 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights from the Use of Previously Unseen Neural Architecture Search Datasets
Apr 02, 2024The boundless possibility of neural networks which can be used to solve a problem -- each with different performance -- leads to a situation where a Deep Learning expert is required to identify the best neural network. This goes against the hope of removing the need for experts. Neural Architecture Search (NAS) offers a solution to this by automatically identifying the best architecture. However, to date, NAS work has focused on a small set of datasets which we argue are not representative of real-world problems. We introduce eight new datasets created for a series of NAS Challenges: AddNIST, Language, MultNIST, CIFARTile, Gutenberg, Isabella, GeoClassing, and Chesseract. These datasets and challenges are developed to direct attention to issues in NAS development and to encourage authors to consider how their models will perform on datasets unknown to them at development time. We present experimentation using standard Deep Learning methods as well as the best results from challenge participants.
HINT: High-quality INPainting Transformer with Mask-Aware Encoding and Enhanced Attention
Feb 22, 2024Existing image inpainting methods leverage convolution-based downsampling approaches to reduce spatial dimensions. This may result in information loss from corrupted images where the available information is inherently sparse, especially for the scenario of large missing regions. Recent advances in self-attention mechanisms within transformers have led to significant improvements in many computer vision tasks including inpainting. However, limited by the computational costs, existing methods cannot fully exploit the efficacy of long-range modelling capabilities of such models. In this paper, we propose an end-to-end High-quality INpainting Transformer, abbreviated as HINT, which consists of a novel mask-aware pixel-shuffle downsampling module (MPD) to preserve the visible information extracted from the corrupted image while maintaining the integrity of the information available for high-level inferences made within the model. Moreover, we propose a Spatially-activated Channel Attention Layer (SCAL), an efficient self-attention mechanism interpreting spatial awareness to model the corrupted image at multiple scales. To further enhance the effectiveness of SCAL, motivated by recent advanced in speech recognition, we introduce a sandwich structure that places feed-forward networks before and after the SCAL module. We demonstrate the superior performance of HINT compared to contemporary state-of-the-art models on four datasets, CelebA, CelebA-HQ, Places2, and Dunhuang.
INCLG: Inpainting for Non-Cleft Lip Generation with a Multi-Task Image Processing Network
May 17, 2023
We present a software that predicts non-cleft facial images for patients with cleft lip, thereby facilitating the understanding, awareness and discussion of cleft lip surgeries. To protect patients privacy, we design a software framework using image inpainting, which does not require cleft lip images for training, thereby mitigating the risk of model leakage. We implement a novel multi-task architecture that predicts both the non-cleft facial image and facial landmarks, resulting in better performance as evaluated by surgeons. The software is implemented with PyTorch and is usable with consumer-level color images with a fast prediction speed, enabling effective deployment.
Predicting the Performance of a Computing System with Deep Networks
Feb 27, 2023Predicting the performance and energy consumption of computing hardware is critical for many modern applications. This will inform procurement decisions, deployment decisions, and autonomic scaling. Existing approaches to understanding the performance of hardware largely focus around benchmarking -- leveraging standardised workloads which seek to be representative of an end-user's needs. Two key challenges are present; benchmark workloads may not be representative of an end-user's workload, and benchmark scores are not easily obtained for all hardware. Within this paper, we demonstrate the potential to build Deep Learning models to predict benchmark scores for unseen hardware. We undertake our evaluation with the openly available SPEC 2017 benchmark results. We evaluate three different networks, one fully-connected network along with two Convolutional Neural Networks (one bespoke and one ResNet inspired) and demonstrate impressive $R^2$ scores of 0.96, 0.98 and 0.94 respectively.
Siamese Neural Networks for Skin Cancer Classification and New Class Detection using Clinical and Dermoscopic Image Datasets
Dec 12, 2022



Skin cancer is the most common malignancy in the world. Automated skin cancer detection would significantly improve early detection rates and prevent deaths. To help with this aim, a number of datasets have been released which can be used to train Deep Learning systems - these have produced impressive results for classification. However, this only works for the classes they are trained on whilst they are incapable of identifying skin lesions from previously unseen classes, making them unconducive for clinical use. We could look to massively increase the datasets by including all possible skin lesions, though this would always leave out some classes. Instead, we evaluate Siamese Neural Networks (SNNs), which not only allows us to classify images of skin lesions, but also allow us to identify those images which are different from the trained classes - allowing us to determine that an image is not an example of our training classes. We evaluate SNNs on both dermoscopic and clinical images of skin lesions. We obtain top-1 classification accuracy levels of 74.33% and 85.61% on clinical and dermoscopic datasets, respectively. Although this is slightly lower than the state-of-the-art results, the SNN approach has the advantage that it can detect out-of-class examples. Our results highlight the potential of an SNN approach as well as pathways towards future clinical deployment.
A Feasibility Study on Image Inpainting for Non-cleft Lip Generation from Patients with Cleft Lip
Aug 01, 2022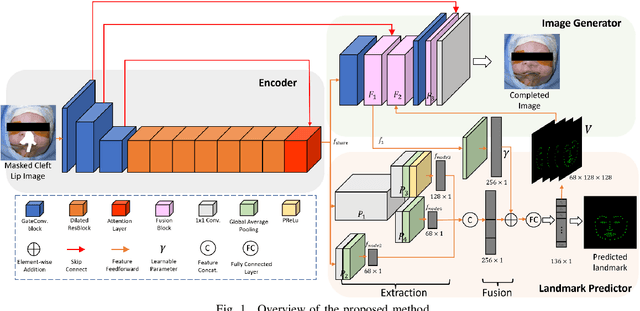
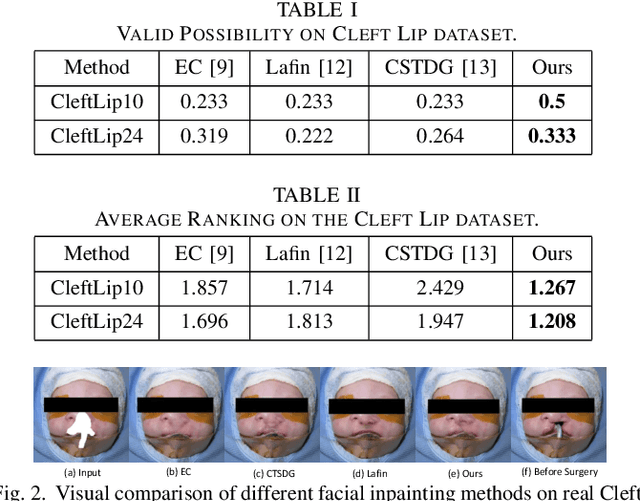
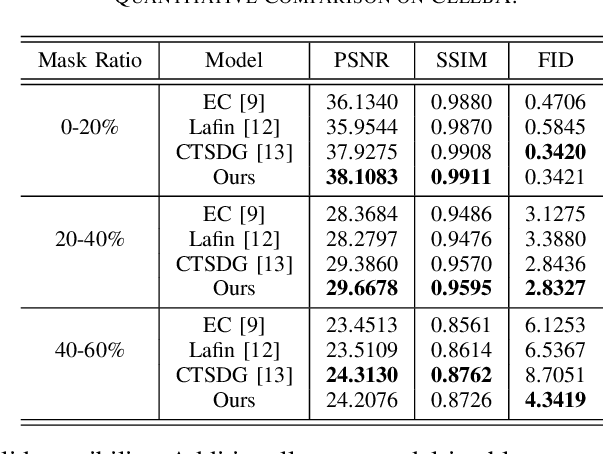
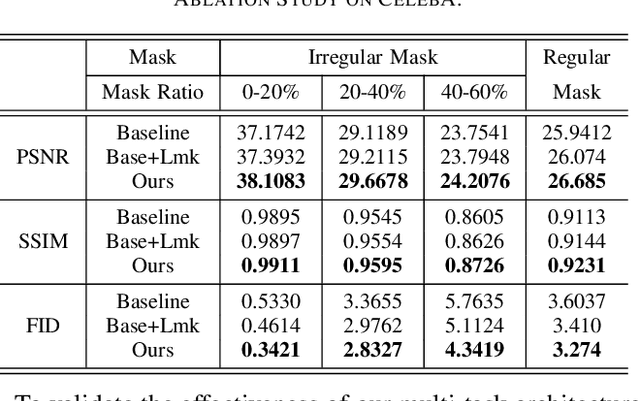
A Cleft lip is a congenital abnormality requiring surgical repair by a specialist. The surgeon must have extensive experience and theoretical knowledge to perform surgery, and Artificial Intelligence (AI) method has been proposed to guide surgeons in improving surgical outcomes. If AI can be used to predict what a repaired cleft lip would look like, surgeons could use it as an adjunct to adjust their surgical technique and improve results. To explore the feasibility of this idea while protecting patient privacy, we propose a deep learning-based image inpainting method that is capable of covering a cleft lip and generating a lip and nose without a cleft. Our experiments are conducted on two real-world cleft lip datasets and are assessed by expert cleft lip surgeons to demonstrate the feasibility of the proposed method.
Long-term Reproducibility for Neural Architecture Search
Jul 18, 2022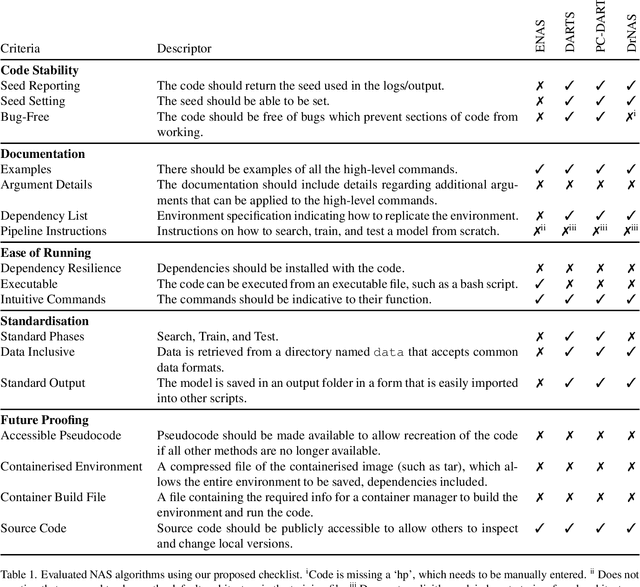
It is a sad reflection of modern academia that code is often ignored after publication -- there is no academic 'kudos' for bug fixes / maintenance. Code is often unavailable or, if available, contains bugs, is incomplete, or relies on out-of-date / unavailable libraries. This has a significant impact on reproducibility and general scientific progress. Neural Architecture Search (NAS) is no exception to this, with some prior work in reproducibility. However, we argue that these do not consider long-term reproducibility issues. We therefore propose a checklist for long-term NAS reproducibility. We evaluate our checklist against common NAS approaches along with proposing how we can retrospectively make these approaches more long-term reproducible.
Detecting Melanoma Fairly: Skin Tone Detection and Debiasing for Skin Lesion Classification
Feb 08, 2022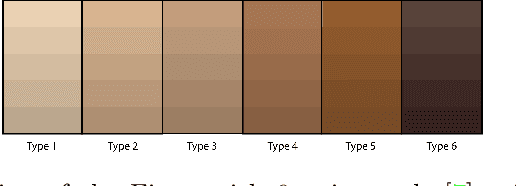

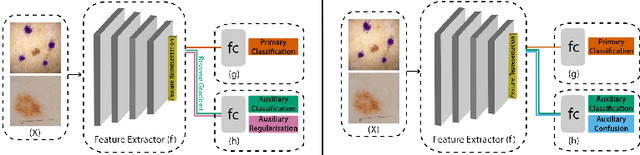
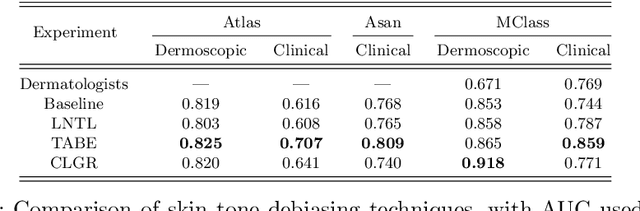
Convolutional Neural Networks have demonstrated human-level performance in the classification of melanoma and other skin lesions, but evident performance disparities between differing skin tones should be addressed before widespread deployment. In this work, we utilise a modified variational autoencoder to uncover skin tone bias in datasets commonly used as benchmarks. We propose an efficient yet effective algorithm for automatically labelling the skin tone of lesion images, and use this to annotate the benchmark ISIC dataset. We subsequently use two leading bias unlearning techniques to mitigate skin tone bias. Our experimental results provide evidence that our skin tone detection algorithm outperforms existing solutions and that unlearning skin tone improves generalisation and can reduce the performance disparity between melanoma detection in lighter and darker skin tones.
"Just Drive": Colour Bias Mitigation for Semantic Segmentation in the Context of Urban Driving
Dec 02, 2021
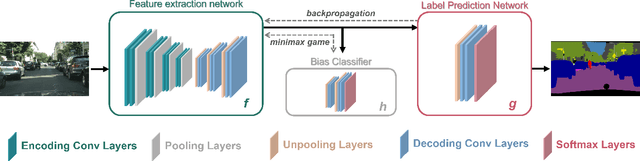
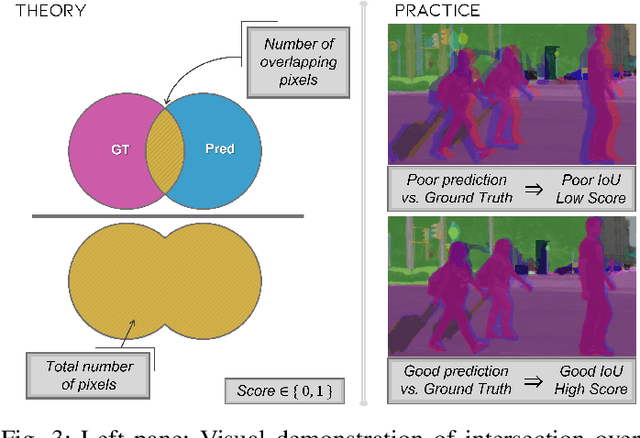
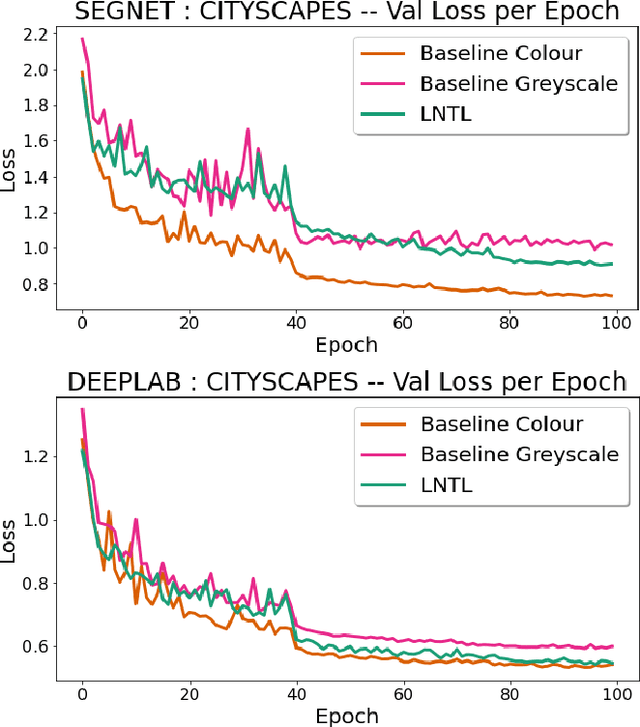
Biases can filter into AI technology without our knowledge. Oftentimes, seminal deep learning networks champion increased accuracy above all else. In this paper, we attempt to alleviate biases encountered by semantic segmentation models in urban driving scenes, via an iteratively trained unlearning algorithm. Convolutional neural networks have been shown to rely on colour and texture rather than geometry. This raises issues when safety-critical applications, such as self-driving cars, encounter images with covariate shift at test time - induced by variations such as lighting changes or seasonality. Conceptual proof of bias unlearning has been shown on simple datasets such as MNIST. However, the strategy has never been applied to the safety-critical domain of pixel-wise semantic segmentation of highly variable training data - such as urban scenes. Trained models for both the baseline and bias unlearning scheme have been tested for performance on colour-manipulated validation sets showing a disparity of up to 85.50% in mIoU from the original RGB images - confirming segmentation networks strongly depend on the colour information in the training data to make their classification. The bias unlearning scheme shows improvements of handling this covariate shift of up to 61% in the best observed case - and performs consistently better at classifying the "human" and "vehicle" classes compared to the baseline model.
Skin Deep Unlearning: Artefact and Instrument Debiasing in the Context of Melanoma Classification
Sep 23, 2021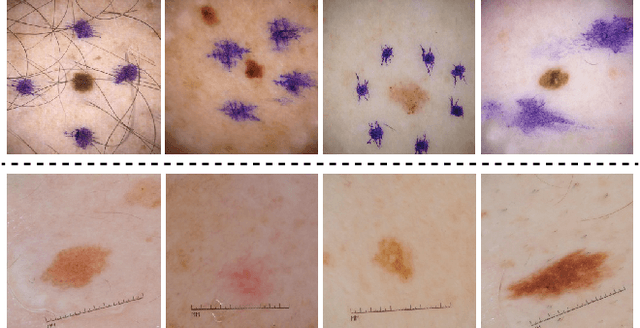
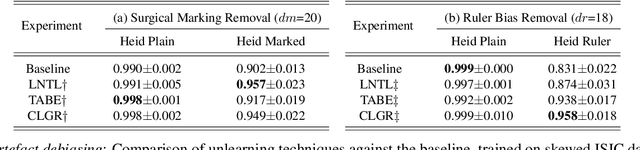
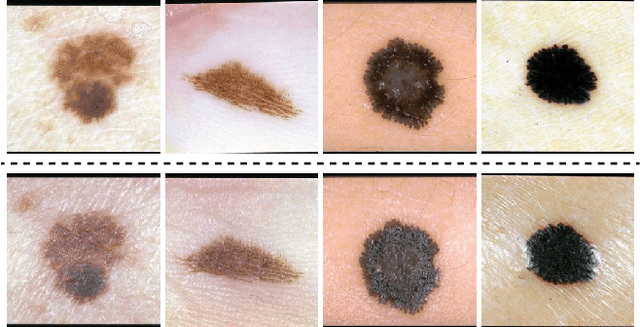
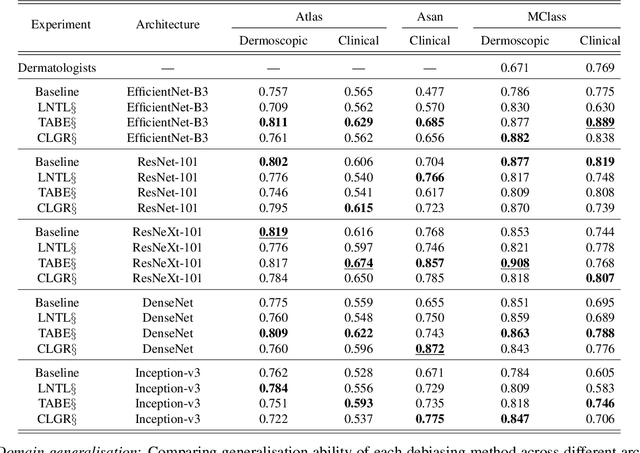
Convolutional Neural Networks have demonstrated dermatologist-level performance in the classification of melanoma and other skin lesions, but prediction irregularities due to biases seen within the training data are an issue that should be addressed before widespread deployment is possible. In this work, we robustly remove bias and spurious variation from an automated melanoma classification pipeline using two leading bias unlearning techniques. We show that the biases introduced by surgical markings and rulers presented in previous studies can be reasonably mitigated using these bias removal methods. We also demonstrate the generalisation benefits of unlearning spurious variation relating to the imaging instrument used to capture lesion images. Contributions of this work include the application of different debiasing techniques for artefact bias removal and the concept of instrument bias unlearning for domain generalisation in melanoma detection. Our experimental results provide evidence that the effects of each of the aforementioned biases are notably reduced, with different debiasing techniques excelling at different tasks.