 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre you serious?: Rhetorical Questions and Sarcasm in Social Media Dialog
Sep 15, 2017
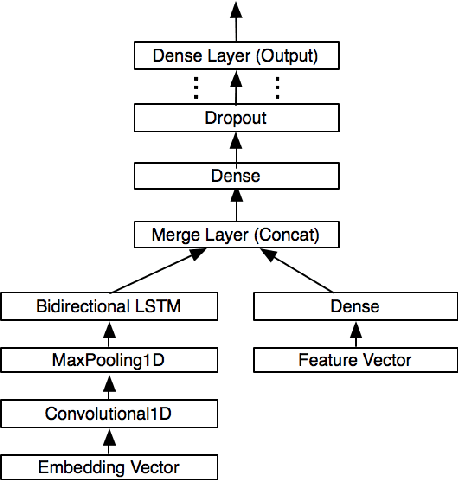

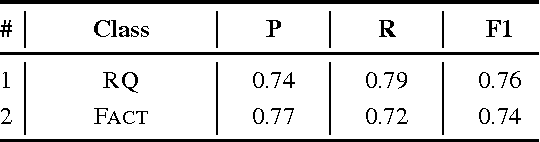
Effective models of social dialog must understand a broad range of rhetorical and figurative devices. Rhetorical questions (RQs) are a type of figurative language whose aim is to achieve a pragmatic goal, such as structuring an argument, being persuasive, emphasizing a point, or being ironic. While there are computational models for other forms of figurative language, rhetorical questions have received little attention to date. We expand a small dataset from previous work, presenting a corpus of 10,270 RQs from debate forums and Twitter that represent different discourse functions. We show that we can clearly distinguish between RQs and sincere questions (0.76 F1). We then show that RQs can be used both sarcastically and non-sarcastically, observing that non-sarcastic (other) uses of RQs are frequently argumentative in forums, and persuasive in tweets. We present experiments to distinguish between these uses of RQs using SVM and LSTM models that represent linguistic features and post-level context, achieving results as high as 0.76 F1 for "sarcastic" and 0.77 F1 for "other" in forums, and 0.83 F1 for both "sarcastic" and "other" in tweets. We supplement our quantitative experiments with an in-depth characterization of the linguistic variation in RQs.
Data-Driven Dialogue Systems for Social Agents
Sep 10, 2017In order to build dialogue systems to tackle the ambitious task of holding social conversations, we argue that we need a data driven approach that includes insight into human conversational chit chat, and which incorporates different natural language processing modules. Our strategy is to analyze and index large corpora of social media data, including Twitter conversations, online debates, dialogues between friends, and blog posts, and then to couple this data retrieval with modules that perform tasks such as sentiment and style analysis, topic modeling, and summarization. We aim for personal assistants that can learn more nuanced human language, and to grow from task-oriented agents to more personable social bots.
Debbie, the Debate Bot of the Future
Sep 10, 2017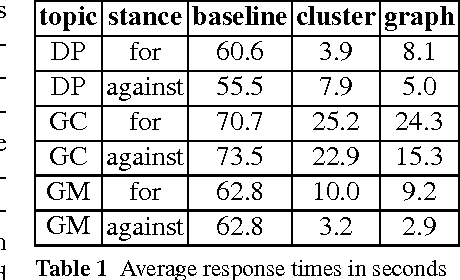
Chatbots are a rapidly expanding application of dialogue systems with companies switching to bot services for customer support, and new applications for users interested in casual conversation. One style of casual conversation is argument, many people love nothing more than a good argument. Moreover, there are a number of existing corpora of argumentative dialogues, annotated for agreement and disagreement, stance, sarcasm and argument quality. This paper introduces Debbie, a novel arguing bot, that selects arguments from conversational corpora, and aims to use them appropriately in context. We present an initial working prototype of Debbie, with some preliminary evaluation and describe future work.
Measuring the Similarity of Sentential Arguments in Dialog
Sep 06, 2017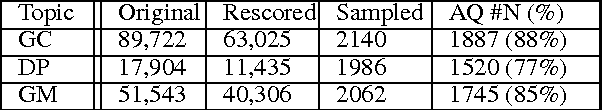
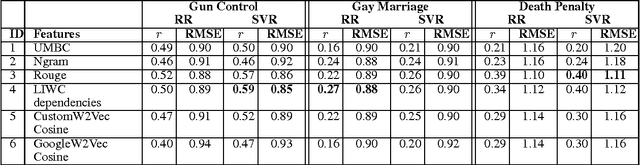

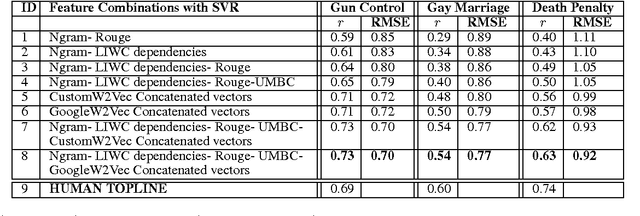
When people converse about social or political topics, similar arguments are often paraphrased by different speakers, across many different conversations. Debate websites produce curated summaries of arguments on such topics; these summaries typically consist of lists of sentences that represent frequently paraphrased propositions, or labels capturing the essence of one particular aspect of an argument, e.g. Morality or Second Amendment. We call these frequently paraphrased propositions ARGUMENT FACETS. Like these curated sites, our goal is to induce and identify argument facets across multiple conversations, and produce summaries. However, we aim to do this automatically. We frame the problem as consisting of two steps: we first extract sentences that express an argument from raw social media dialogs, and then rank the extracted arguments in terms of their similarity to one another. Sets of similar arguments are used to represent argument facets. We show here that we can predict ARGUMENT FACET SIMILARITY with a correlation averaging 0.63 compared to a human topline averaging 0.68 over three debate topics, easily beating several reasonable baselines.