 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Search of Insights, Not Magic Bullets: Towards Demystification of the Model Selection Dilemma in Heterogeneous Treatment Effect Estimation
Feb 06, 2023



Personalized treatment effect estimates are often of interest in high-stakes applications -- thus, before deploying a model estimating such effects in practice, one needs to be sure that the best candidate from the ever-growing machine learning toolbox for this task was chosen. Unfortunately, due to the absence of counterfactual information in practice, it is usually not possible to rely on standard validation metrics for doing so, leading to a well-known model selection dilemma in the treatment effect estimation literature. While some solutions have recently been investigated, systematic understanding of the strengths and weaknesses of different model selection criteria is still lacking. In this paper, instead of attempting to declare a global `winner', we therefore empirically investigate success- and failure modes of different selection criteria. We highlight that there is a complex interplay between selection strategies, candidate estimators and the DGP used for testing, and provide interesting insights into the relative (dis)advantages of different criteria alongside desiderata for the design of further illuminating empirical studies in this context.
Adaptively Identifying Patient Populations With Treatment Benefit in Clinical Trials
Aug 11, 2022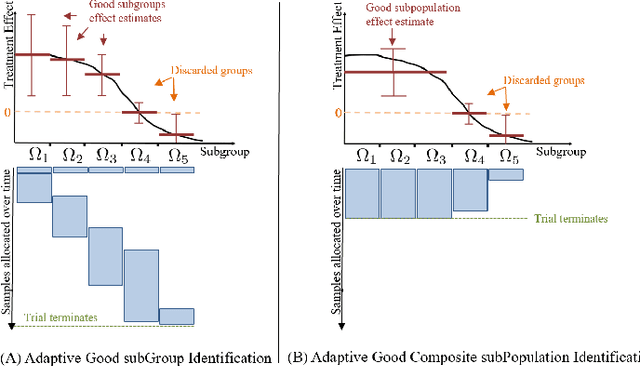
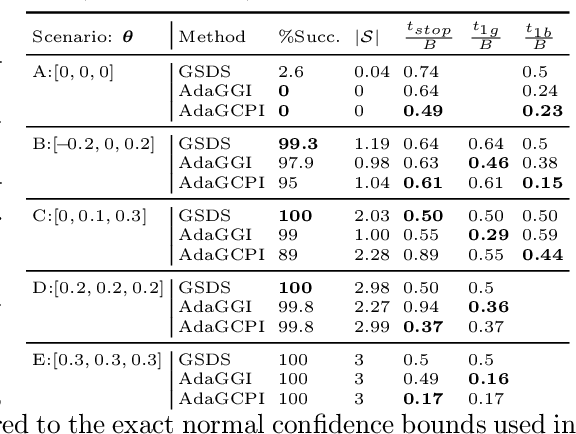
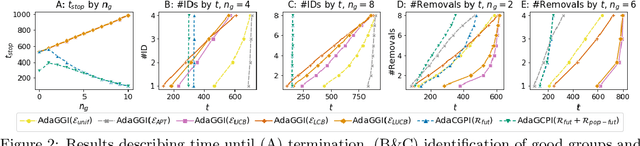
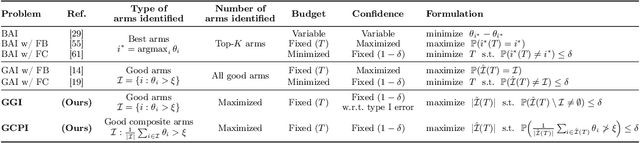
We study the problem of adaptively identifying patient subpopulations that benefit from a given treatment during a confirmatory clinical trial. This type of adaptive clinical trial, often referred to as adaptive enrichment design, has been thoroughly studied in biostatistics with a focus on a limited number of subgroups (typically two) which make up (sub)populations, and a small number of interim analysis points. In this paper, we aim to relax classical restrictions on such designs and investigate how to incorporate ideas from the recent machine learning literature on adaptive and online experimentation to make trials more flexible and efficient. We find that the unique characteristics of the subpopulation selection problem -- most importantly that (i) one is usually interested in finding subpopulations with any treatment benefit (and not necessarily the single subgroup with largest effect) given a limited budget and that (ii) effectiveness only has to be demonstrated across the subpopulation on average -- give rise to interesting challenges and new desiderata when designing algorithmic solutions. Building on these findings, we propose AdaGGI and AdaGCPI, two meta-algorithms for subpopulation construction, which focus on identifying good subgroups and good composite subpopulations, respectively. We empirically investigate their performance across a range of simulation scenarios and derive insights into their (dis)advantages across different settings.
Benchmarking Heterogeneous Treatment Effect Models through the Lens of Interpretability
Jun 16, 2022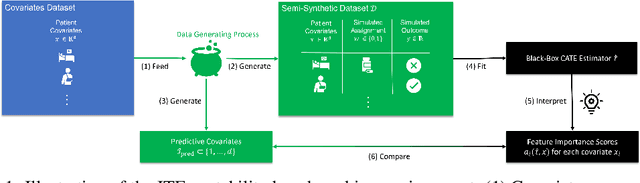

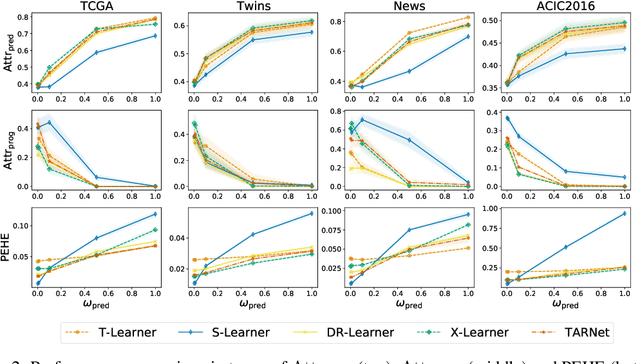
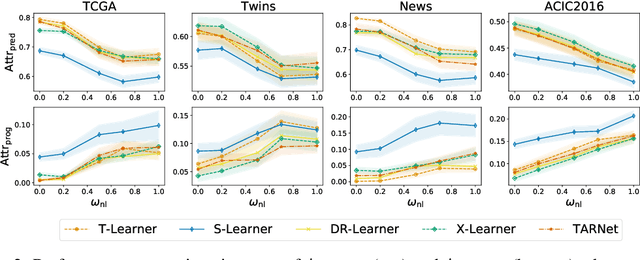
Estimating personalized effects of treatments is a complex, yet pervasive problem. To tackle it, recent developments in the machine learning (ML) literature on heterogeneous treatment effect estimation gave rise to many sophisticated, but opaque, tools: due to their flexibility, modularity and ability to learn constrained representations, neural networks in particular have become central to this literature. Unfortunately, the assets of such black boxes come at a cost: models typically involve countless nontrivial operations, making it difficult to understand what they have learned. Yet, understanding these models can be crucial -- in a medical context, for example, discovered knowledge on treatment effect heterogeneity could inform treatment prescription in clinical practice. In this work, we therefore use post-hoc feature importance methods to identify features that influence the model's predictions. This allows us to evaluate treatment effect estimators along a new and important dimension that has been overlooked in previous work: We construct a benchmarking environment to empirically investigate the ability of personalized treatment effect models to identify predictive covariates -- covariates that determine differential responses to treatment. Our benchmarking environment then enables us to provide new insight into the strengths and weaknesses of different types of treatment effects models as we modulate different challenges specific to treatment effect estimation -- e.g. the ratio of prognostic to predictive information, the possible nonlinearity of potential outcomes and the presence and type of confounding.
HyperImpute: Generalized Iterative Imputation with Automatic Model Selection
Jun 15, 2022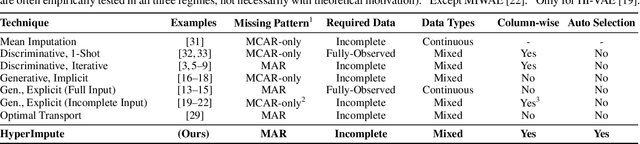
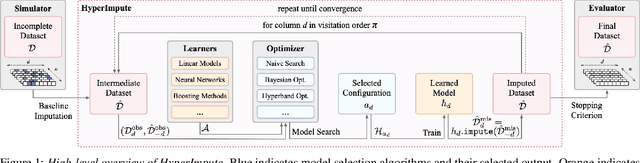
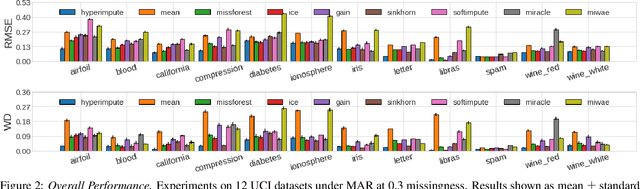
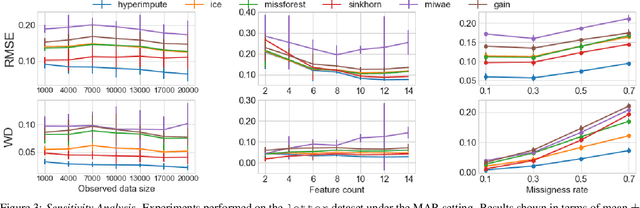
Consider the problem of imputing missing values in a dataset. One the one hand, conventional approaches using iterative imputation benefit from the simplicity and customizability of learning conditional distributions directly, but suffer from the practical requirement for appropriate model specification of each and every variable. On the other hand, recent methods using deep generative modeling benefit from the capacity and efficiency of learning with neural network function approximators, but are often difficult to optimize and rely on stronger data assumptions. In this work, we study an approach that marries the advantages of both: We propose *HyperImpute*, a generalized iterative imputation framework for adaptively and automatically configuring column-wise models and their hyperparameters. Practically, we provide a concrete implementation with out-of-the-box learners, optimizers, simulators, and extensible interfaces. Empirically, we investigate this framework via comprehensive experiments and sensitivities on a variety of public datasets, and demonstrate its ability to generate accurate imputations relative to a strong suite of benchmarks. Contrary to recent work, we believe our findings constitute a strong defense of the iterative imputation paradigm.
Inverse Online Learning: Understanding Non-Stationary and Reactionary Policies
Mar 14, 2022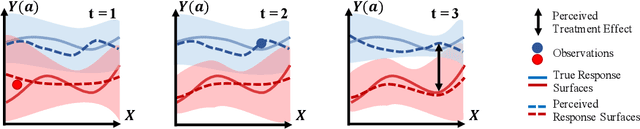
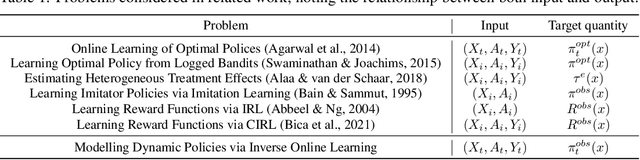
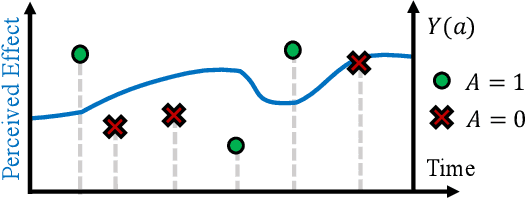
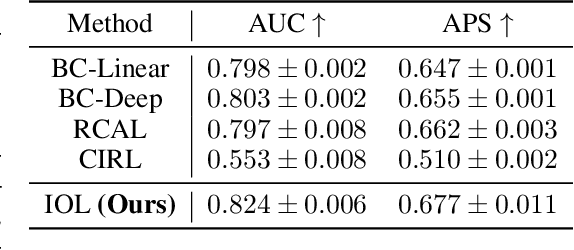
Human decision making is well known to be imperfect and the ability to analyse such processes individually is crucial when attempting to aid or improve a decision-maker's ability to perform a task, e.g. to alert them to potential biases or oversights on their part. To do so, it is necessary to develop interpretable representations of how agents make decisions and how this process changes over time as the agent learns online in reaction to the accrued experience. To then understand the decision-making processes underlying a set of observed trajectories, we cast the policy inference problem as the inverse to this online learning problem. By interpreting actions within a potential outcomes framework, we introduce a meaningful mapping based on agents choosing an action they believe to have the greatest treatment effect. We introduce a practical algorithm for retrospectively estimating such perceived effects, alongside the process through which agents update them, using a novel architecture built upon an expressive family of deep state-space models. Through application to the analysis of UNOS organ donation acceptance decisions, we demonstrate that our approach can bring valuable insights into the factors that govern decision processes and how they change over time.
Combining Observational and Randomized Data for Estimating Heterogeneous Treatment Effects
Feb 25, 2022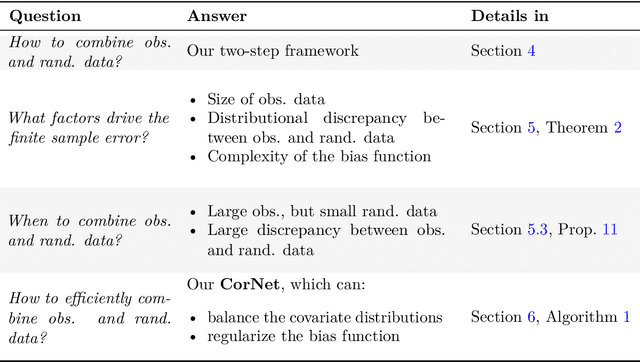
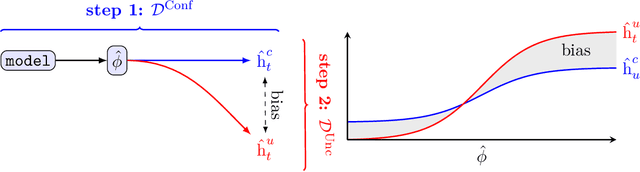
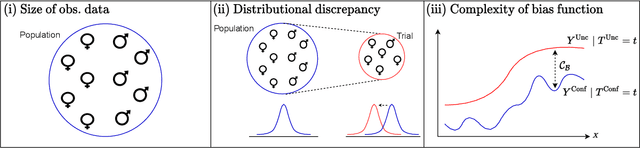

Estimating heterogeneous treatment effects is an important problem across many domains. In order to accurately estimate such treatment effects, one typically relies on data from observational studies or randomized experiments. Currently, most existing works rely exclusively on observational data, which is often confounded and, hence, yields biased estimates. While observational data is confounded, randomized data is unconfounded, but its sample size is usually too small to learn heterogeneous treatment effects. In this paper, we propose to estimate heterogeneous treatment effects by combining large amounts of observational data and small amounts of randomized data via representation learning. In particular, we introduce a two-step framework: first, we use observational data to learn a shared structure (in form of a representation); and then, we use randomized data to learn the data-specific structures. We analyze the finite sample properties of our framework and compare them to several natural baselines. As such, we derive conditions for when combining observational and randomized data is beneficial, and for when it is not. Based on this, we introduce a sample-efficient algorithm, called CorNet. We use extensive simulation studies to verify the theoretical properties of CorNet and multiple real-world datasets to demonstrate our method's superiority compared to existing methods.
Disentangled Counterfactual Recurrent Networks for Treatment Effect Inference over Time
Dec 07, 2021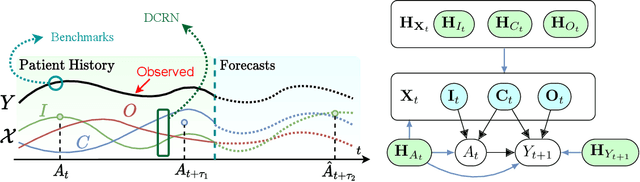
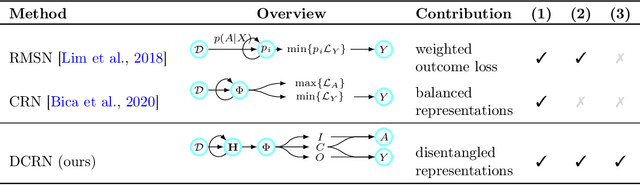
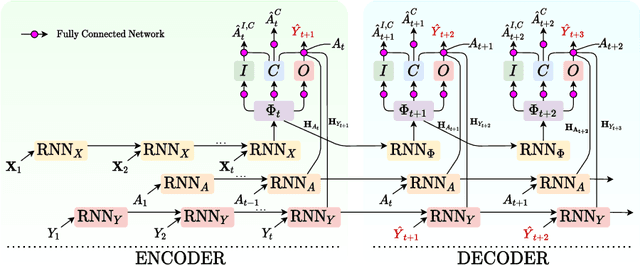

Choosing the best treatment-plan for each individual patient requires accurate forecasts of their outcome trajectories as a function of the treatment, over time. While large observational data sets constitute rich sources of information to learn from, they also contain biases as treatments are rarely assigned randomly in practice. To provide accurate and unbiased forecasts, we introduce the Disentangled Counterfactual Recurrent Network (DCRN), a novel sequence-to-sequence architecture that estimates treatment outcomes over time by learning representations of patient histories that are disentangled into three separate latent factors: a treatment factor, influencing only treatment selection; an outcome factor, influencing only the outcome; and a confounding factor, influencing both. With an architecture that is completely inspired by the causal structure of treatment influence over time, we advance forecast accuracy and disease understanding, as our architecture allows for practitioners to infer which patient features influence which part in a patient's trajectory, contrasting other approaches in this domain. We demonstrate that DCRN outperforms current state-of-the-art methods in forecasting treatment responses, on both real and simulated data.
SurvITE: Learning Heterogeneous Treatment Effects from Time-to-Event Data
Oct 26, 2021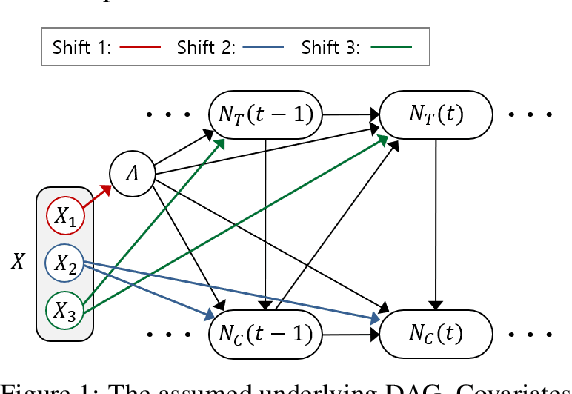
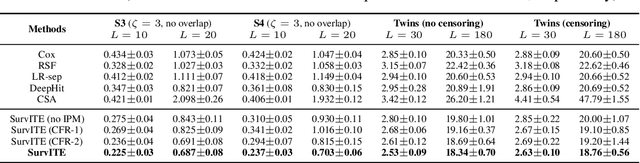
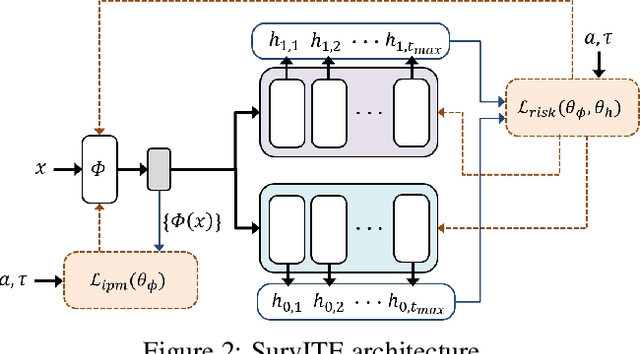
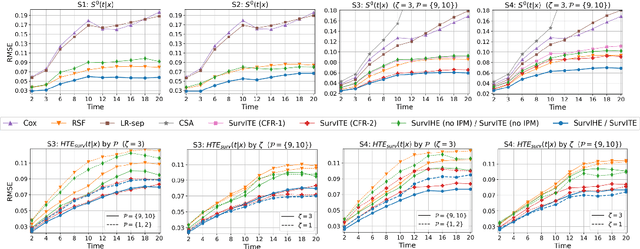
We study the problem of inferring heterogeneous treatment effects from time-to-event data. While both the related problems of (i) estimating treatment effects for binary or continuous outcomes and (ii) predicting survival outcomes have been well studied in the recent machine learning literature, their combination -- albeit of high practical relevance -- has received considerably less attention. With the ultimate goal of reliably estimating the effects of treatments on instantaneous risk and survival probabilities, we focus on the problem of learning (discrete-time) treatment-specific conditional hazard functions. We find that unique challenges arise in this context due to a variety of covariate shift issues that go beyond a mere combination of well-studied confounding and censoring biases. We theoretically analyse their effects by adapting recent generalization bounds from domain adaptation and treatment effect estimation to our setting and discuss implications for model design. We use the resulting insights to propose a novel deep learning method for treatment-specific hazard estimation based on balancing representations. We investigate performance across a range of experimental settings and empirically confirm that our method outperforms baselines by addressing covariate shifts from various sources.
Doing Great at Estimating CATE? On the Neglected Assumptions in Benchmark Comparisons of Treatment Effect Estimators
Jul 28, 2021
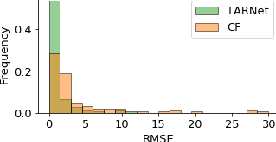
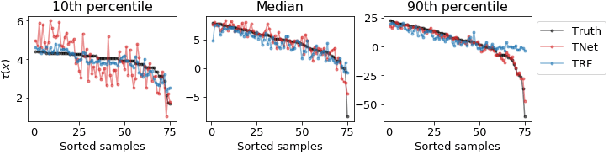

The machine learning toolbox for estimation of heterogeneous treatment effects from observational data is expanding rapidly, yet many of its algorithms have been evaluated only on a very limited set of semi-synthetic benchmark datasets. In this paper, we show that even in arguably the simplest setting -- estimation under ignorability assumptions -- the results of such empirical evaluations can be misleading if (i) the assumptions underlying the data-generating mechanisms in benchmark datasets and (ii) their interplay with baseline algorithms are inadequately discussed. We consider two popular machine learning benchmark datasets for evaluation of heterogeneous treatment effect estimators -- the IHDP and ACIC2016 datasets -- in detail. We identify problems with their current use and highlight that the inherent characteristics of the benchmark datasets favor some algorithms over others -- a fact that is rarely acknowledged but of immense relevance for interpretation of empirical results. We close by discussing implications and possible next steps.
On Inductive Biases for Heterogeneous Treatment Effect Estimation
Jun 07, 2021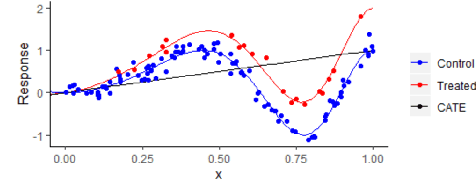
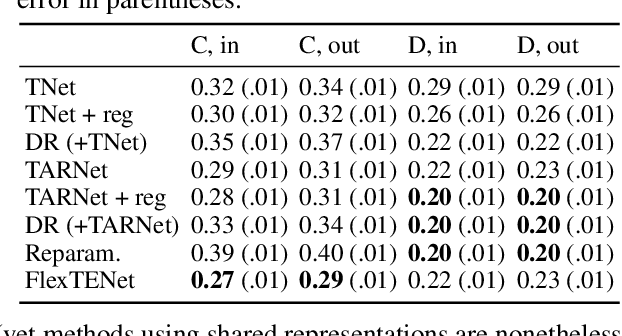
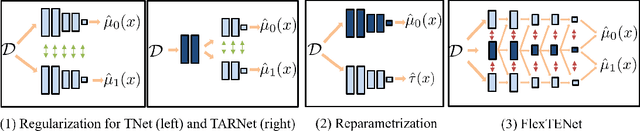
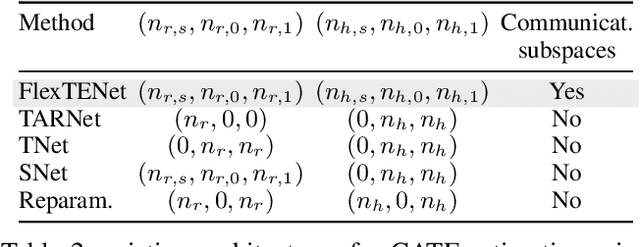
We investigate how to exploit structural similarities of an individual's potential outcomes (POs) under different treatments to obtain better estimates of conditional average treatment effects in finite samples. Especially when it is unknown whether a treatment has an effect at all, it is natural to hypothesize that the POs are similar - yet, some existing strategies for treatment effect estimation employ regularization schemes that implicitly encourage heterogeneity even when it does not exist and fail to fully make use of shared structure. In this paper, we investigate and compare three end-to-end learning strategies to overcome this problem - based on regularization, reparametrization and a flexible multi-task architecture - each encoding inductive bias favoring shared behavior across POs. To build understanding of their relative strengths, we implement all strategies using neural networks and conduct a wide range of semi-synthetic experiments. We observe that all three approaches can lead to substantial improvements upon numerous baselines and gain insight into performance differences across various experimental settings.