 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndrzej Cichocki
On Multiple Intelligences and Learning Styles for Artificial Intelligence Systems: Future Research Trends in AI with a Human Face?
Aug 30, 2020
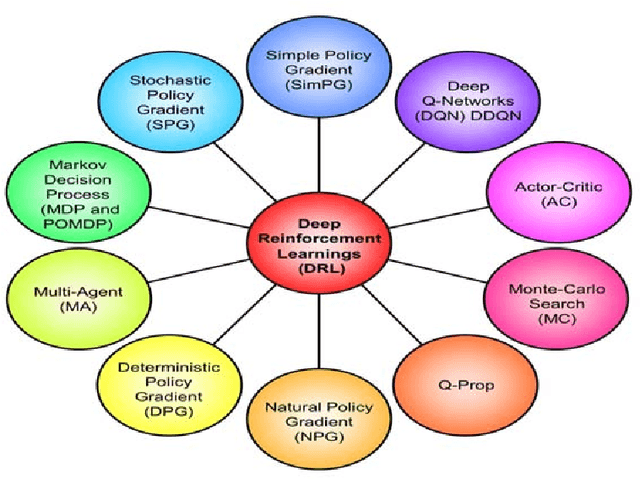
This article discusses recent trends and concepts in developing new kinds of artificial intelligence (AI) systems which relate to complex facets and different types of human intelligence, especially social, emotional, attentional and ethical intelligence, which to date have been under-discussed. We describe various aspects of multiple human intelligence and learning styles, which may impact on a variety of AI problem domains. Using the concept of multiple intelligence rather than a single type of intelligence, we categorize and provide working definitions of various AI depending on their cognitive skills or capacities. Future AI systems will be able not only to communicate with human actors and each other, but also to efficiently exchange knowledge with abilities of cooperation, collaboration and even co-creating something new and valuable and have meta-learning capacities. Multi-agent systems such as these can be used to solve problems that would be difficult to solve by any individual intelligent agent.
Stable Low-rank Tensor Decomposition for Compression of Convolutional Neural Network
Aug 12, 2020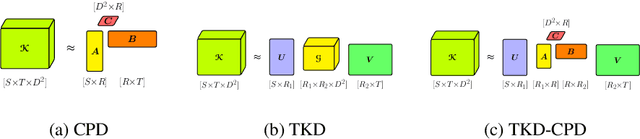
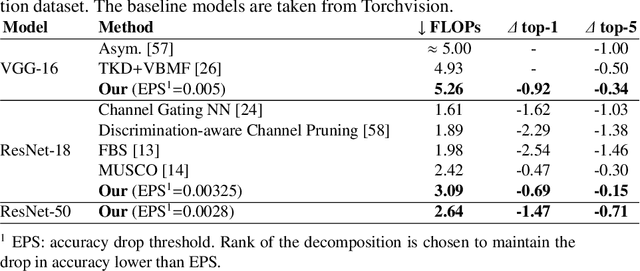
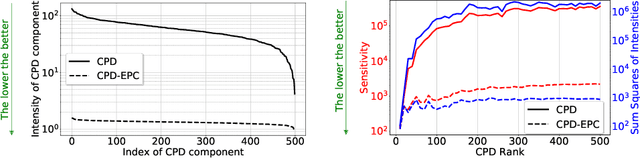
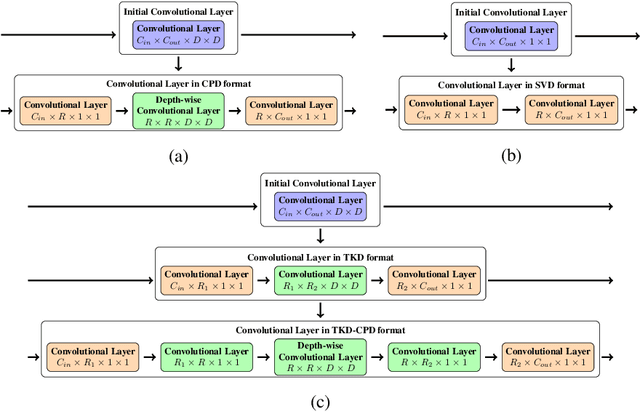
Most state of the art deep neural networks are overparameterized and exhibit a high computational cost. A straightforward approach to this problem is to replace convolutional kernels with its low-rank tensor approximations, whereas the Canonical Polyadic tensor Decomposition is one of the most suited models. However, fitting the convolutional tensors by numerical optimization algorithms often encounters diverging components, i.e., extremely large rank-one tensors but canceling each other. Such degeneracy often causes the non-interpretable result and numerical instability for the neural network fine-tuning. This paper is the first study on degeneracy in the tensor decomposition of convolutional kernels. We present a novel method, which can stabilize the low-rank approximation of convolutional kernels and ensure efficient compression while preserving the high-quality performance of the neural networks. We evaluate our approach on popular CNN architectures for image classification and show that our method results in much lower accuracy degradation and provides consistent performance.
On Multiple Intelligences and Learning Styles for Multi- Agent Systems: Future Research Trends in AI with a Human Face?
Aug 07, 2020This article discusses recent trends and concepts in developing new kinds of artificial intelligence (AI) systems which relate to complex facets and different types of human intelligence, especially social, emotional, and ethical intelligence, which to date have been under-discussed. We describe various aspects of multiple human intelligence and learning styles, which may impact on a variety of AI problem domains. Using the concept of multiple intelligence rather than a single type of intelligence, we categorize and provide working definitions of various AI depending on their cognitive skills or capacities. Future AI systems will be able not only to communicate with human actors and each other, but also to efficiently exchange knowledge with abilities of cooperation, collaboration and even co-creating something new and valuable and have meta-learning capacities. Multi-agent systems such as these can be used to solve problems that would be difficult to solve by any individual intelligent agent.
Towards Understanding Normalization in Neural ODEs
Apr 27, 2020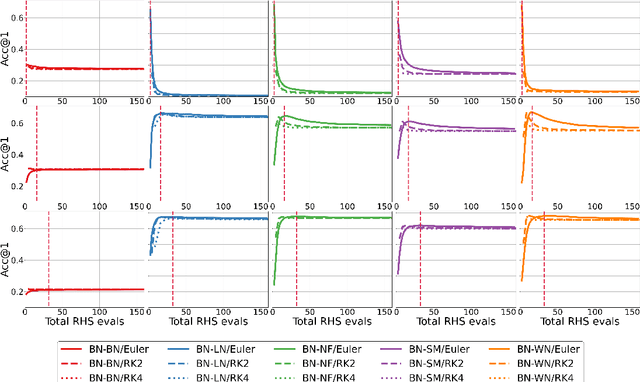
Normalization is an important and vastly investigated technique in deep learning. However, its role for Ordinary Differential Equation based networks (neural ODEs) is still poorly understood. This paper investigates how different normalization techniques affect the performance of neural ODEs. Particularly, we show that it is possible to achieve 93% accuracy in the CIFAR-10 classification task, and to the best of our knowledge, this is the highest reported accuracy among neural ODEs tested on this problem.
Interpolated Adjoint Method for Neural ODEs
Mar 11, 2020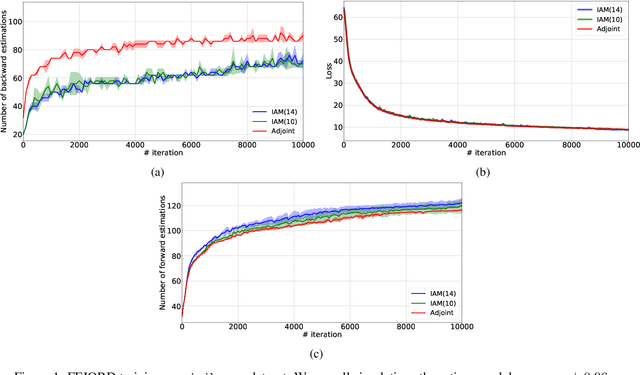
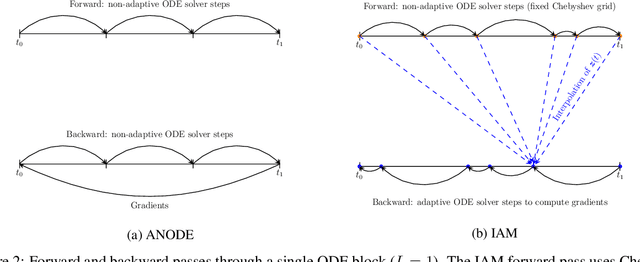

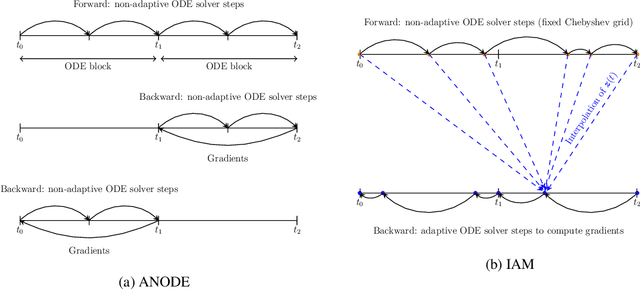
In this paper, we propose a method, which allows us to alleviate or completely avoid the notorious problem of numerical instability and stiffness of the adjoint method for training neural ODE. On the backward pass, we propose to use the machinery of smooth function interpolation to restore the trajectory obtained during the forward integration. We show the viability of our approach, both in theory and practice.
Using Reinforcement Learning in the Algorithmic Trading Problem
Feb 26, 2020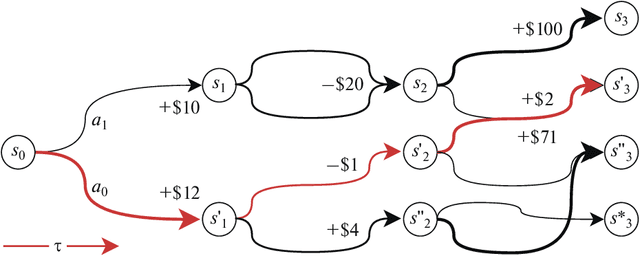
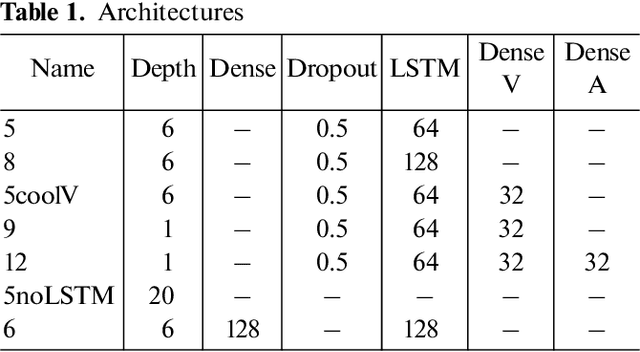
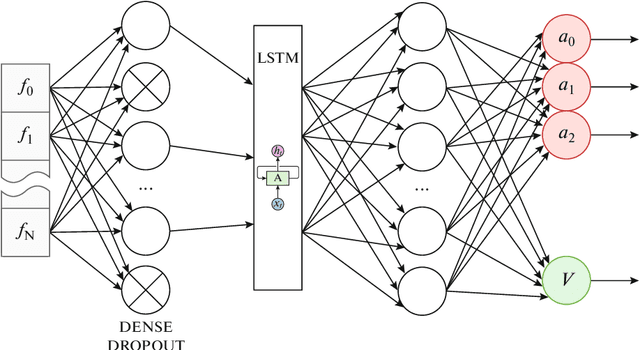
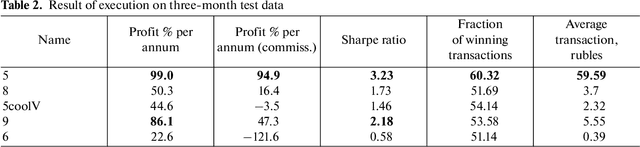
The development of reinforced learning methods has extended application to many areas including algorithmic trading. In this paper trading on the stock exchange is interpreted into a game with a Markov property consisting of states, actions, and rewards. A system for trading the fixed volume of a financial instrument is proposed and experimentally tested; this is based on the asynchronous advantage actor-critic method with the use of several neural network architectures. The application of recurrent layers in this approach is investigated. The experiments were performed on real anonymized data. The best architecture demonstrated a trading strategy for the RTS Index futures (MOEX:RTSI) with a profitability of 66% per annum accounting for commission. The project source code is available via the following link: http://github.com/evgps/a3c_trading.
Block Hankel Tensor ARIMA for Multiple Short Time Series Forecasting
Feb 25, 2020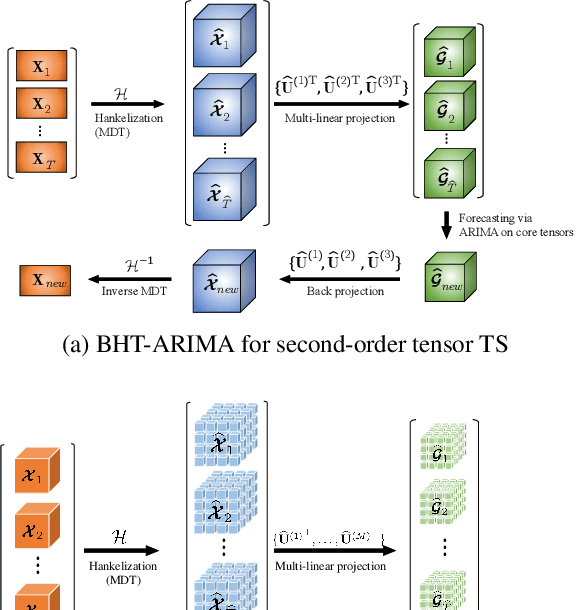
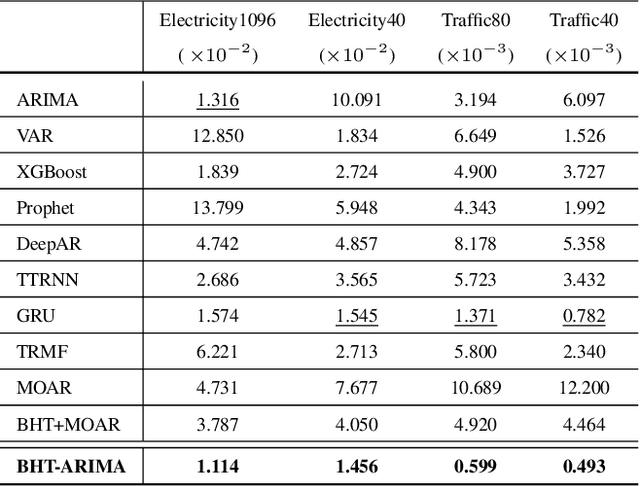
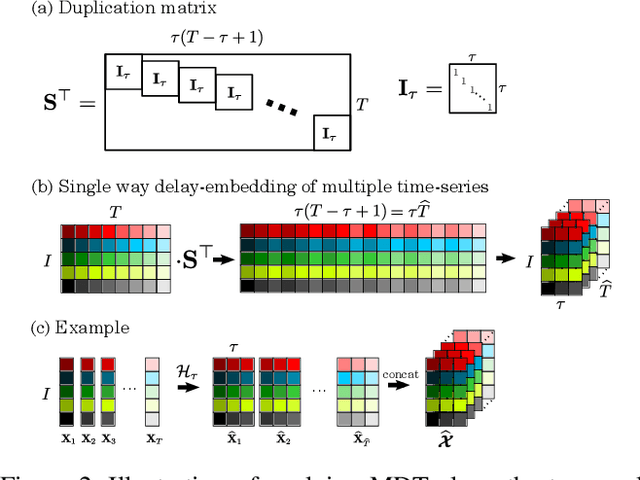
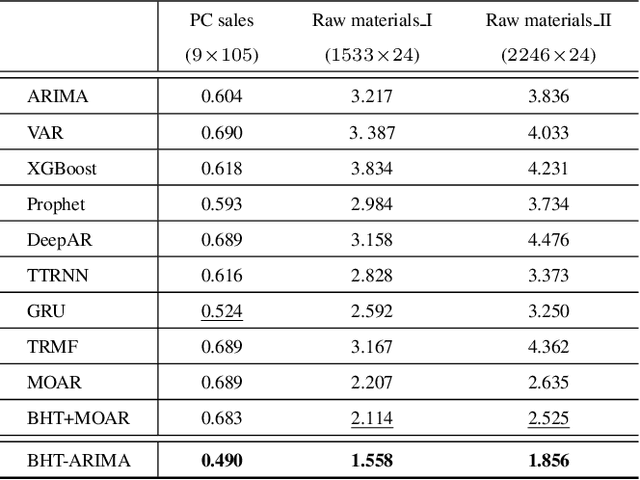
This work proposes a novel approach for multiple time series forecasting. At first, multi-way delay embedding transform (MDT) is employed to represent time series as low-rank block Hankel tensors (BHT). Then, the higher-order tensors are projected to compressed core tensors by applying Tucker decomposition. At the same time, the generalized tensor Autoregressive Integrated Moving Average (ARIMA) is explicitly used on consecutive core tensors to predict future samples. In this manner, the proposed approach tactically incorporates the unique advantages of MDT tensorization (to exploit mutual correlations) and tensor ARIMA coupled with low-rank Tucker decomposition into a unified framework. This framework exploits the low-rank structure of block Hankel tensors in the embedded space and captures the intrinsic correlations among multiple TS, which thus can improve the forecasting results, especially for multiple short time series. Experiments conducted on three public datasets and two industrial datasets verify that the proposed BHT-ARIMA effectively improves forecasting accuracy and reduces computational cost compared with the state-of-the-art methods.
Reduced-Order Modeling of Deep Neural Networks
Nov 25, 2019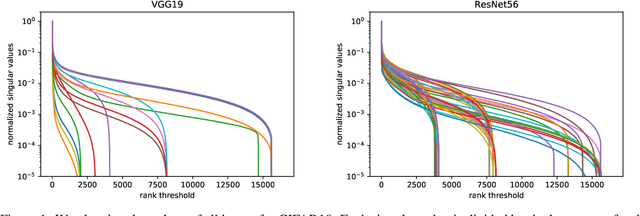

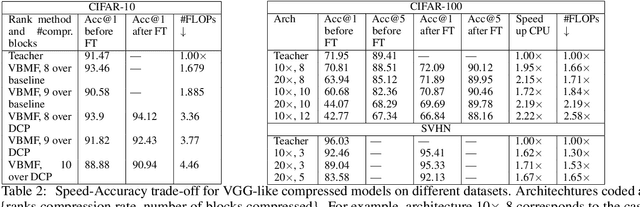
We introduce a new method for speeding up the inference of deep neural networks. It is somewhat inspired by the reduced-order modeling techniques for dynamical systems.The cornerstone of the proposed method is the maximum volume algorithm. We demonstrate efficiency on neural networks pre-trained on different datasets. We show that in many practical cases it is possible to replace convolutional layers with much smaller fully-connected layers with a relatively small drop in accuracy.