 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnssi Kanervisto
Action Space Shaping in Deep Reinforcement Learning
Apr 02, 2020
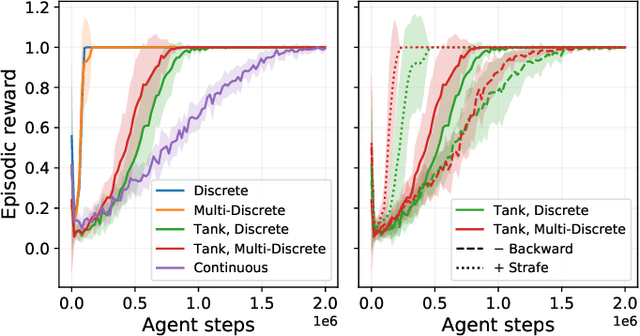
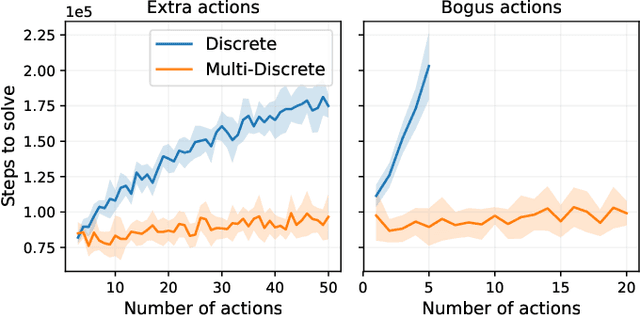
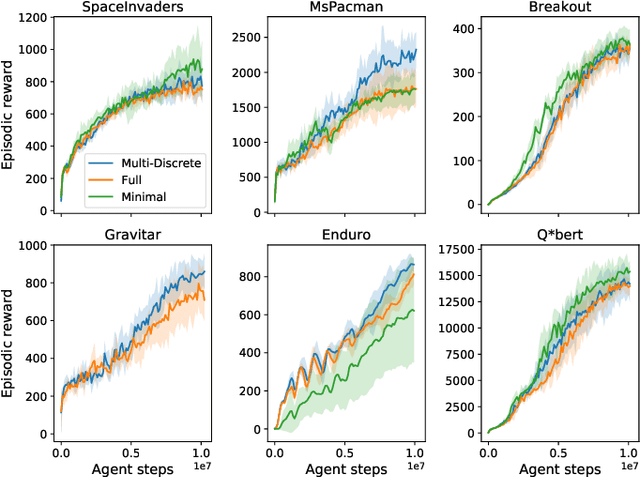
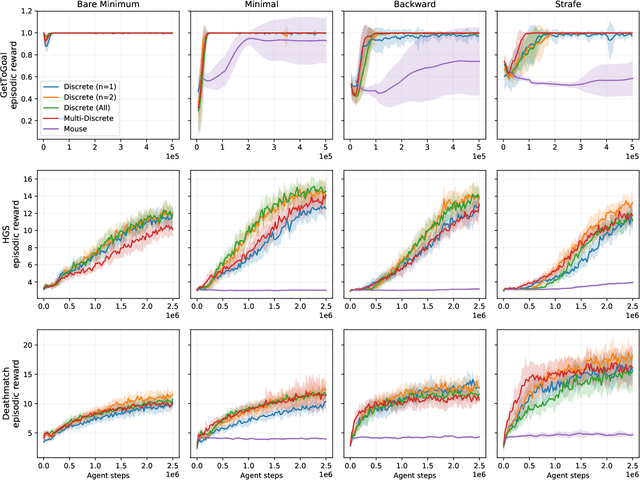
Reinforcement learning (RL) has been successful in training agents in various learning environments, including video-games. However, such work modifies and shrinks the action space from the game's original. This is to avoid trying "pointless" actions and to ease the implementation. Currently, this is mostly done based on intuition, with little systematic research supporting the design decisions. In this work, we aim to gain insight on these action space modifications by conducting extensive experiments in video-game environments. Our results show how domain-specific removal of actions and discretization of continuous actions can be crucial for successful learning. With these insights, we hope to ease the use of RL in new environments, by clarifying what action-spaces are easy to learn.
An initial investigation on optimizing tandem speaker verification and countermeasure systems using reinforcement learning
Feb 06, 2020
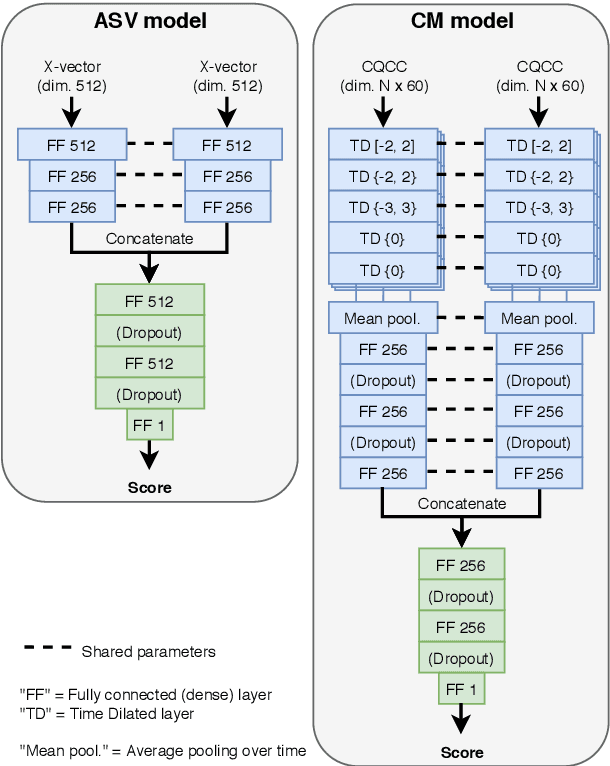

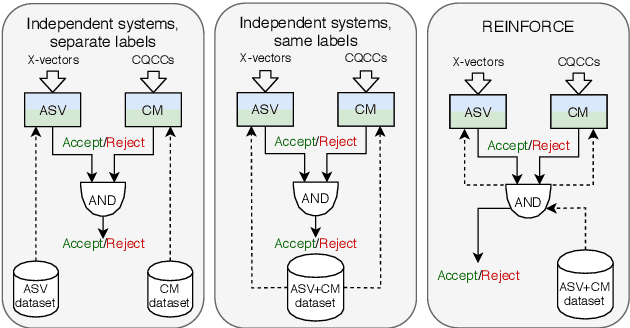
The spoofing countermeasure (CM) systems in automatic speaker verification (ASV) are not typically used in isolation of each other. These systems can be combined, for example, into a cascaded system where CM produces first a decision whether the input is synthetic or bona fide speech. In case the CM decides it is a bona fide sample, then the ASV system will consider it for speaker verification. End users of the system are not interested in the performance of the individual sub-modules, but instead are interested in the performance of the combined system. Such combination can be evaluated with tandem detection cost function (t-DCF) measure, yet the individual components are trained separately from each other using their own performance metrics. In this work we study training the ASV and CM components together for a better t-DCF measure by using reinforcement learning. We demonstrate that such training procedure indeed is able to improve the performance of the combined system, and does so with more reliable results than with the standard supervised learning techniques we compare against.
Towards Debugging Deep Neural Networks by Generating Speech Utterances
Jul 06, 2019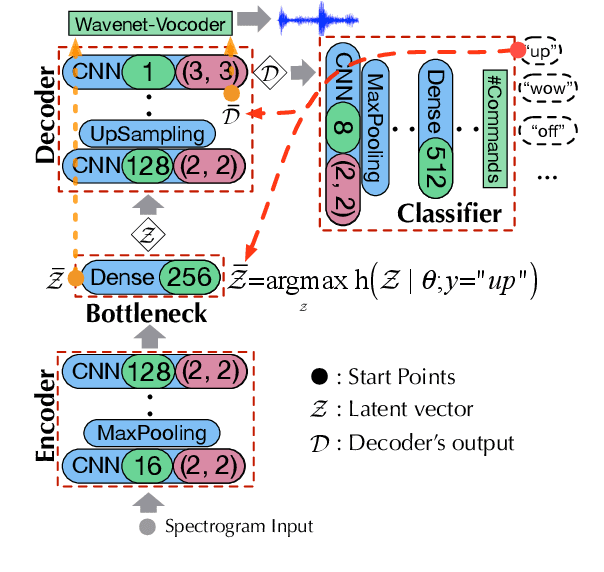
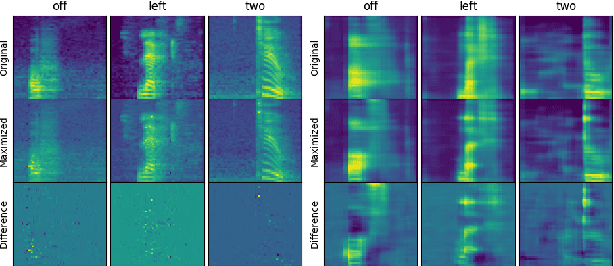
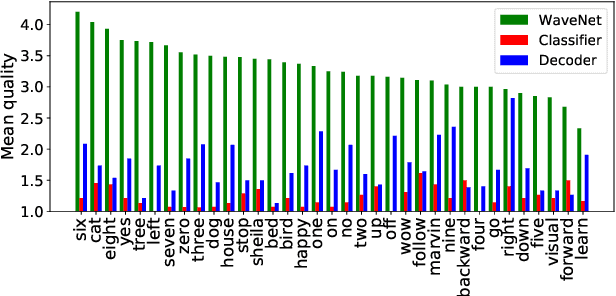
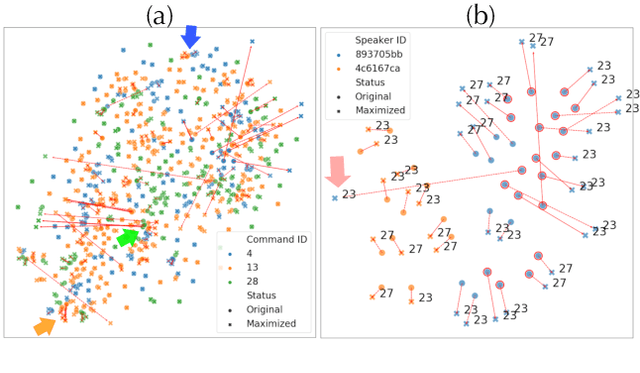
Deep neural networks (DNN) are able to successfully process and classify speech utterances. However, understanding the reason behind a classification by DNN is difficult. One such debugging method used with image classification DNNs is activation maximization, which generates example-images that are classified as one of the classes. In this work, we evaluate applicability of this method to speech utterance classifiers as the means to understanding what DNN "listens to". We trained a classifier using the speech command corpus and then use activation maximization to pull samples from the trained model. Then we synthesize audio from features using WaveNet vocoder for subjective analysis. We measure the quality of generated samples by objective measurements and crowd-sourced human evaluations. Results show that when combined with the prior of natural speech, activation maximization can be used to generate examples of different classes. Based on these results, activation maximization can be used to start opening up the DNN black-box in speech tasks.
Do Autonomous Agents Benefit from Hearing?
May 10, 2019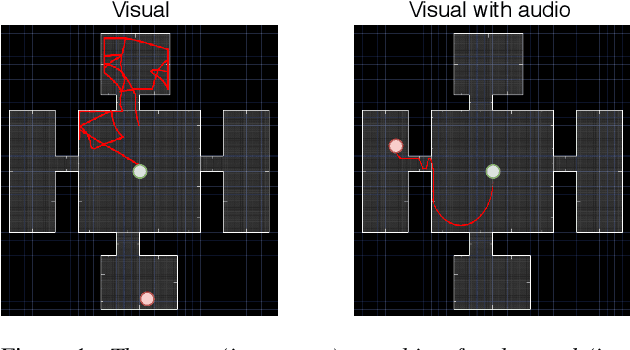

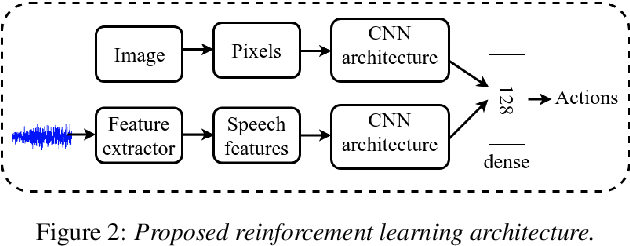
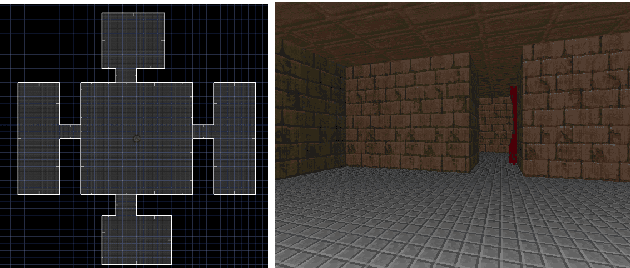
Mapping states to actions in deep reinforcement learning is mainly based on visual information. The commonly used approach for dealing with visual information is to extract pixels from images and use them as state representation for reinforcement learning agent. But, any vision only agent is handicapped by not being able to sense audible cues. Using hearing, animals are able to sense targets that are outside of their visual range. In this work, we propose the use of audio as complementary information to visual only in state representation. We assess the impact of such multi-modal setup in reach-the-goal tasks in ViZDoom environment. Results show that the agent improves its behavior when visual information is accompanied with audio features.
From Video Game to Real Robot: The Transfer between Action Spaces
May 02, 2019
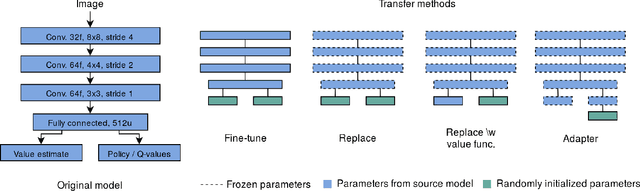
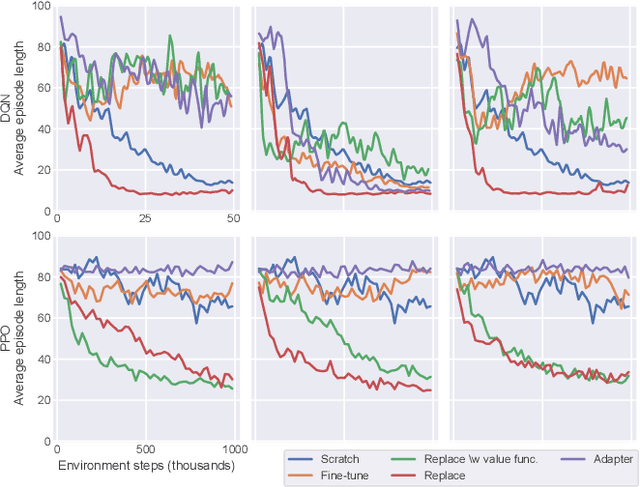
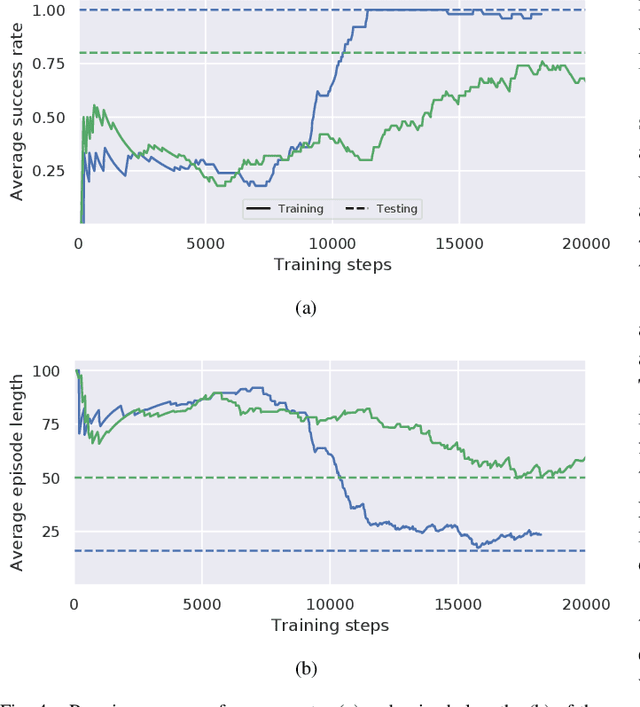
Training agents with reinforcement learning based techniques requires thousands of steps, which translates to long training periods when applied to robots. By training the policy in a simulated environment we avoid such limitation. Typically, the action spaces in a simulation and real robot are kept as similar as possible, but if we want to use a generic simulation environment, this strategy will not work. Video games, such as Doom (1993), offer a crude but multi-purpose environments that can used for learning various tasks. However, original Doom has four discrete actions for movement and the robot in our case has two continuous actions. In this work, we study the transfer between these two different action spaces. We begin with experiments in a simulated environment, after which we validate the results with experiments on a real robot. Results show that fine-tuning initially learned network parameters leads to unreliable results, but by keeping most of the neural network frozen we obtain above $90\%$ success rate in simulation and real robot experiments.
ToriLLE: Learning Environment for Hand-to-Hand Combat
Jul 26, 2018
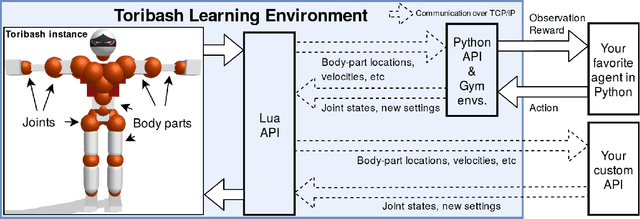
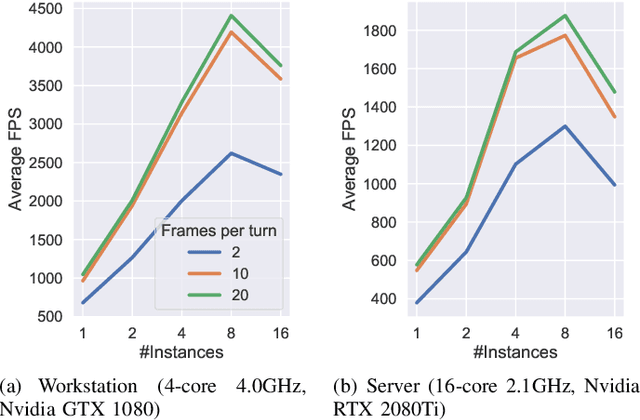
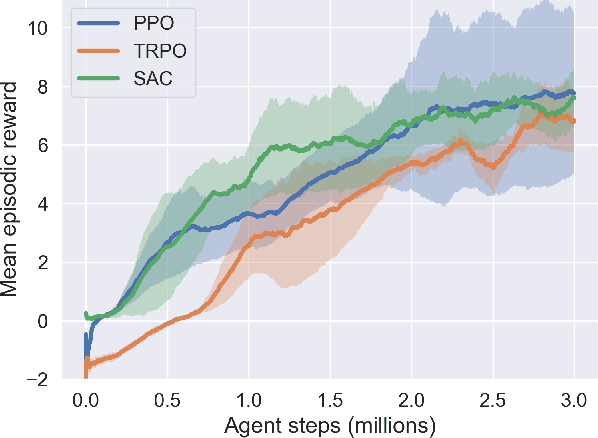
We present Toribash Learning Environment (ToriLLE), an interface with video game Toribash for training machine learning agents. Toribash is a MuJoCo-like environment of two humanoid character fighting each other hand-to-hand, controlled by changing states of body joints. Competitive nature of Toribash lends itself to two-agent experiments, and active player-base can be used for human baselines. This white paper describes the environment with its pros, cons and limitations as well experimentally show ToriLLE's applicability as a learning environment by successfully training reinforcement learning agents that improved over time. The code is available at https://github.com/Miffyli/ToriLLE.
Image-to-Markup Generation with Coarse-to-Fine Attention
Jun 13, 2017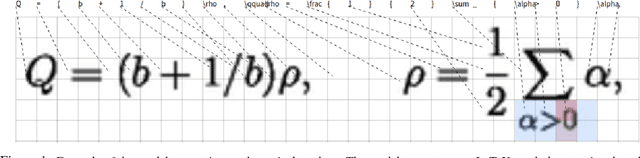
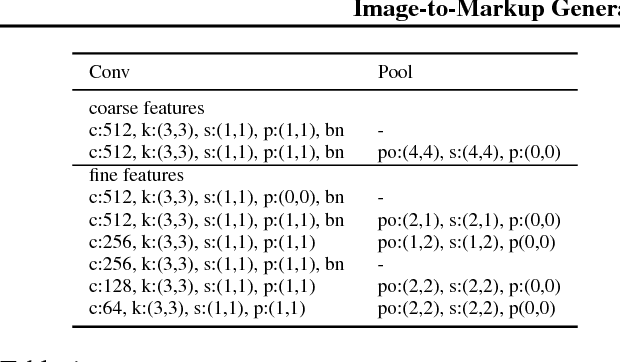
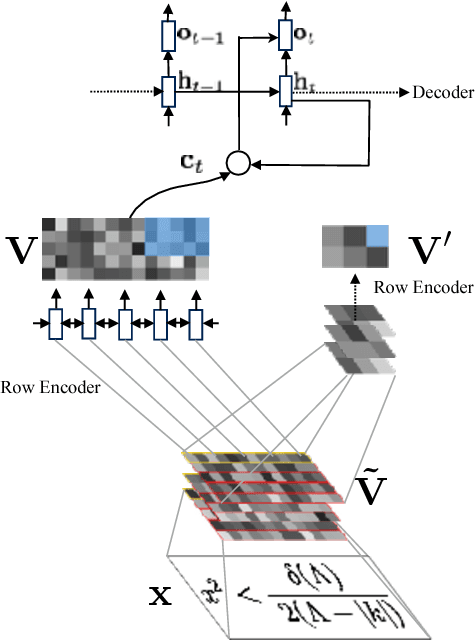
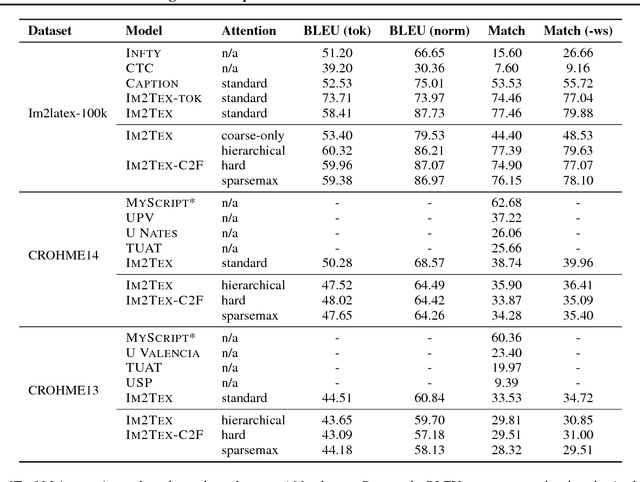
We present a neural encoder-decoder model to convert images into presentational markup based on a scalable coarse-to-fine attention mechanism. Our method is evaluated in the context of image-to-LaTeX generation, and we introduce a new dataset of real-world rendered mathematical expressions paired with LaTeX markup. We show that unlike neural OCR techniques using CTC-based models, attention-based approaches can tackle this non-standard OCR task. Our approach outperforms classical mathematical OCR systems by a large margin on in-domain rendered data, and, with pretraining, also performs well on out-of-domain handwritten data. To reduce the inference complexity associated with the attention-based approaches, we introduce a new coarse-to-fine attention layer that selects a support region before applying attention.