 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndrea Passarella
Anomaly Detection through Unsupervised Federated Learning
Sep 09, 2022



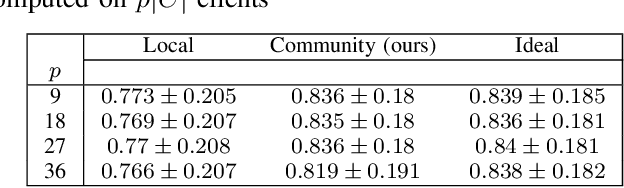
Federated learning (FL) is proving to be one of the most promising paradigms for leveraging distributed resources, enabling a set of clients to collaboratively train a machine learning model while keeping the data decentralized. The explosive growth of interest in the topic has led to rapid advancements in several core aspects like communication efficiency, handling non-IID data, privacy, and security capabilities. However, the majority of FL works only deal with supervised tasks, assuming that clients' training sets are labeled. To leverage the enormous unlabeled data on distributed edge devices, in this paper, we aim to extend the FL paradigm to unsupervised tasks by addressing the problem of anomaly detection in decentralized settings. In particular, we propose a novel method in which, through a preprocessing phase, clients are grouped into communities, each having similar majority (i.e., inlier) patterns. Subsequently, each community of clients trains the same anomaly detection model (i.e., autoencoders) in a federated fashion. The resulting model is then shared and used to detect anomalies within the clients of the same community that joined the corresponding federated process. Experiments show that our method is robust, and it can detect communities consistent with the ideal partitioning in which groups of clients having the same inlier patterns are known. Furthermore, the performance is significantly better than those in which clients train models exclusively on local data and comparable with federated models of ideal communities' partition.
Modeling Human Behavior Part I -- Learning and Belief Approaches
May 13, 2022

There is a clear desire to model and comprehend human behavior. Trends in research covering this topic show a clear assumption that many view human reasoning as the presupposed standard in artificial reasoning. As such, topics such as game theory, theory of mind, machine learning, etc. all integrate concepts which are assumed components of human reasoning. These serve as techniques to attempt to both replicate and understand the behaviors of humans. In addition, next generation autonomous and adaptive systems will largely include AI agents and humans working together as teams. To make this possible, autonomous agents will require the ability to embed practical models of human behavior, which allow them not only to replicate human models as a technique to "learn", but to to understand the actions of users and anticipate their behavior, so as to truly operate in symbiosis with them. The main objective of this paper it to provide a succinct yet systematic review of the most important approaches in two areas dealing with quantitative models of human behaviors. Specifically, we focus on (i) techniques which learn a model or policy of behavior through exploration and feedback, such as Reinforcement Learning, and (ii) directly model mechanisms of human reasoning, such as beliefs and bias, without going necessarily learning via trial-and-error.
Modeling Human Behavior Part II -- Cognitive approaches and Uncertainty
May 13, 2022
As we discussed in Part I of this topic, there is a clear desire to model and comprehend human behavior. Given the popular presupposition of human reasoning as the standard for learning and decision-making, there have been significant efforts and a growing trend in research to replicate these innate human abilities in artificial systems. In Part I, we discussed learning methods which generate a model of behavior from exploration of the system and feedback based on the exhibited behavior as well as topics relating to the use of or accounting for beliefs with respect to applicable skills or mental states of others. In this work, we will continue the discussion from the perspective of methods which focus on the assumed cognitive abilities, limitations, and biases demonstrated in human reasoning. We will arrange these topics as follows (i) methods such as cognitive architectures, cognitive heuristics, and related which demonstrate assumptions of limitations on cognitive resources and how that impacts decisions and (ii) methods which generate and utilize representations of bias or uncertainty to model human decision-making or the future outcomes of decisions.
A Cognitive Framework for Delegation Between Error-Prone AI and Human Agents
Apr 06, 2022
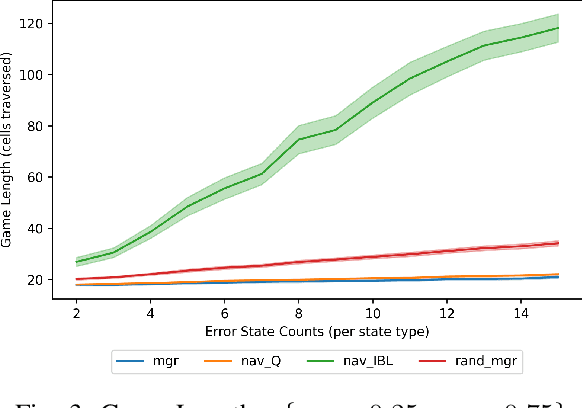
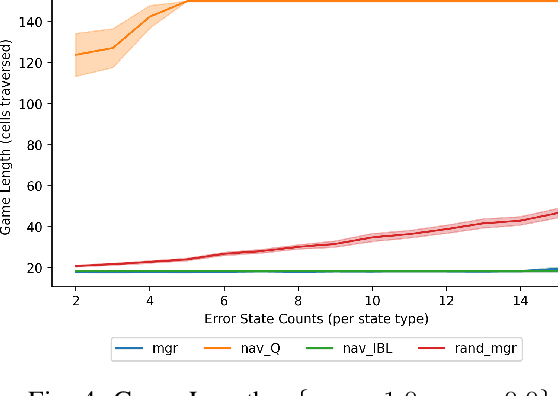
With humans interacting with AI-based systems at an increasing rate, it is necessary to ensure the artificial systems are acting in a manner which reflects understanding of the human. In the case of humans and artificial AI agents operating in the same environment, we note the significance of comprehension and response to the actions or capabilities of a human from an agent's perspective, as well as the possibility to delegate decisions either to humans or to agents, depending on who is deemed more suitable at a certain point in time. Such capabilities will ensure an improved responsiveness and utility of the entire human-AI system. To that end, we investigate the use of cognitively inspired models of behavior to predict the behavior of both human and AI agents. The predicted behavior, and associated performance with respect to a certain goal, is used to delegate control between humans and AI agents through the use of an intermediary entity. As we demonstrate, this allows overcoming potential shortcomings of either humans or agents in the pursuit of a goal.
Structural invariants and semantic fingerprints in the "ego network" of words
Mar 01, 2022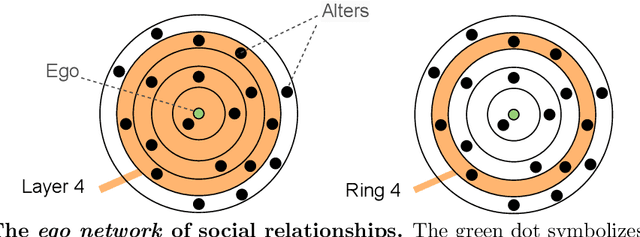
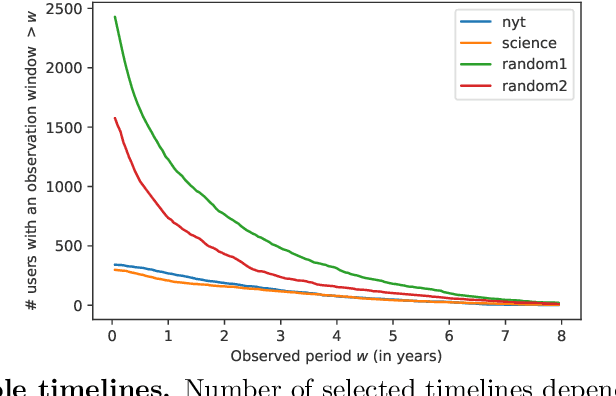

Well-established cognitive models coming from anthropology have shown that, due to the cognitive constraints that limit our "bandwidth" for social interactions, humans organize their social relations according to a regular structure. In this work, we postulate that similar regularities can be found in other cognitive processes, such as those involving language production. In order to investigate this claim, we analyse a dataset containing tweets of a heterogeneous group of Twitter users (regular users and professional writers). Leveraging a methodology similar to the one used to uncover the well-established social cognitive constraints, we find regularities at both the structural and semantic level. At the former, we find that a concentric layered structure (which we call ego network of words, in analogy to the ego network of social relationships) very well captures how individuals organise the words they use. The size of the layers in this structure regularly grows (approximately 2-3 times with respect to the previous one) when moving outwards, and the two penultimate external layers consistently account for approximately 60% and 30% of the used words, irrespective of the number of the total number of layers of the user. For the semantic analysis, each ring of each ego network is described by a semantic profile, which captures the topics associated with the words in the ring. We find that ring #1 has a special role in the model. It is semantically the most dissimilar and the most diverse among the rings. We also show that the topics that are important in the innermost ring also have the characteristic of being predominant in each of the other rings, as well as in the entire ego network. In this respect, ring #1 can be seen as the semantic fingerprint of the ego network of words.
Predictive Auto-scaling with OpenStack Monasca
Nov 03, 2021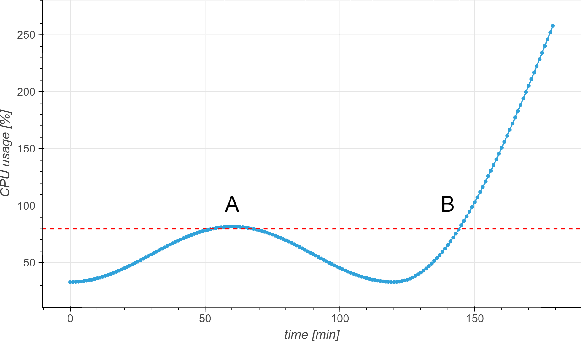
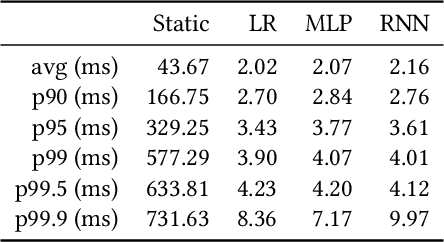

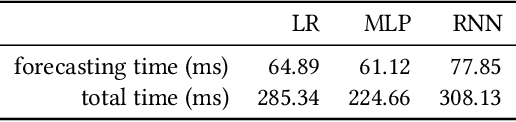
Cloud auto-scaling mechanisms are typically based on reactive automation rules that scale a cluster whenever some metric, e.g., the average CPU usage among instances, exceeds a predefined threshold. Tuning these rules becomes particularly cumbersome when scaling-up a cluster involves non-negligible times to bootstrap new instances, as it happens frequently in production cloud services. To deal with this problem, we propose an architecture for auto-scaling cloud services based on the status in which the system is expected to evolve in the near future. Our approach leverages on time-series forecasting techniques, like those based on machine learning and artificial neural networks, to predict the future dynamics of key metrics, e.g., resource consumption metrics, and apply a threshold-based scaling policy on them. The result is a predictive automation policy that is able, for instance, to automatically anticipate peaks in the load of a cloud application and trigger ahead of time appropriate scaling actions to accommodate the expected increase in traffic. We prototyped our approach as an open-source OpenStack component, which relies on, and extends, the monitoring capabilities offered by Monasca, resulting in the addition of predictive metrics that can be leveraged by orchestration components like Heat or Senlin. We show experimental results using a recurrent neural network and a multi-layer perceptron as predictor, which are compared with a simple linear regression and a traditional non-predictive auto-scaling policy. However, the proposed framework allows for the easy customization of the prediction policy as needed.
Cellular traffic offloading via Opportunistic Networking with Reinforcement Learning
Oct 01, 2021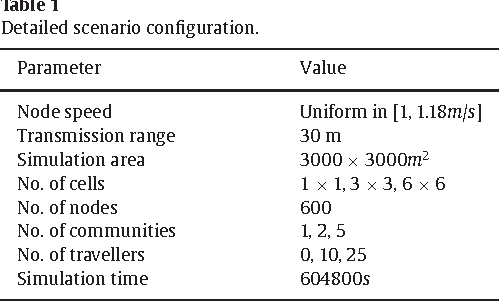
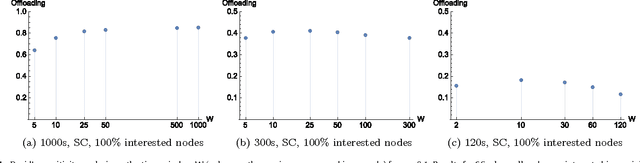

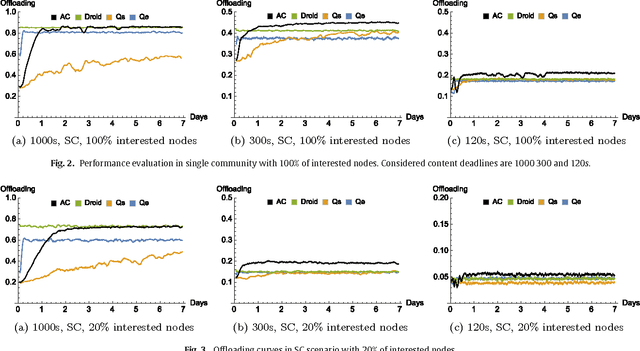
The widespread diffusion of mobile phones is triggering an exponential growth of mobile data traffic that is likely to cause, in the near future, considerable traffic overload issues even in last-generation cellular networks. Offloading part of the traffic to other networks is considered a very promising approach and, in particular, in this paper, we consider offloading through opportunistic networks of users' devices. However, the performance of this solution strongly depends on the pattern of encounters between mobile nodes, which should therefore be taken into account when designing offloading control algorithms. In this paper, we propose an adaptive offloading solution based on the Reinforcement Learning framework and we evaluate and compare the performance of two well-known learning algorithms: Actor-Critic and Q-Learning. More precisely, in our solution the controller of the dissemination process, once trained, is able to select a proper number of content replicas to be injected into the opportunistic network to guarantee the timely delivery of contents to all interested users. We show that our system based on Reinforcement Learning is able to automatically learn a very efficient strategy to reduce the traffic on the cellular network, without relying on any additional context information about the opportunistic network. Our solution achieves a higher level of offloading with respect to other state-of-the-art approaches, in a range of different mobility settings. Moreover, we show that a more refined learning solution, based on the Actor-Critic algorithm, is significantly more efficient than a simpler solution based on Q-learning.
A communication efficient distributed learning framework for smart environments
Sep 27, 2021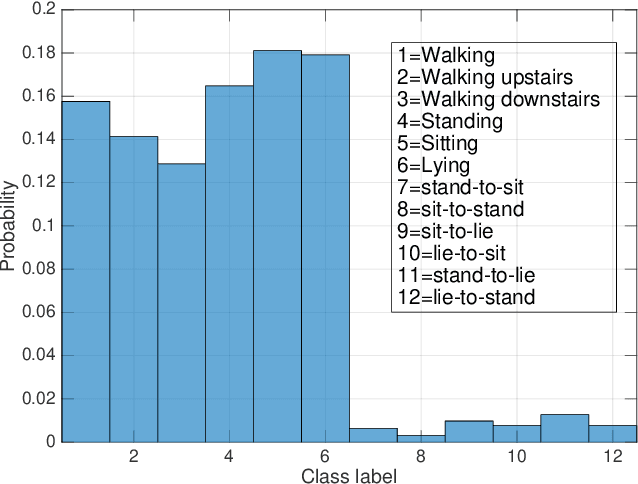

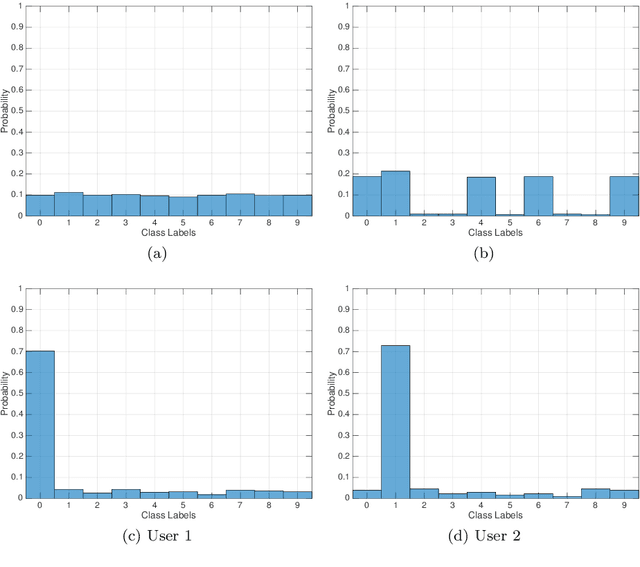
Due to the pervasive diffusion of personal mobile and IoT devices, many ``smart environments'' (e.g., smart cities and smart factories) will be, among others, generators of huge amounts of data. Currently, this is typically achieved through centralised cloud-based data analytics services. However, according to many studies, this approach may present significant issues from the standpoint of data ownership, and even wireless network capacity. One possibility to cope with these shortcomings is to move data analytics closer to where data is generated. In this paper, we tackle this issue by proposing and analyzing a distributed learning framework, whereby data analytics are performed at the edge of the network, i.e., on locations very close to where data is generated. Specifically, in our framework, partial data analytics are performed directly on the nodes that generate the data, or on nodes close by (e.g., some of the data generators can take this role on behalf of subsets of other nodes nearby). Then, nodes exchange partial models and refine them accordingly. Our framework is general enough to host different analytics services. In the specific case analysed in the paper, we focus on a learning task, considering two distributed learning algorithms. Using an activity recognition and a pattern recognition task, both on reference datasets, we compare the two learning algorithms between each other and with a central cloud solution (i.e., one that has access to the complete datasets). Our results show that using distributed machine learning techniques, it is possible to drastically reduce the network overhead, while obtaining performance comparable to the cloud solution in terms of learning accuracy. The analysis also shows when each distributed learning approach is preferable, based on the specific distribution of the data on the nodes.
Energy efficient distributed analytics at the edge of the network for IoT environments
Sep 23, 2021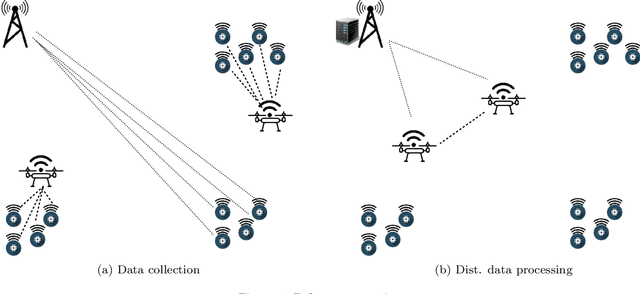

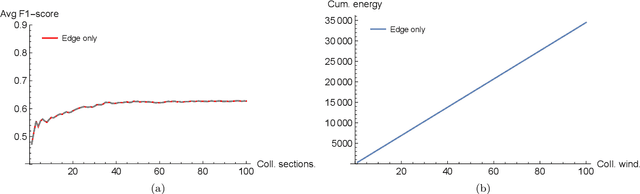
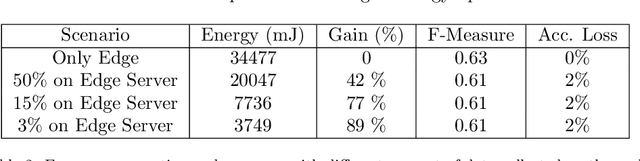
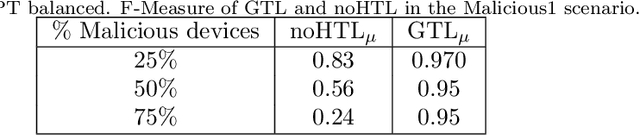
Due to the pervasive diffusion of personal mobile and IoT devices, many "smart environments" (e.g., smart cities and smart factories) will be, generators of huge amounts of data. Currently, analysis of this data is typically achieved through centralised cloud-based services. However, according to many studies, this approach may present significant issues from the standpoint of data ownership, as well as wireless network capacity. In this paper, we exploit the fog computing paradigm to move computation close to where data is produced. We exploit a well-known distributed machine learning framework (Hypothesis Transfer Learning), and perform data analytics on mobile nodes passing by IoT devices, in addition to fog gateways at the edge of the network infrastructure. We analyse the performance of different configurations of the distributed learning framework, in terms of (i) accuracy obtained in the learning task and (ii) energy spent to send data between the involved nodes. Specifically, we consider reference wireless technologies for communication between the different types of nodes we consider, e.g. LTE, Nb-IoT, 802.15.4, 802.11, etc. Our results show that collecting data through the mobile nodes and executing the distributed analytics using short-range communication technologies, such as 802.15.4 and 802.11, allows to strongly reduce the energy consumption of the system up to $94\%$ with a loss in accuracy w.r.t. a centralised cloud solution up to $2\%$.
Harnessing the Power of Ego Network Layers for Link Prediction in Online Social Networks
Sep 19, 2021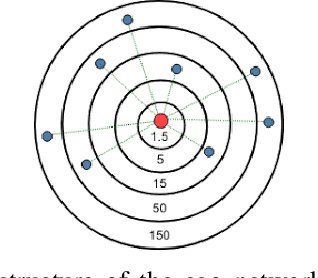
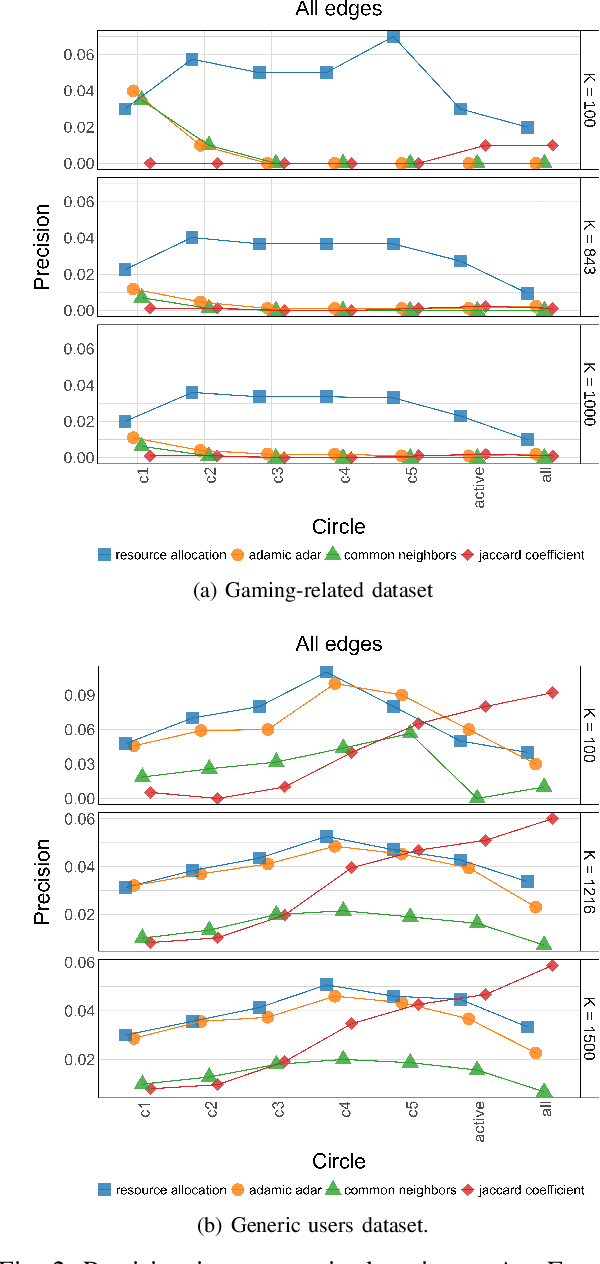
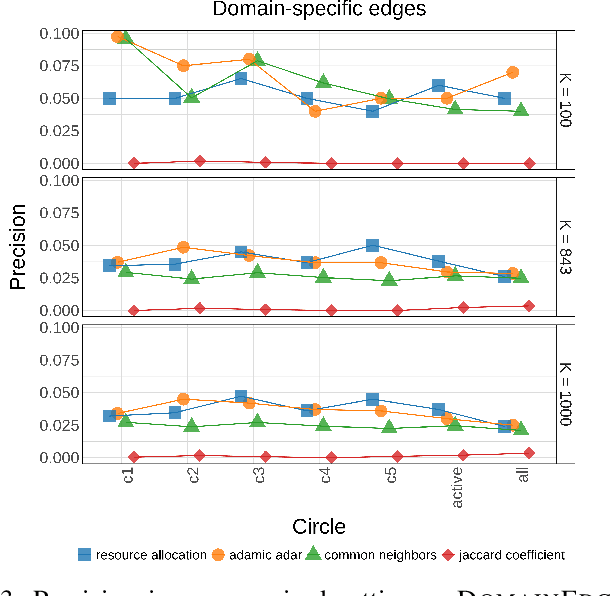
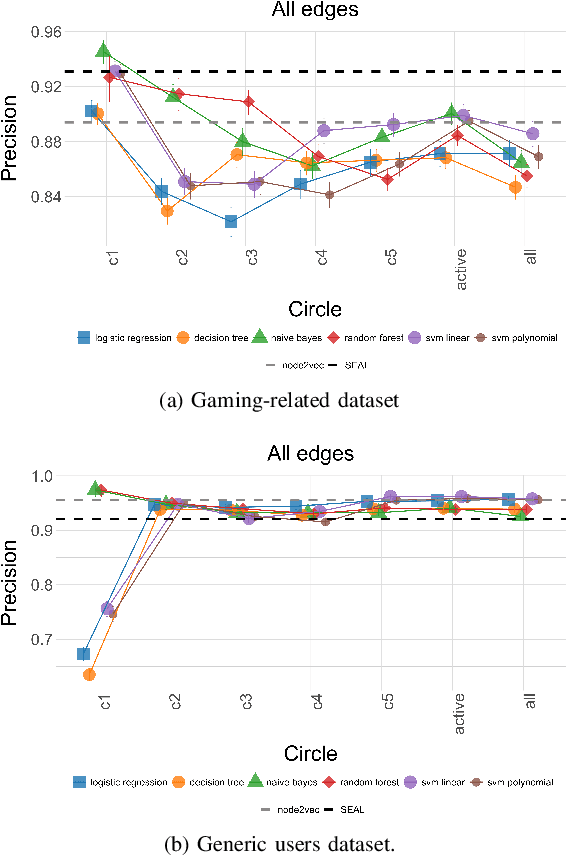
Being able to recommend links between users in online social networks is important for users to connect with like-minded individuals as well as for the platforms themselves and third parties leveraging social media information to grow their business. Predictions are typically based on unsupervised or supervised learning, often leveraging simple yet effective graph topological information, such as the number of common neighbors. However, we argue that richer information about personal social structure of individuals might lead to better predictions. In this paper, we propose to leverage well-established social cognitive theories to improve link prediction performance. According to these theories, individuals arrange their social relationships along, on average, five concentric circles of decreasing intimacy. We postulate that relationships in different circles have different importance in predicting new links. In order to validate this claim, we focus on popular feature-extraction prediction algorithms (both unsupervised and supervised) and we extend them to include social-circles awareness. We validate the prediction performance of these circle-aware algorithms against several benchmarks (including their baseline versions as well as node-embedding- and GNN-based link prediction), leveraging two Twitter datasets comprising a community of video gamers and generic users. We show that social-awareness generally provides significant improvements in the prediction performance, beating also state-of-the-art solutions like node2vec and SEAL, and without increasing the computational complexity. Finally, we show that social-awareness can be used in place of using a classifier (which may be costly or impractical) for targeting a specific category of users.