 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMéthodes pour la représentation informatisée de données lexicales / Methoden der Speicherung lexikalischer Daten
May 15, 2014

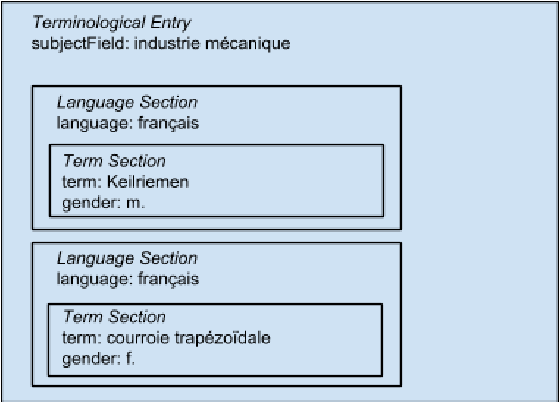

In recent years, new developments in the area of lexicography have altered not only the management, processing and publishing of lexicographical data, but also created new types of products such as electronic dictionaries and thesauri. These expand the range of possible uses of lexical data and support users with more flexibility, for instance in assisting human translation. In this article, we give a short and easy-to-understand introduction to the problematic nature of the storage, display and interpretation of lexical data. We then describe the main methods and specifications used to build and represent lexical data. This paper is targeted for the following groups of people: linguists, lexicographers, IT specialists, computer linguists and all others who wish to learn more about the modelling, representation and visualization of lexical knowledge. This paper is written in two languages: French and German.
* This text comprises both a French and a German version
Data formats for phonological corpora
Mar 04, 2012
The goal of the present chapter is to explore the possibility of providing the research (but also the industrial) community that commonly uses spoken corpora with a stable portfolio of well-documented standardised formats that allow a high re-use rate of annotated spoken resources and, as a consequence, better interoperability across tools used to produce or exploit such resources.
Representing human and machine dictionaries in Markup languages
Dec 16, 2009


In this chapter we present the main issues in representing machine readable dictionaries in XML, and in particular according to the Text Encoding Dictionary (TEI) guidelines.