 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnup Rao
New Insights into Bootstrapping for Bandits
May 24, 2018

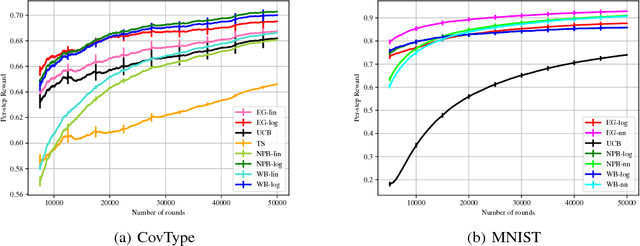


We investigate the use of bootstrapping in the bandit setting. We first show that the commonly used non-parametric bootstrapping (NPB) procedure can be provably inefficient and establish a near-linear lower bound on the regret incurred by it under the bandit model with Bernoulli rewards. We show that NPB with an appropriate amount of forced exploration can result in sub-linear albeit sub-optimal regret. As an alternative to NPB, we propose a weighted bootstrapping (WB) procedure. For Bernoulli rewards, WB with multiplicative exponential weights is mathematically equivalent to Thompson sampling (TS) and results in near-optimal regret bounds. Similarly, in the bandit setting with Gaussian rewards, we show that WB with additive Gaussian weights achieves near-optimal regret. Beyond these special cases, we show that WB leads to better empirical performance than TS for several reward distributions bounded on $[0,1]$. For the contextual bandit setting, we give practical guidelines that make bootstrapping simple and efficient to implement and result in good empirical performance on real-world datasets.
Stochastic Low-Rank Bandits
Dec 13, 2017
Many problems in computer vision and recommender systems involve low-rank matrices. In this work, we study the problem of finding the maximum entry of a stochastic low-rank matrix from sequential observations. At each step, a learning agent chooses pairs of row and column arms, and receives the noisy product of their latent values as a reward. The main challenge is that the latent values are unobserved. We identify a class of non-negative matrices whose maximum entry can be found statistically efficiently and propose an algorithm for finding them, which we call LowRankElim. We derive a $\DeclareMathOperator{\poly}{poly} O((K + L) \poly(d) \Delta^{-1} \log n)$ upper bound on its $n$-step regret, where $K$ is the number of rows, $L$ is the number of columns, $d$ is the rank of the matrix, and $\Delta$ is the minimum gap. The bound depends on other problem-specific constants that clearly do not depend $K L$. To the best of our knowledge, this is the first such result in the literature.
Fast, Provable Algorithms for Isotonic Regression in all $\ell_{p}$-norms
Nov 11, 2015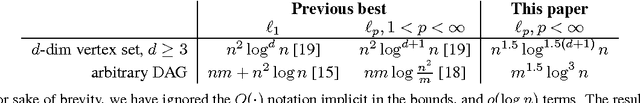
Given a directed acyclic graph $G,$ and a set of values $y$ on the vertices, the Isotonic Regression of $y$ is a vector $x$ that respects the partial order described by $G,$ and minimizes $||x-y||,$ for a specified norm. This paper gives improved algorithms for computing the Isotonic Regression for all weighted $\ell_{p}$-norms with rigorous performance guarantees. Our algorithms are quite practical, and their variants can be implemented to run fast in practice.
Algorithms for Lipschitz Learning on Graphs
Jun 30, 2015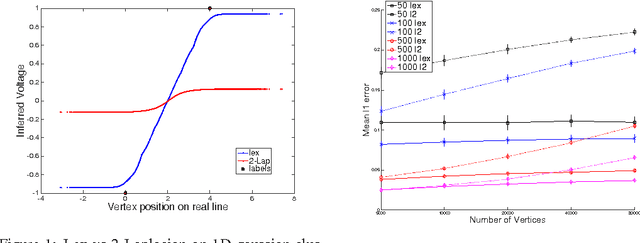
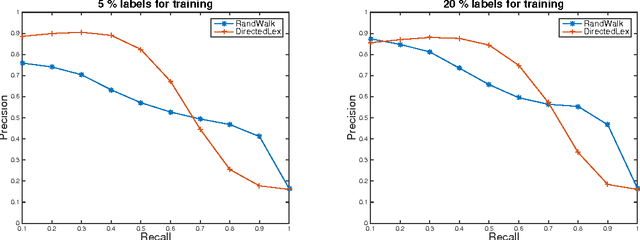
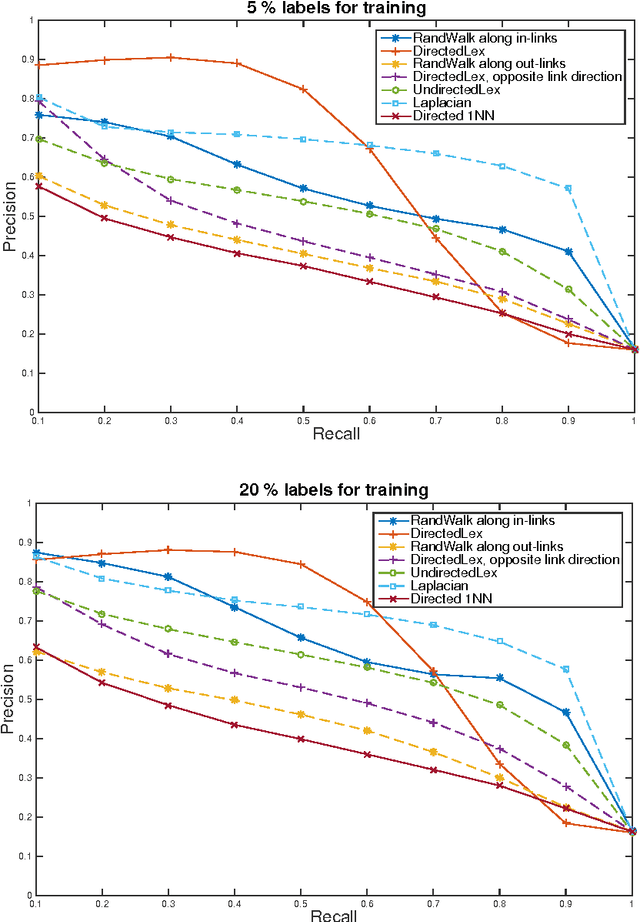
We develop fast algorithms for solving regression problems on graphs where one is given the value of a function at some vertices, and must find its smoothest possible extension to all vertices. The extension we compute is the absolutely minimal Lipschitz extension, and is the limit for large $p$ of $p$-Laplacian regularization. We present an algorithm that computes a minimal Lipschitz extension in expected linear time, and an algorithm that computes an absolutely minimal Lipschitz extension in expected time $\widetilde{O} (m n)$. The latter algorithm has variants that seem to run much faster in practice. These extensions are particularly amenable to regularization: we can perform $l_{0}$-regularization on the given values in polynomial time and $l_{1}$-regularization on the initial function values and on graph edge weights in time $\widetilde{O} (m^{3/2})$.