 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArjan Kuijper
ElasticFace: Elastic Margin Loss for Deep Face Recognition
Sep 22, 2021
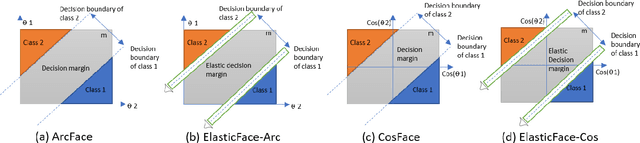
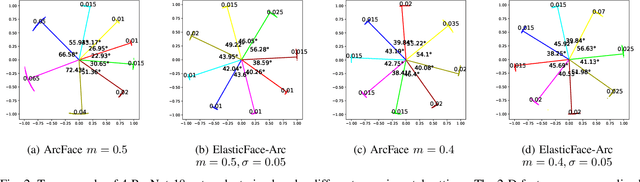
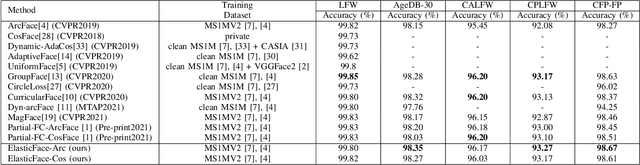
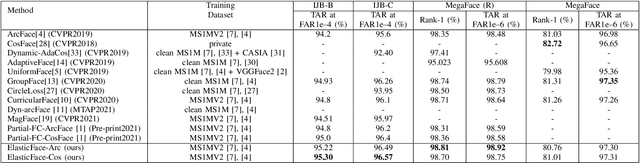
Learning discriminative face features plays a major role in building high-performing face recognition models. The recent state-of-the-art face recognition solutions proposed to incorporate a fixed penalty margin on commonly used classification loss function, softmax loss, in the normalized hypersphere to increase the discriminative power of face recognition models, by minimizing the intra-class variation and maximizing the inter-class variation. Marginal softmax losses, such as ArcFace and CosFace, assume that the geodesic distance between and within the different identities can be equally learned using a fixed margin. However, such a learning objective is not realistic for real data with inconsistent inter-and intra-class variation, which might limit the discriminative and generalizability of the face recognition model. In this paper, we relax the fixed margin constrain by proposing elastic margin loss (ElasticFace) that allows flexibility in the push for class separability. The main idea is to utilize random margin values drawn from a normal distribution in each training iteration. This aims at giving the margin chances to extract and retract to allow space for flexible class separability learning. We demonstrate the superiority of our elastic margin loss over ArcFace and CosFace losses, using the same geometric transformation, on a large set of mainstream benchmarks. From a wider perspective, our ElasticFace has advanced the state-of-the-art face recognition performance on six out of nine mainstream benchmarks.
Learnable Multi-level Frequency Decomposition and Hierarchical Attention Mechanism for Generalized Face Presentation Attack Detection
Sep 16, 2021
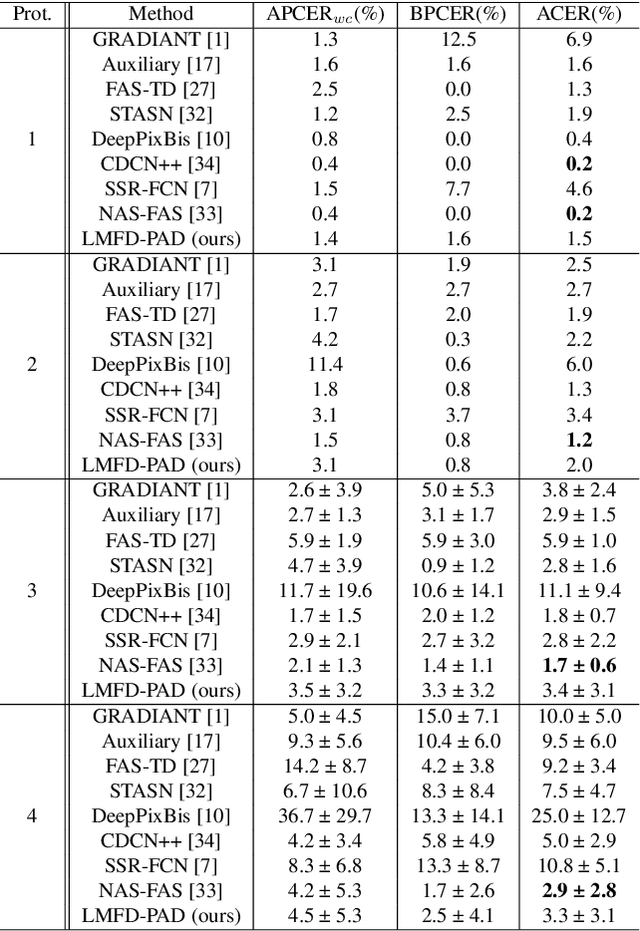
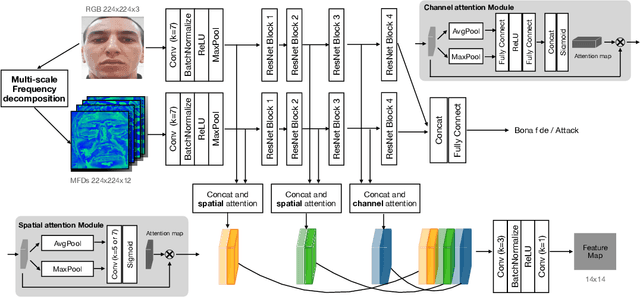
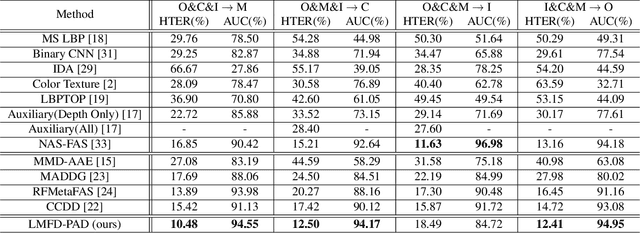
With the increased deployment of face recognition systems in our daily lives, face presentation attack detection (PAD) is attracting a lot of attention and playing a key role in securing face recognition systems. Despite the great performance achieved by the hand-crafted and deep learning based methods in intra-dataset evaluations, the performance drops when dealing with unseen scenarios. In this work, we propose a dual-stream convolution neural networks (CNNs) framework. One stream adapts four learnable frequency filters to learn features in the frequency domain, which are less influenced variations in sensors/illuminations. The other stream leverage the RGB images to complement the features of the frequency domain. Moreover, we propose a hierarchical attention module integration to join the information from the two streams at different stages by considering the nature of deep features in different layers of the CNN. The proposed method is evaluated in the intra-dataset and cross-dataset setups and the results demonstrates that our proposed approach enhances the generalizability in most experimental setups in comparison to state-of-the-art, including the methods designed explicitly for domain adaption/shift problem. We successfully prove the design of our proposed PAD solution in a step-wise ablation study that involves our proposed learnable frequency decomposition, our hierarchical attention module design, and the used loss function. Training codes and pre-trained models are publicly released.
PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and Multi-Step Knowledge Distillation
Aug 24, 2021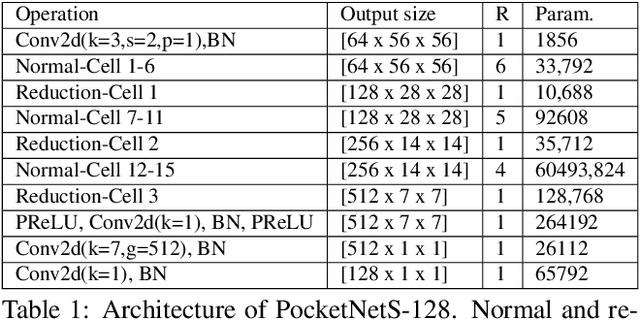
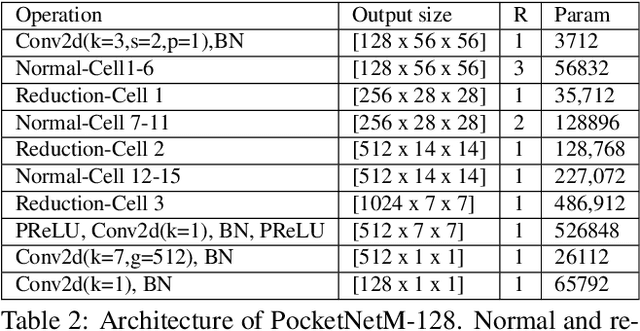
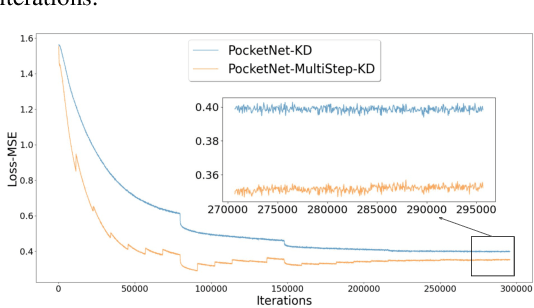
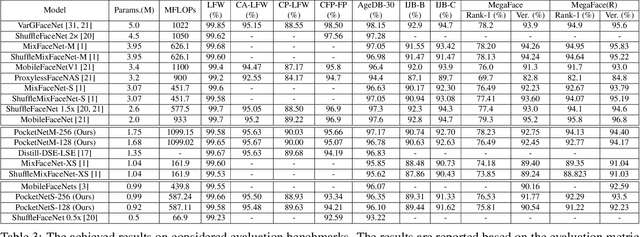
Deep neural networks have rapidly become the mainstream method for face recognition. However, deploying such models that contain an extremely large number of parameters to embedded devices or in application scenarios with limited memory footprint is challenging. In this work, we present an extremely lightweight and accurate face recognition solution. We utilize neural architecture search to develop a new family of face recognition models, namely PocketNet. We also propose to enhance the verification performance of the compact model by presenting a novel training paradigm based on knowledge distillation, namely the multi-step knowledge distillation. We present an extensive experimental evaluation and comparisons with the recent compact face recognition models on nine different benchmarks including large-scale evaluation benchmarks such as IJB-B, IJB-C, and MegaFace. PocketNets have consistently advanced the state-of-the-art (SOTA) face recognition performance on nine mainstream benchmarks when considering the same level of model compactness. With 0.92M parameters, our smallest network PocketNetS-128 achieved very competitive results to recent SOTA compacted models that contain more than 4M parameters. Training codes and pre-trained models are publicly released https://github.com/fdbtrs/PocketNet.
PW-MAD: Pixel-wise Supervision for Generalized Face Morphing Attack Detection
Aug 23, 2021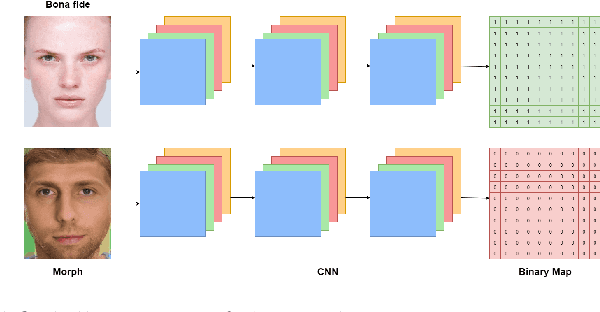
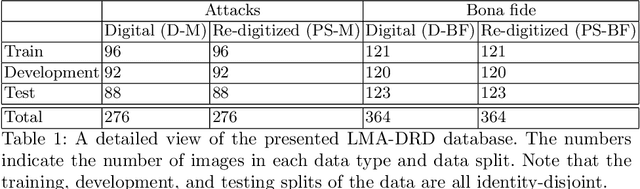
A face morphing attack image can be verified to multiple identities, making this attack a major vulnerability to processes based on identity verification, such as border checks. Different methods have been proposed to detect face morphing attacks, however, with low generalizability to unexpected post-morphing processes. A major post-morphing process is the print and scan operation performed in many countries when issuing a passport or identity document. In this work, we address this generalization problem by adapting a pixel-wise supervision approach where we train a network to classify each pixel of the image into an attack or not during the training process, rather than only having one label for the whole image. Our pixel-wise morphing attack detection (PW-MAD) solution performs more accurately than a set of established baselines. More importantly, our approach shows high generalizability in comparison to related works, when evaluated on unknown re-digitized attacks. Additionally to our PW-MAD approach, we create a new face morphing attack dataset with digital and re-digitized attacks and bona fide samples, namely the LMA-DRD dataset that will be made publicly available for research purposes.
ReGenMorph: Visibly Realistic GAN Generated Face Morphing Attacks by Attack Re-generation
Aug 20, 2021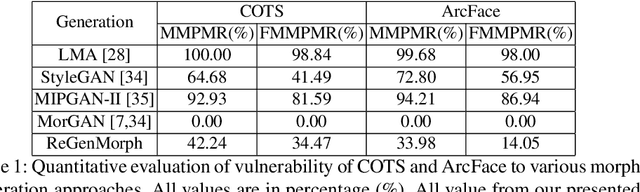
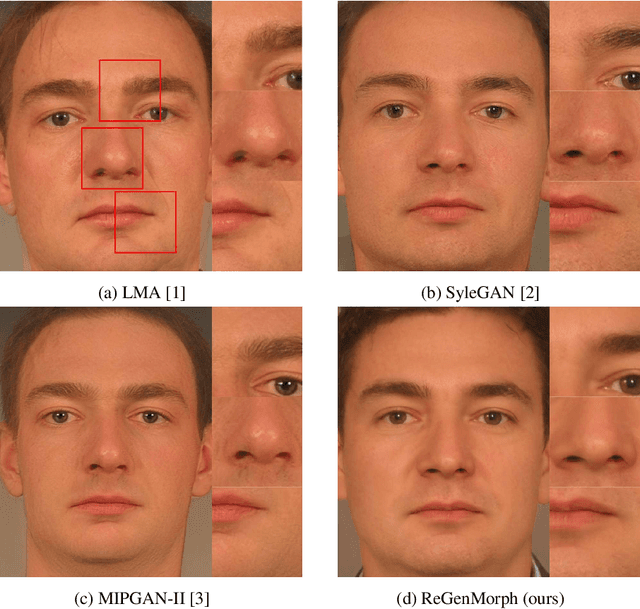
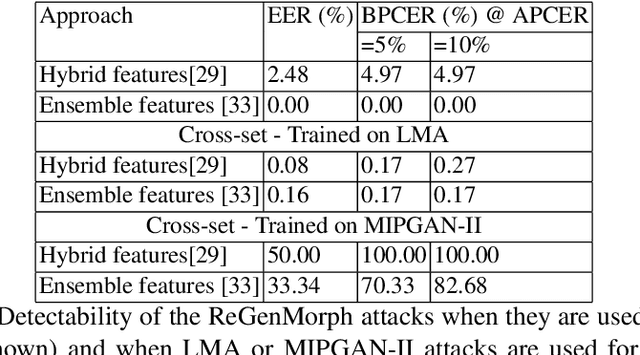
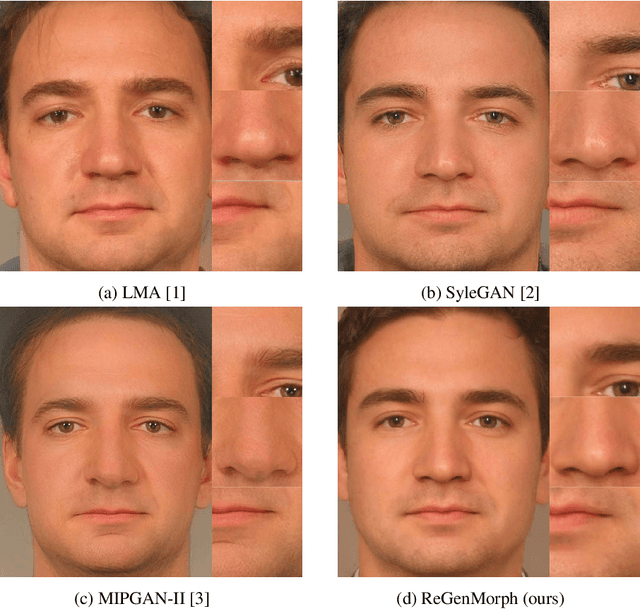
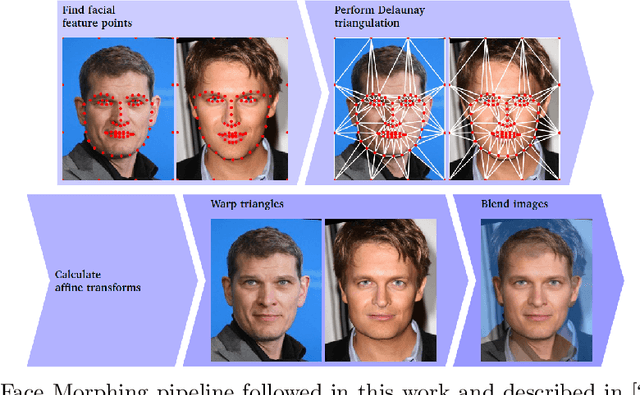
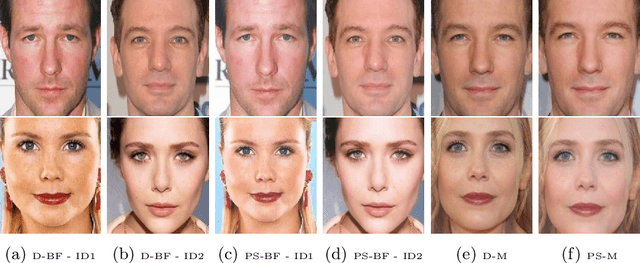
Face morphing attacks aim at creating face images that are verifiable to be the face of multiple identities, which can lead to building faulty identity links in operations like border checks. While creating a morphed face detector (MFD), training on all possible attack types is essential to achieve good detection performance. Therefore, investigating new methods of creating morphing attacks drives the generalizability of MADs. Creating morphing attacks was performed on the image level, by landmark interpolation, or on the latent-space level, by manipulating latent vectors in a generative adversarial network. The earlier results in varying blending artifacts and the latter results in synthetic-like striping artifacts. This work presents the novel morphing pipeline, ReGenMorph, to eliminate the LMA blending artifacts by using a GAN-based generation, as well as, eliminate the manipulation in the latent space, resulting in visibly realistic morphed images compared to previous works. The generated ReGenMorph appearance is compared to recent morphing approaches and evaluated for face recognition vulnerability and attack detectability, whether as known or unknown attacks.
MixFaceNets: Extremely Efficient Face Recognition Networks
Jul 27, 2021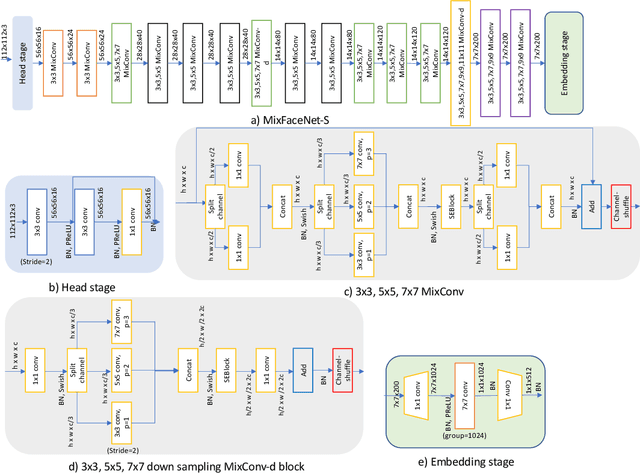
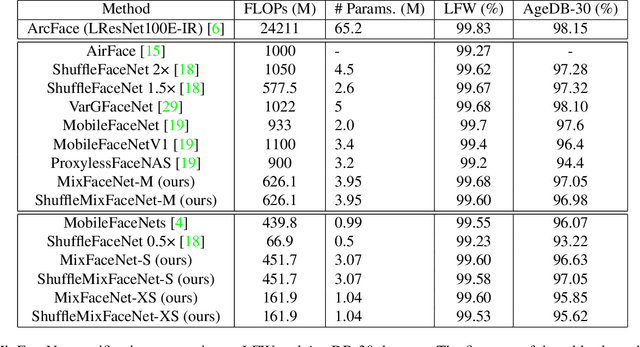
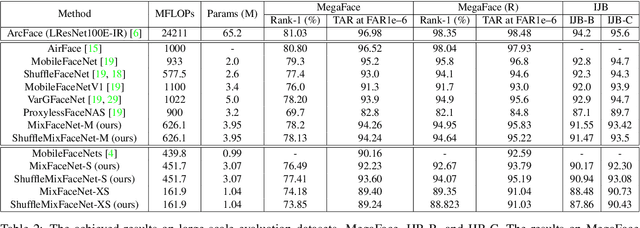
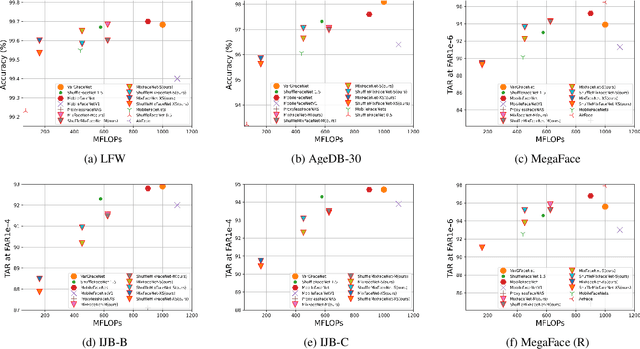
In this paper, we present a set of extremely efficient and high throughput models for accurate face verification, MixFaceNets which are inspired by Mixed Depthwise Convolutional Kernels. Extensive experiment evaluations on Label Face in the Wild (LFW), Age-DB, MegaFace, and IARPA Janus Benchmarks IJB-B and IJB-C datasets have shown the effectiveness of our MixFaceNets for applications requiring extremely low computational complexity. Under the same level of computation complexity (< 500M FLOPs), our MixFaceNets outperform MobileFaceNets on all the evaluated datasets, achieving 99.60% accuracy on LFW, 97.05% accuracy on AgeDB-30, 93.60 TAR (at FAR1e-6) on MegaFace, 90.94 TAR (at FAR1e-4) on IJB-B and 93.08 TAR (at FAR1e-4) on IJB-C. With computational complexity between 500M and 1G FLOPs, our MixFaceNets achieved results comparable to the top-ranked models, while using significantly fewer FLOPs and less computation overhead, which proves the practical value of our proposed MixFaceNets. All training codes, pre-trained models, and training logs have been made available https://github.com/fdbtrs/mixfacenets.
MFR 2021: Masked Face Recognition Competition
Jun 29, 2021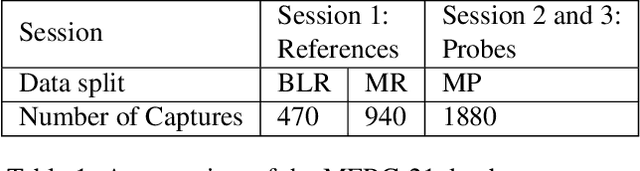

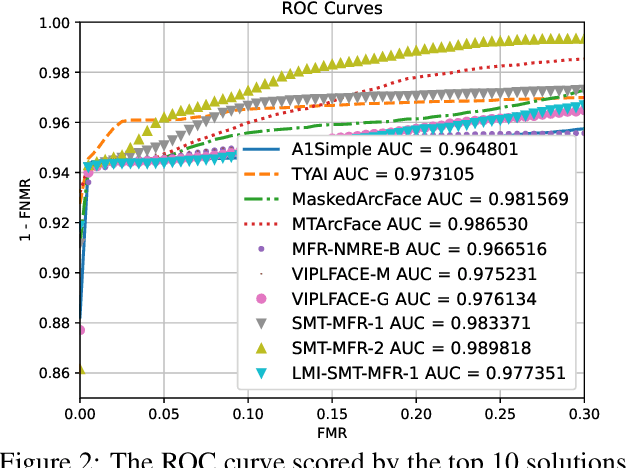
This paper presents a summary of the Masked Face Recognition Competitions (MFR) held within the 2021 International Joint Conference on Biometrics (IJCB 2021). The competition attracted a total of 10 participating teams with valid submissions. The affiliations of these teams are diverse and associated with academia and industry in nine different countries. These teams successfully submitted 18 valid solutions. The competition is designed to motivate solutions aiming at enhancing the face recognition accuracy of masked faces. Moreover, the competition considered the deployability of the proposed solutions by taking the compactness of the face recognition models into account. A private dataset representing a collaborative, multi-session, real masked, capture scenario is used to evaluate the submitted solutions. In comparison to one of the top-performing academic face recognition solutions, 10 out of the 18 submitted solutions did score higher masked face verification accuracy.
Iris Presentation Attack Detection by Attention-based and Deep Pixel-wise Binary Supervision Network
Jun 28, 2021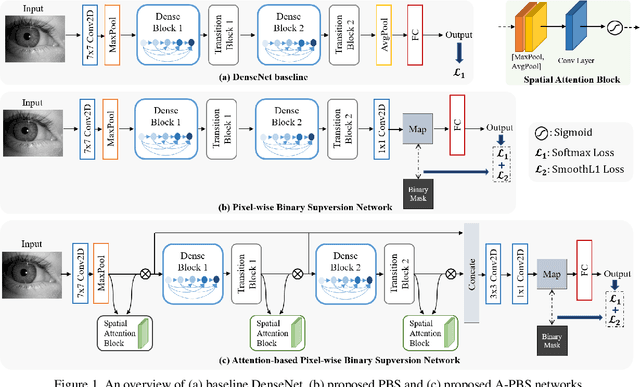
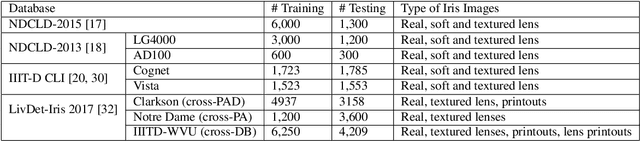
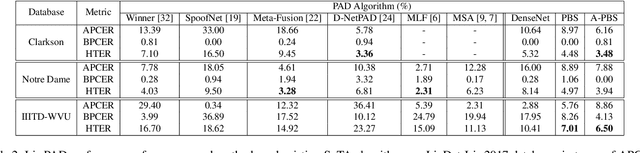
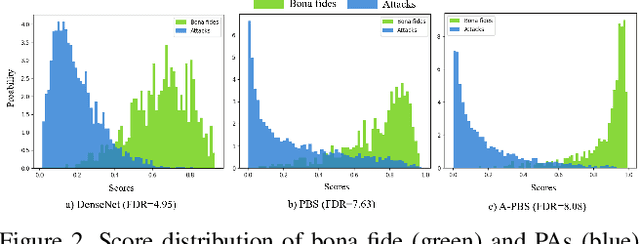
Iris presentation attack detection (PAD) plays a vital role in iris recognition systems. Most existing CNN-based iris PAD solutions 1) perform only binary label supervision during the training of CNNs, serving global information learning but weakening the capture of local discriminative features, 2) prefer the stacked deeper convolutions or expert-designed networks, raising the risk of overfitting, 3) fuse multiple PAD systems or various types of features, increasing difficulty for deployment on mobile devices. Hence, we propose a novel attention-based deep pixel-wise binary supervision (A-PBS) method. Pixel-wise supervision is first able to capture the fine-grained pixel/patch-level cues. Then, the attention mechanism guides the network to automatically find regions that most contribute to an accurate PAD decision. Extensive experiments are performed on LivDet-Iris 2017 and three other publicly available databases to show the effectiveness and robustness of proposed A-PBS methods. For instance, the A-PBS model achieves an HTER of 6.50% on the IIITD-WVU database outperforming state-of-the-art methods.
MiDeCon: Unsupervised and Accurate Fingerprint and Minutia Quality Assessment based on Minutia Detection Confidence
Jun 10, 2021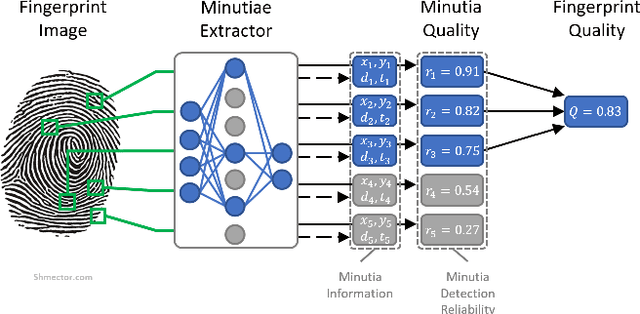
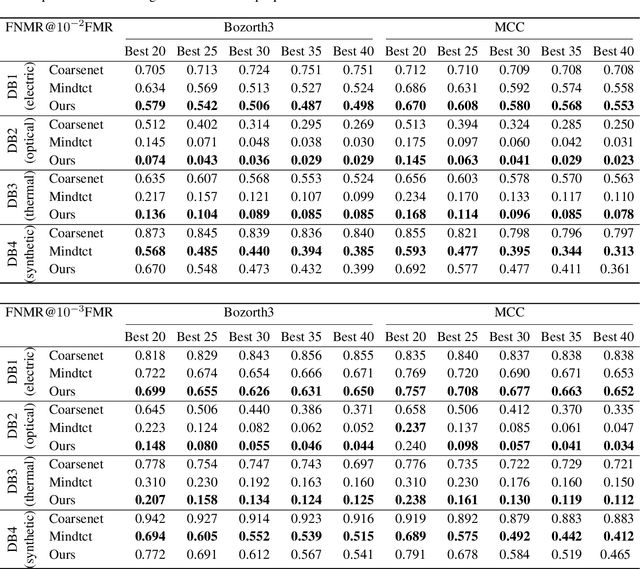
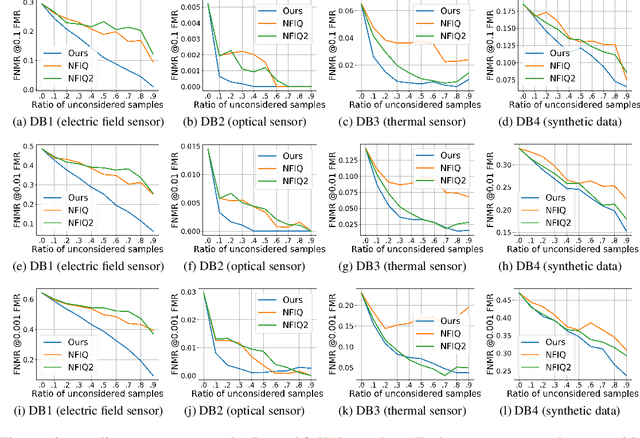
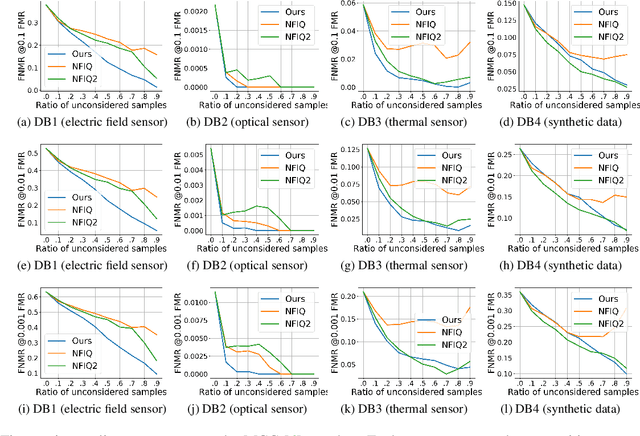
An essential factor to achieve high accuracies in fingerprint recognition systems is the quality of its samples. Previous works mainly proposed supervised solutions based on image properties that neglects the minutiae extraction process, despite that most fingerprint recognition techniques are based on detected minutiae. Consequently, a fingerprint image might be assigned a high quality even if the utilized minutia extractor produces unreliable information. In this work, we propose a novel concept of assessing minutia and fingerprint quality based on minutia detection confidence (MiDeCon). MiDeCon can be applied to an arbitrary deep learning based minutia extractor and does not require quality labels for learning. We propose using the detection reliability of the extracted minutia as its quality indicator. By combining the highest minutia qualities, MiDeCon also accurately determines the quality of a full fingerprint. Experiments are conducted on the publicly available databases of the FVC 2006 and compared against several baselines, such as NIST's widely-used fingerprint image quality software NFIQ1 and NFIQ2. The results demonstrate a significantly stronger quality assessment performance of the proposed MiDeCon-qualities as related works on both, minutia- and fingerprint-level. The implementation is publicly available.
Masked Face Recognition: Human vs. Machine
Mar 02, 2021
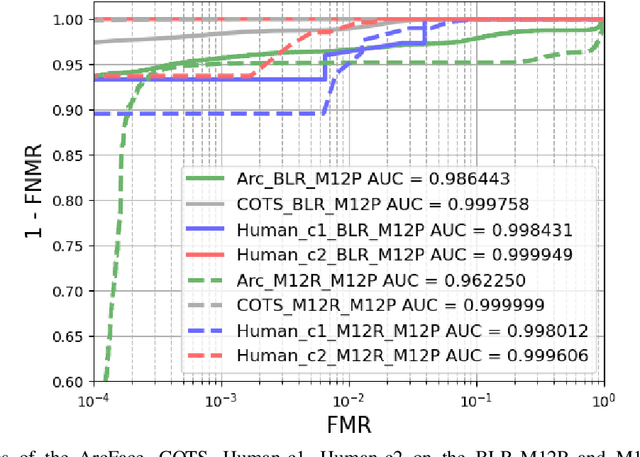
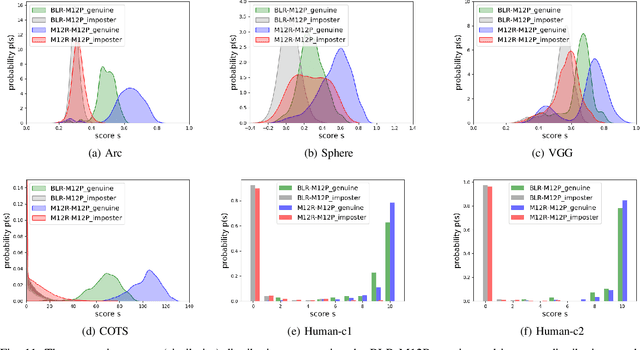
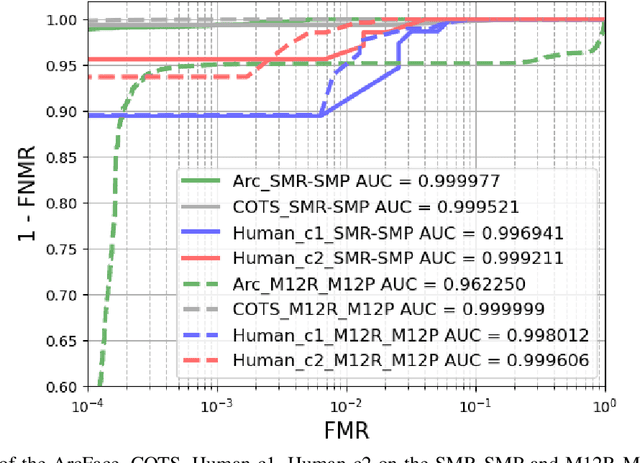
The recent COVID-19 pandemic has increased the focus on hygienic and contactless identity verification methods. However, the pandemic led to the wide use of face masks, essential to keep the pandemic under control. The effect of wearing a mask on face recognition in a collaborative environment is currently sensitive yet understudied issue. Recent reports have tackled this by evaluating the masked probe effect on the performance of automatic face recognition solutions. However, such solutions can fail in certain processes, leading to performing the verification task by a human expert. This work provides a joint evaluation and in-depth analyses of the face verification performance of human experts in comparison to state-of-the-art automatic face recognition solutions. This involves an extensive evaluation with 12 human experts and 4 automatic recognition solutions. The study concludes with a set of take-home-messages on different aspects of the correlation between the verification behavior of human and machine.