 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAli Farhadi
Learning to Learn How to Learn: Self-Adaptive Visual Navigation Using Meta-Learning
Mar 26, 2019
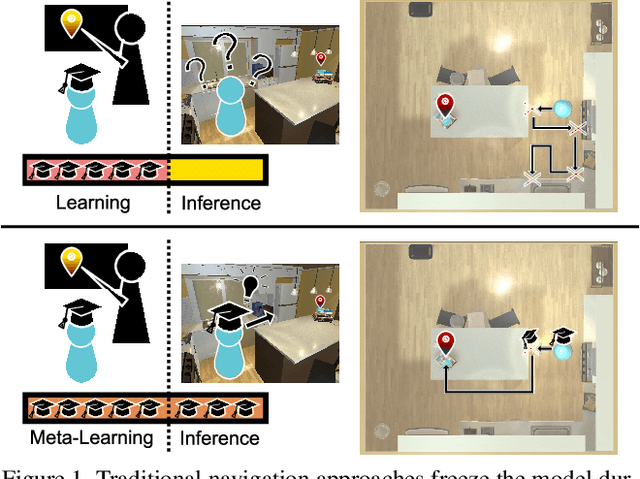
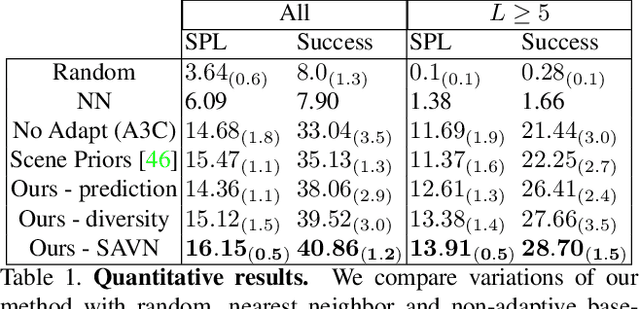
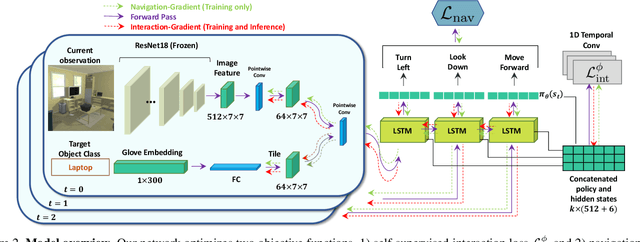
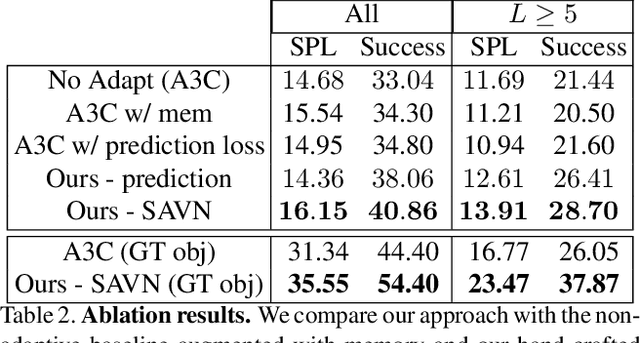
Learning is an inherently continuous phenomenon. When humans learn a new task there is no explicit distinction between training and inference. As we learn a task, we keep learning about it while performing the task. What we learn and how we learn it varies during different stages of learning. Learning how to learn and adapt is a key property that enables us to generalize effortlessly to new settings. This is in contrast with conventional settings in machine learning where a trained model is frozen during inference. In this paper we study the problem of learning to learn at both training and test time in the context of visual navigation. A fundamental challenge in navigation is generalization to unseen scenes. In this paper we propose a self-adaptive visual navigation method (SAVN) which learns to adapt to new environments without any explicit supervision. Our solution is a meta-reinforcement learning approach where an agent learns a self-supervised interaction loss that encourages effective navigation. Our experiments, performed in the AI2-THOR framework, show major improvements in both success rate and SPL for visual navigation in novel scenes. Our code and data are available at: https://github.com/allenai/savn .
What Should I Do Now? Marrying Reinforcement Learning and Symbolic Planning
Jan 06, 2019
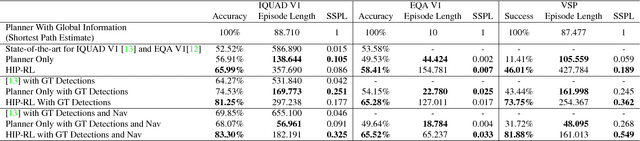
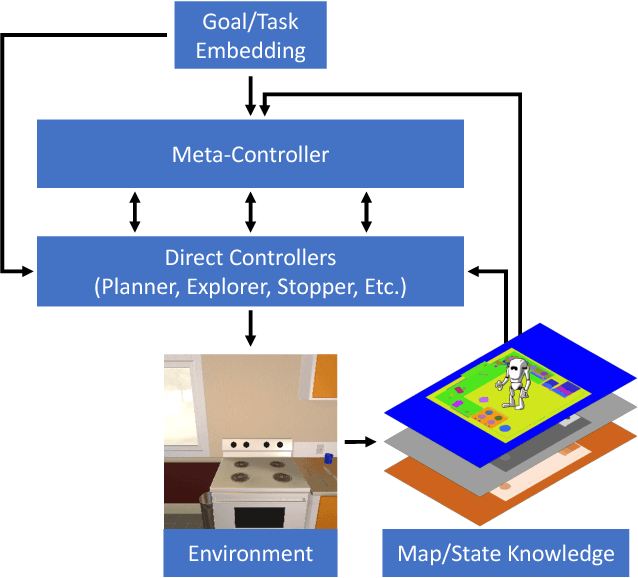
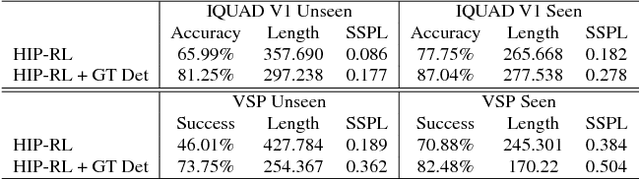
Long-term planning poses a major difficulty to many reinforcement learning algorithms. This problem becomes even more pronounced in dynamic visual environments. In this work we propose Hierarchical Planning and Reinforcement Learning (HIP-RL), a method for merging the benefits and capabilities of Symbolic Planning with the learning abilities of Deep Reinforcement Learning. We apply HIPRL to the complex visual tasks of interactive question answering and visual semantic planning and achieve state-of-the-art results on three challenging datasets all while taking fewer steps at test time and training in fewer iterations. Sample results can be found at youtu.be/0TtWJ_0mPfI
ELASTIC: Improving CNNs with Instance Specific Scaling Policies
Dec 13, 2018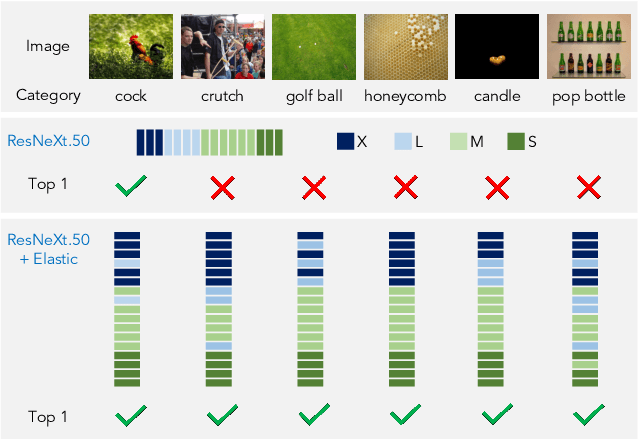


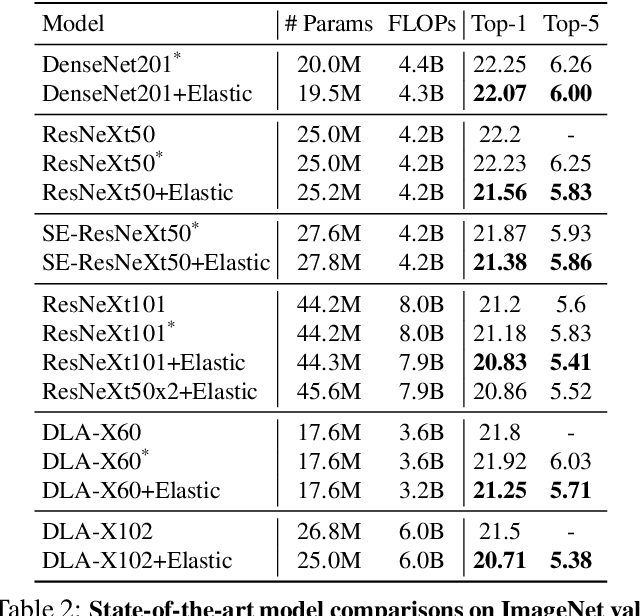
Scale variation has been a challenge from traditional to modern approaches in computer vision. Most solutions to scale issues have similar theme: a set of intuitive and manually designed policies that are generic and fixed (e.g. SIFT or feature pyramid). We argue that the scale policy should be learned from data. In this paper, we introduce ELASTIC, a simple, efficient and yet very effective approach to learn instance-specific scale policy from data. We formulate the scaling policy as a non-linear function inside the network's structure that (a) is learned from data, (b) is instance specific, (c) does not add extra computation, and (d) can be applied on any network architecture. We applied ELASTIC to several state-of-the-art network architectures and showed consistent improvement without extra (sometimes even lower) computation on ImageNet classification, MSCOCO multi-label classification, and PASCAL VOC semantic segmentation. Our results show major improvement for images with scale challenges e.g. images with several small objects or objects with large scale variations. Our code and models will be publicly available soon.
From Recognition to Cognition: Visual Commonsense Reasoning
Nov 27, 2018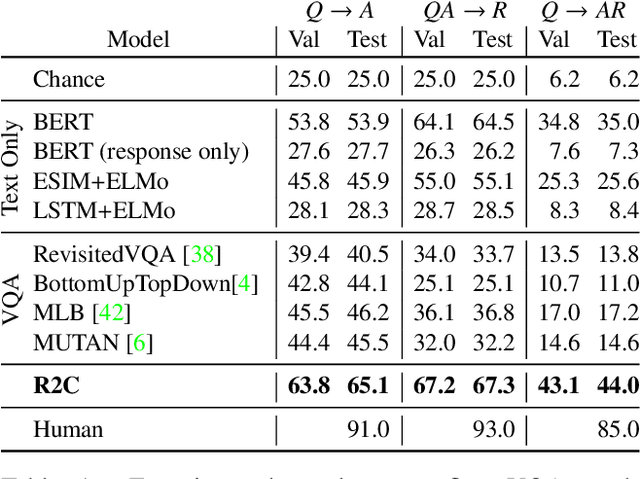
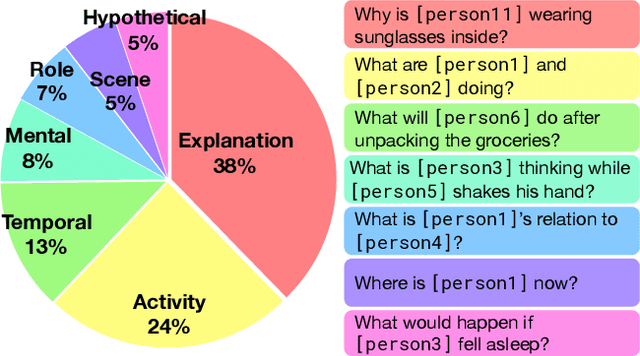
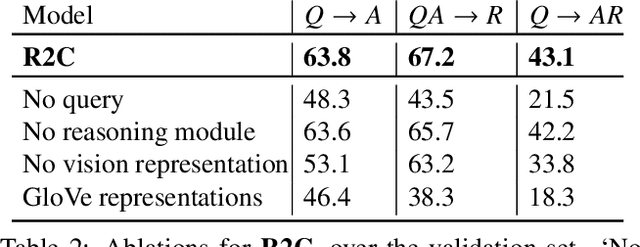

Visual understanding goes well beyond object recognition. With one glance at an image, we can effortlessly imagine the world beyond the pixels: for instance, we can infer people's actions, goals, and mental states. While this task is easy for humans, it is tremendously difficult for today's vision systems, requiring higher-order cognition and commonsense reasoning about the world. In this paper, we formalize this task as Visual Commonsense Reasoning. In addition to answering challenging visual questions expressed in natural language, a model must provide a rationale explaining why its answer is true. We introduce a new dataset, VCR, consisting of 290k multiple choice QA problems derived from 110k movie scenes. The key recipe to generating non-trivial and high-quality problems at scale is Adversarial Matching, a new approach to transform rich annotations into multiple choice questions with minimal bias. To move towards cognition-level image understanding, we present a new reasoning engine, called Recognition to Cognition Networks (R2C), that models the necessary layered inferences for grounding, contextualization, and reasoning. Experimental results show that while humans find VCR easy (over 90% accuracy), state-of-the-art models struggle (~45%). Our R2C helps narrow this gap (~65%); still, the challenge is far from solved, and we provide analysis that suggests avenues for future work.
Visual Semantic Navigation using Scene Priors
Oct 15, 2018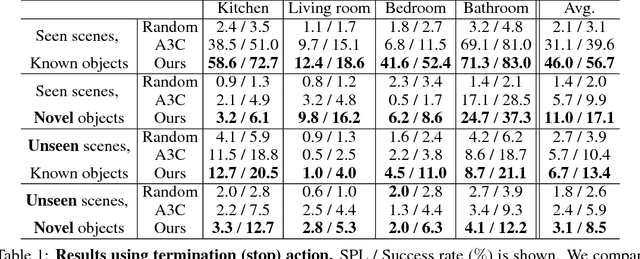
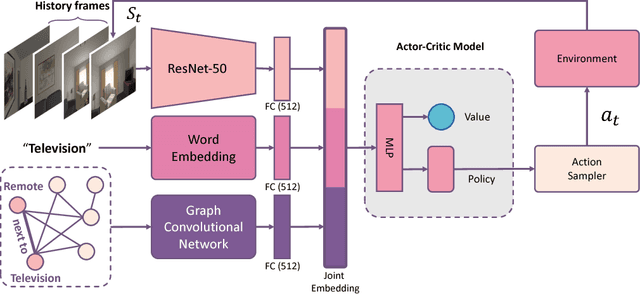
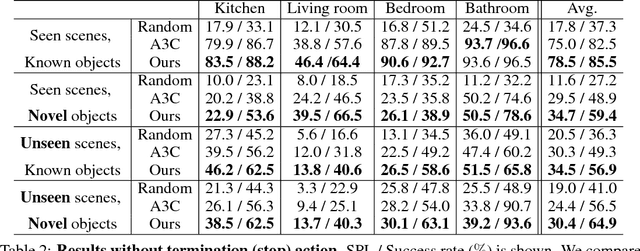
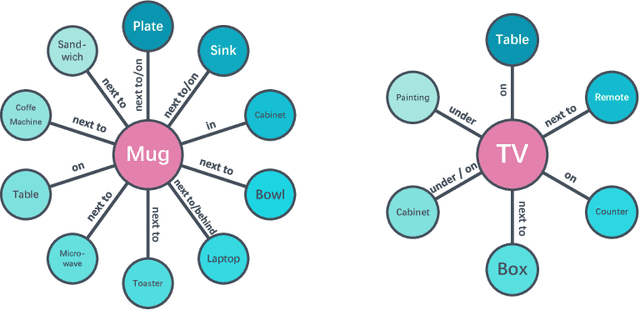
How do humans navigate to target objects in novel scenes? Do we use the semantic/functional priors we have built over years to efficiently search and navigate? For example, to search for mugs, we search cabinets near the coffee machine and for fruits we try the fridge. In this work, we focus on incorporating semantic priors in the task of semantic navigation. We propose to use Graph Convolutional Networks for incorporating the prior knowledge into a deep reinforcement learning framework. The agent uses the features from the knowledge graph to predict the actions. For evaluation, we use the AI2-THOR framework. Our experiments show how semantic knowledge improves performance significantly. More importantly, we show improvement in generalization to unseen scenes and/or objects. The supplementary video can be accessed at the following link: https://youtu.be/otKjuO805dE .
Phrase-Indexed Question Answering: A New Challenge for Scalable Document Comprehension
Sep 26, 2018
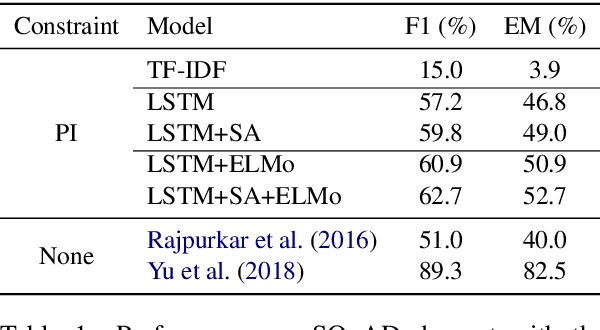

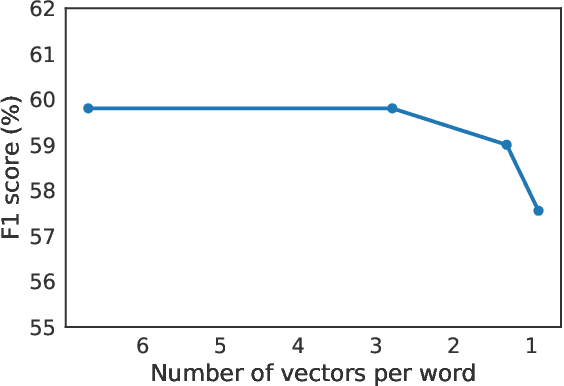
We formalize a new modular variant of current question answering tasks by enforcing complete independence of the document encoder from the question encoder. This formulation addresses a key challenge in machine comprehension by requiring a standalone representation of the document discourse. It additionally leads to a significant scalability advantage since the encoding of the answer candidate phrases in the document can be pre-computed and indexed offline for efficient retrieval. We experiment with baseline models for the new task, which achieve a reasonable accuracy but significantly underperform unconstrained QA models. We invite the QA research community to engage in Phrase-Indexed Question Answering (PIQA, pika) for closing the gap. The leaderboard is at: nlp.cs.washington.edu/piqa
PhotoShape: Photorealistic Materials for Large-Scale Shape Collections
Sep 26, 2018
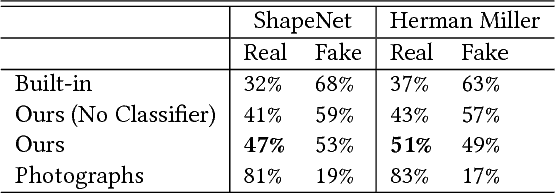


Existing online 3D shape repositories contain thousands of 3D models but lack photorealistic appearance. We present an approach to automatically assign high-quality, realistic appearance models to large scale 3D shape collections. The key idea is to jointly leverage three types of online data -- shape collections, material collections, and photo collections, using the photos as reference to guide assignment of materials to shapes. By generating a large number of synthetic renderings, we train a convolutional neural network to classify materials in real photos, and employ 3D-2D alignment techniques to transfer materials to different parts of each shape model. Our system produces photorealistic, relightable, 3D shapes (PhotoShapes).
IQA: Visual Question Answering in Interactive Environments
Sep 06, 2018
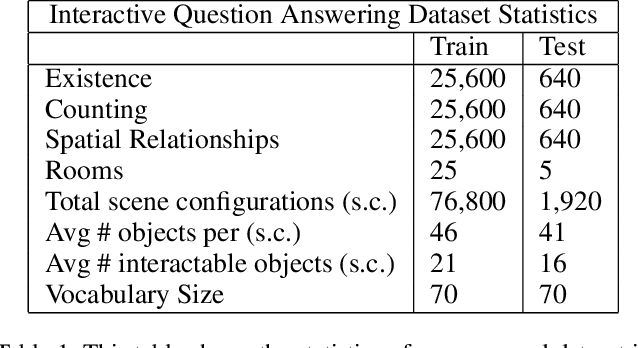
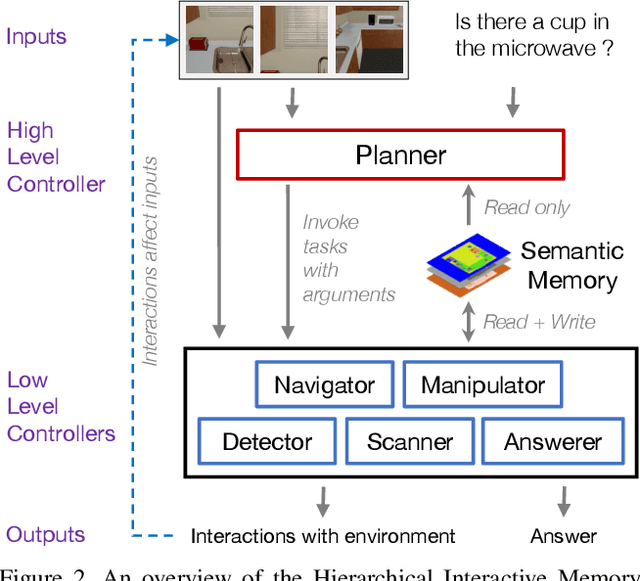

We introduce Interactive Question Answering (IQA), the task of answering questions that require an autonomous agent to interact with a dynamic visual environment. IQA presents the agent with a scene and a question, like: "Are there any apples in the fridge?" The agent must navigate around the scene, acquire visual understanding of scene elements, interact with objects (e.g. open refrigerators) and plan for a series of actions conditioned on the question. Popular reinforcement learning approaches with a single controller perform poorly on IQA owing to the large and diverse state space. We propose the Hierarchical Interactive Memory Network (HIMN), consisting of a factorized set of controllers, allowing the system to operate at multiple levels of temporal abstraction. To evaluate HIMN, we introduce IQUAD V1, a new dataset built upon AI2-THOR, a simulated photo-realistic environment of configurable indoor scenes with interactive objects (code and dataset available at https://github.com/danielgordon10/thor-iqa-cvpr-2018). IQUAD V1 has 75,000 questions, each paired with a unique scene configuration. Our experiments show that our proposed model outperforms popular single controller based methods on IQUAD V1. For sample questions and results, please view our video: https://youtu.be/pXd3C-1jr98
DOCK: Detecting Objects by transferring Common-sense Knowledge
Jul 31, 2018
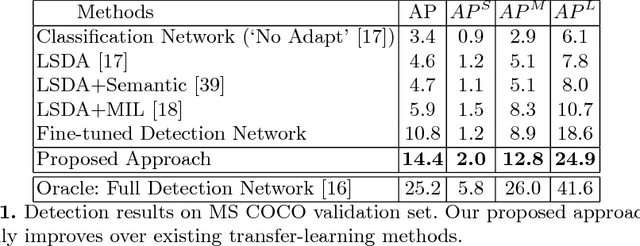


We present a scalable approach for Detecting Objects by transferring Common-sense Knowledge (DOCK) from source to target categories. In our setting, the training data for the source categories have bounding box annotations, while those for the target categories only have image-level annotations. Current state-of-the-art approaches focus on image-level visual or semantic similarity to adapt a detector trained on the source categories to the new target categories. In contrast, our key idea is to (i) use similarity not at the image-level, but rather at the region-level, and (ii) leverage richer common-sense (based on attribute, spatial, etc.) to guide the algorithm towards learning the correct detections. We acquire such common-sense cues automatically from readily-available knowledge bases without any extra human effort. On the challenging MS COCO dataset, we find that common-sense knowledge can substantially improve detection performance over existing transfer-learning baselines.