experimental results over a sample set of 532 annotated documents.
RMM: A Recursive Mental Model for Dialog Navigation
May 02, 2020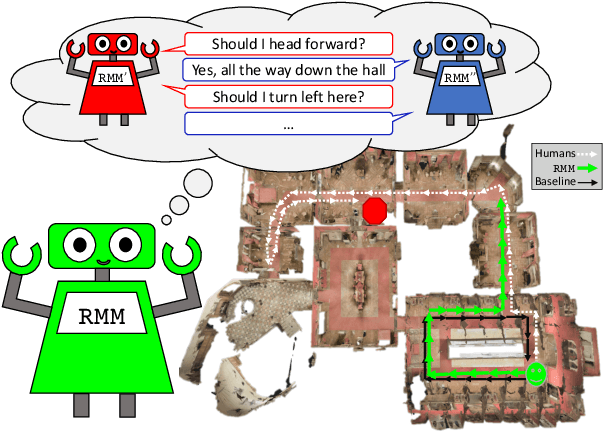
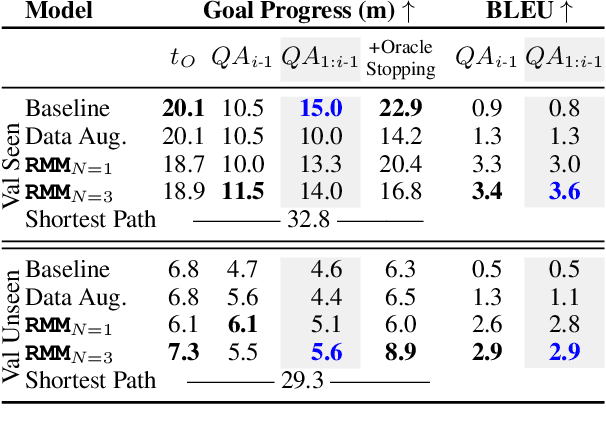
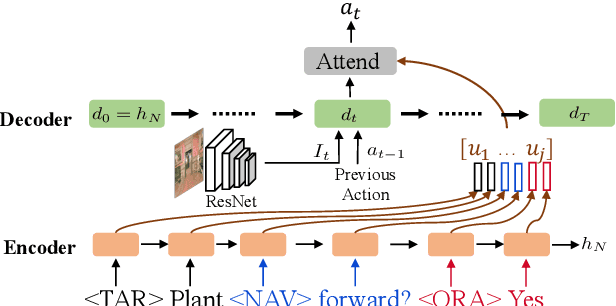

Fluent communication requires understanding your audience. In the new collaborative task of Vision-and-Dialog Navigation, one agent must ask questions and follow instructive answers, while the other must provide those answers. We introduce the first true dialog navigation agents in the literature which generate full conversations, and introduce the Recursive Mental Model (RMM) to conduct these dialogs. RMM dramatically improves generated language questions and answers by recursively propagating reward signals to find the question expected to elicit the best answer, and the answer expected to elicit the best navigation. Additionally, we provide baselines for future work to build on when investigating the unique challenges of embodied visual agents that not only interpret instructions but also ask questions in natural language.
PlotMachines: Outline-Conditioned Generation with Dynamic Plot State Tracking
Apr 30, 2020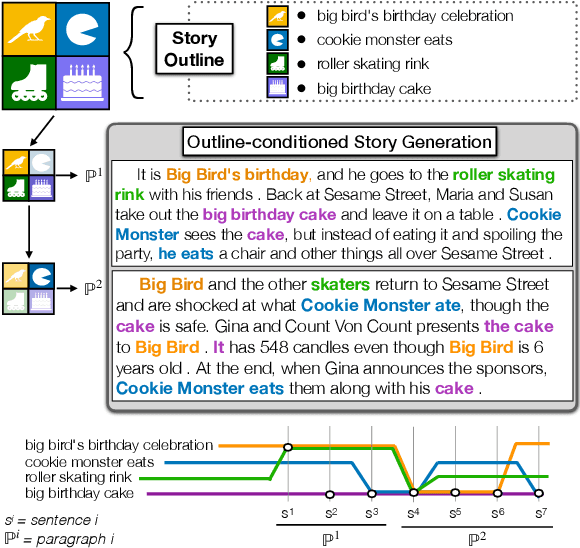

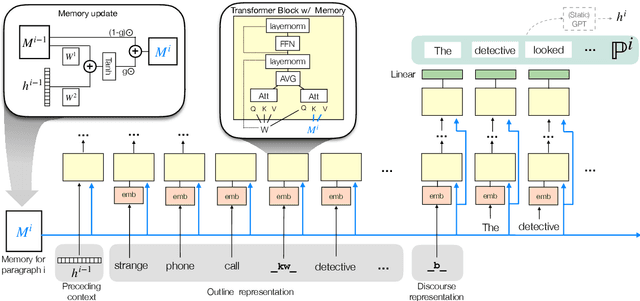
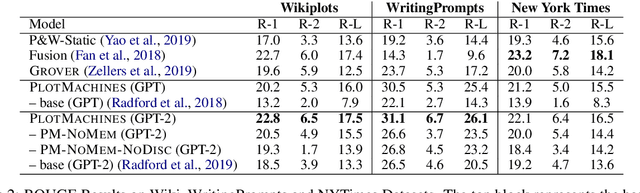
We propose the task of outline-conditioned story generation: given an outline as a set of phrases that describe key characters and events to appear in a story, the task is to generate a coherent narrative that is consistent with the provided outline. This task is challenging as the input only provides a rough sketch of the plot, and thus, models need to generate a story by weaving through the key points provided in the outline. This requires the model to keep track of the dynamic states of the latent plot, conditioning on the input outline while generating the full story. We present PlotMachines, a neural narrative model that learns to transform an outline into a coherent story by tracking the dynamic plot states. In addition, we enrich PlotMachines with high-level discourse structure so that the model can learn different styles of writing corresponding to different parts of the narrative. Comprehensive experiments over three fiction and non-fiction datasets demonstrate that recently introduced large-scale language models, such as GPT-2 and Grover, despite their impressive generation performance, are not sufficient in generating coherent narratives for the given outline, and dynamic plot state tracking is important for composing narratives with tighter, more consistent plots.
AREDSUM: Adaptive Redundancy-Aware Iterative Sentence Ranking for Extractive Document Summarization
Apr 13, 2020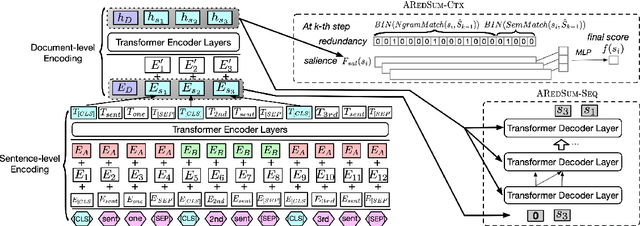
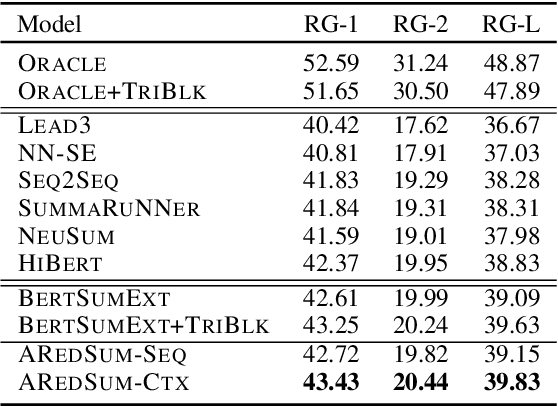
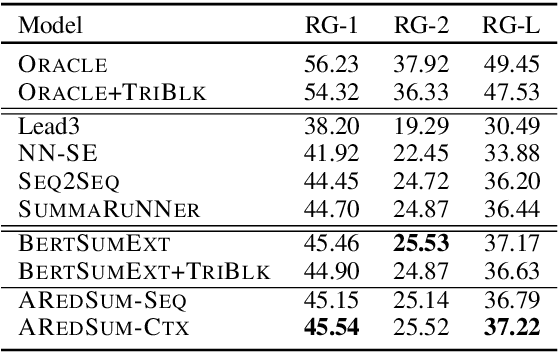
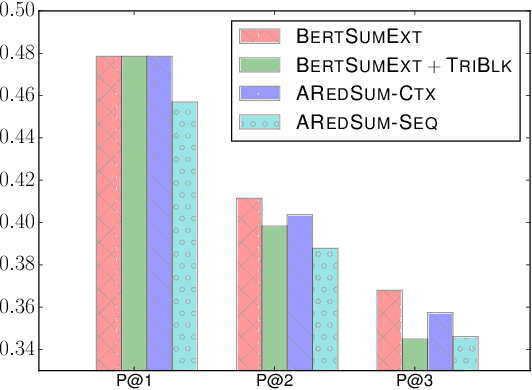
Redundancy-aware extractive summarization systems score the redundancy of the sentences to be included in a summary either jointly with their salience information or separately as an additional sentence scoring step. Previous work shows the efficacy of jointly scoring and selecting sentences with neural sequence generation models. It is, however, not well-understood if the gain is due to better encoding techniques or better redundancy reduction approaches. Similarly, the contribution of salience versus diversity components on the created summary is not studied well. Building on the state-of-the-art encoding methods for summarization, we present two adaptive learning models: AREDSUM-SEQ that jointly considers salience and novelty during sentence selection; and a two-step AREDSUM-CTX that scores salience first, then learns to balance salience and redundancy, enabling the measurement of the impact of each aspect. Empirical results on CNN/DailyMail and NYT50 datasets show that by modeling diversity explicitly in a separate step, AREDSUM-CTX achieves significantly better performance than AREDSUM-SEQ as well as state-of-the-art extractive summarization baselines.
Working Memory Graphs
Nov 17, 2019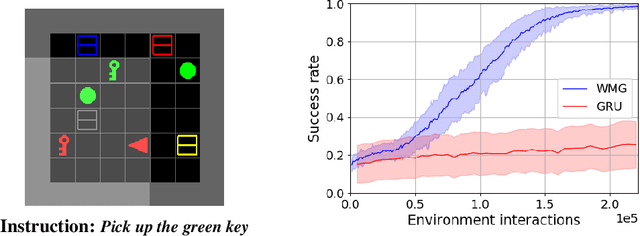
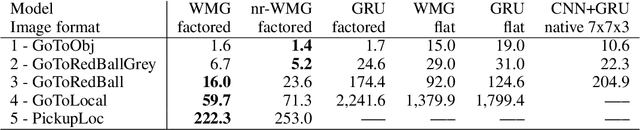
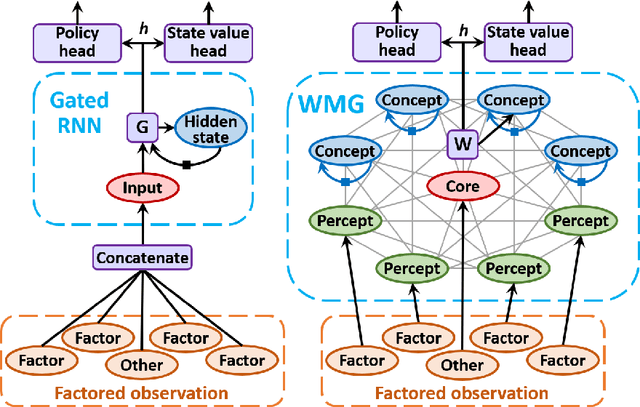
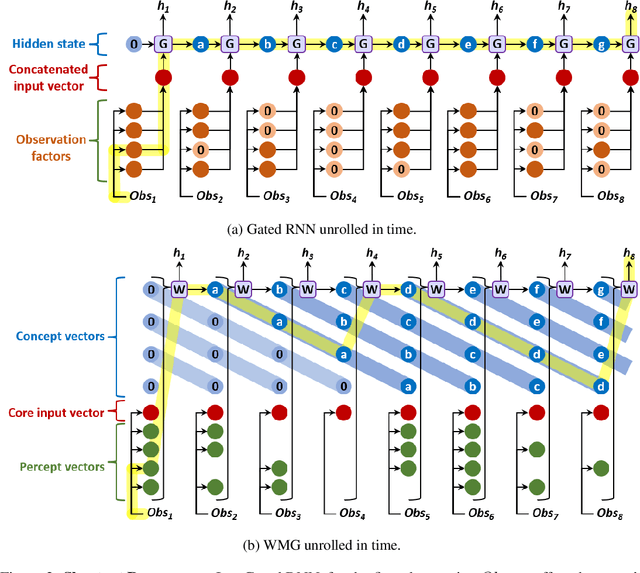
Transformers have increasingly outperformed gated RNNs in obtaining new state-of-the-art results on supervised tasks involving text sequences. Inspired by this trend, we study the question of how Transformer-based models can improve the performance of sequential decision-making agents. We present the Working Memory Graph (WMG), an agent that employs multi-head self-attention to reason over a dynamic set of vectors representing observed and recurrent state. We evaluate WMG in two partially observable environments, one that requires complex reasoning over past observations, and another that features factored observations. We find that WMG significantly outperforms gated RNNs on these tasks, supporting the hypothesis that WMG's inductive bias in favor of learning and leveraging factored representations can dramatically boost sample efficiency in environments featuring such structure.
Unsupervised Common Question Generation from Multiple Documents using Reinforced Contrastive Coordinator
Nov 08, 2019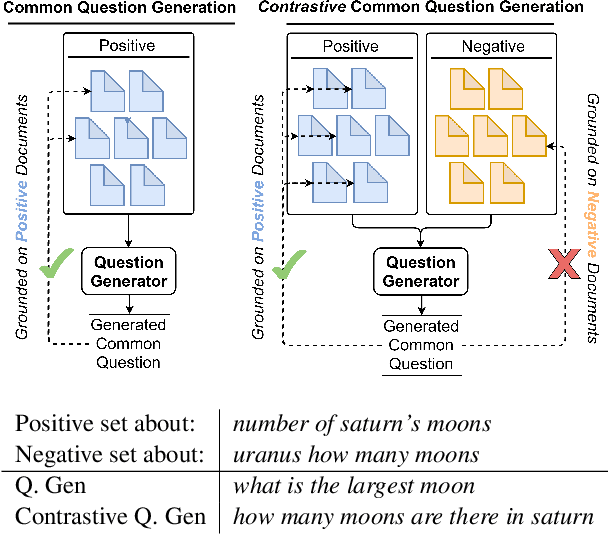
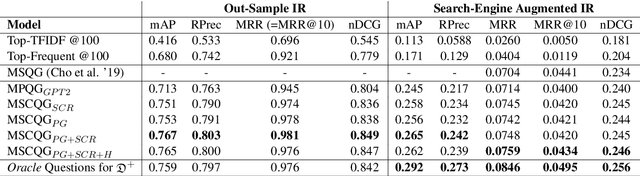
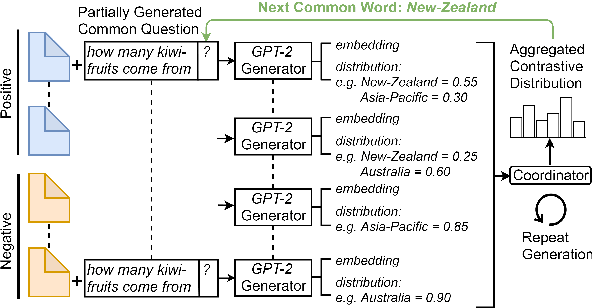
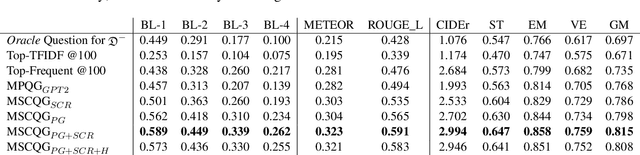
Web search engines today return a ranked list of document links in response to a user's query. However, when a user query is vague, the resultant documents span multiple subtopics. In such a scenario, it would be helpful if the search engine provided clarification options to the user's initial query in a way that each clarification option is closely related to the documents in one subtopic and is far away from the documents in all other subtopics. Motivated by this scenario, we address the task of contrastive common question generation where given a "positive" set of documents and a "negative" set of documents, we generate a question that is closely related to the "positive" set and is far away from the "negative" set. We propose Multi-Source Coordinated Question Generator (MSCQG), a novel coordinator model trained using reinforcement learning to optimize a reward based on document-question ranker score. We also develop an effective auxiliary objective, named Set-induced Contrastive Regularization (SCR) that draws the coordinator's generation behavior more closely toward "positive" documents and away from "negative" documents. We show that our model significantly outperforms strong retrieval baselines as well as a baseline model developed for a similar task, as measured by various metrics.