 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient OCT Image Segmentation Using Neural Architecture Search
Jul 28, 2020


In this work, we propose a Neural Architecture Search (NAS) for retinal layer segmentation in Optical Coherence Tomography (OCT) scans. We incorporate the Unet architecture in the NAS framework as its backbone for the segmentation of the retinal layers in our collected and pre-processed OCT image dataset. At the pre-processing stage, we conduct super resolution and image processing techniques on the raw OCT scans to improve the quality of the raw images. For our search strategy, different primitive operations are suggested to find the down- & up-sampling cell blocks, and the binary gate method is applied to make the search strategy practical for the task in hand. We empirically evaluated our method on our in-house OCT dataset. The experimental results demonstrate that the self-adapting NAS-Unet architecture substantially outperformed the competitive human-designed architecture by achieving 95.4% in mean Intersection over Union metric and 78.7% in Dice similarity coefficient.
Quality Guided Sketch-to-Photo Image Synthesis
Apr 20, 2020
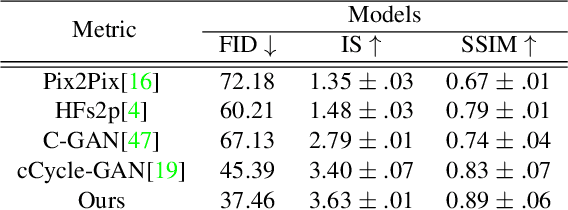
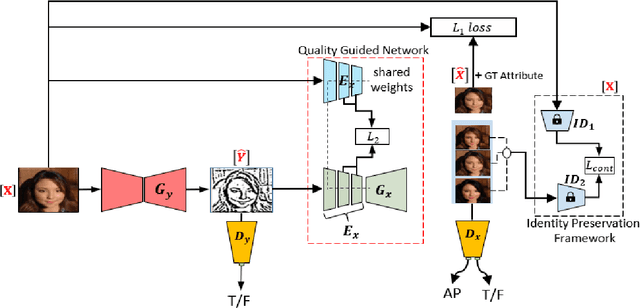
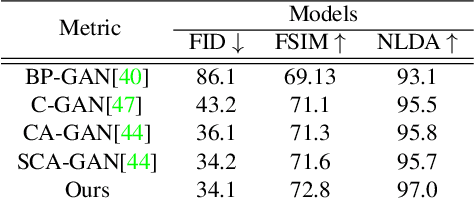
Facial sketches drawn by artists are widely used for visual identification applications and mostly by law enforcement agencies, but the quality of these sketches depend on the ability of the artist to clearly replicate all the key facial features that could aid in capturing the true identity of a subject. Recent works have attempted to synthesize these sketches into plausible visual images to improve visual recognition and identification. However, synthesizing photo-realistic images from sketches proves to be an even more challenging task, especially for sensitive applications such as suspect identification. In this work, we propose a novel approach that adopts a generative adversarial network that synthesizes a single sketch into multiple synthetic images with unique attributes like hair color, sex, etc. We incorporate a hybrid discriminator which performs attribute classification of multiple target attributes, a quality guided encoder that minimizes the perceptual dissimilarity of the latent space embedding of the synthesized and real image at different layers in the network and an identity preserving network that maintains the identity of the synthesised image throughout the training process. Our approach is aimed at improving the visual appeal of the synthesised images while incorporating multiple attribute assignment to the generator without compromising the identity of the synthesised image. We synthesised sketches using XDOG filter for the CelebA, WVU Multi-modal and CelebA-HQ datasets and from an auxiliary generator trained on sketches from CUHK, IIT-D and FERET datasets. Our results are impressive compared to current state of the art.
SuperMix: Supervising the Mixing Data Augmentation
Mar 10, 2020
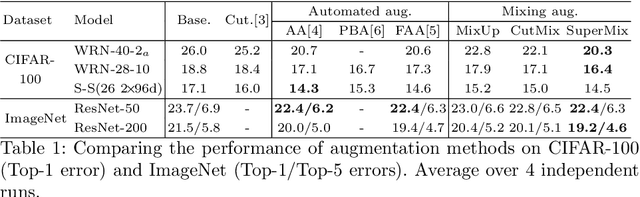
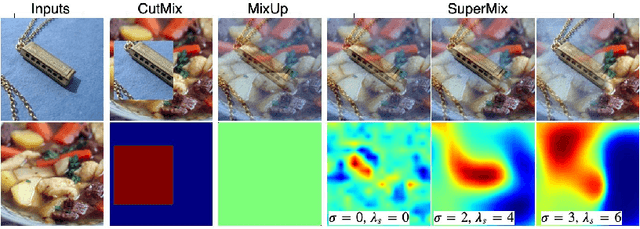
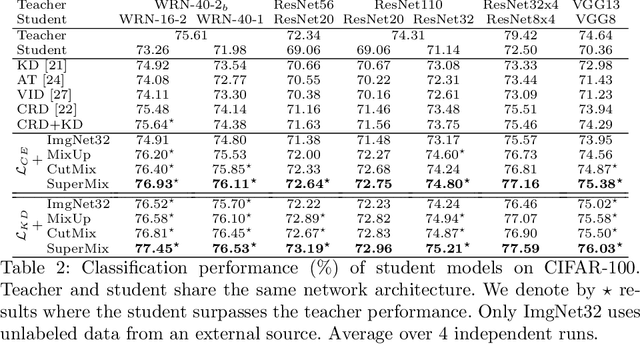
In this paper, we propose a supervised mixing augmentation method, termed SuperMix, which exploits the knowledge of a teacher to mix images based on their salient regions. SuperMix optimizes a mixing objective that considers: i) forcing the class of input images to appear in the mixed image, ii) preserving the local structure of images, and iii) reducing the risk of suppressing important features. To make the mixing suitable for large-scale applications, we develop an optimization technique, $65\times$ faster than gradient descent on the same problem. We validate the effectiveness of SuperMix through extensive evaluations and ablation studies on two tasks of object classification and knowledge distillation. On the classification task, SuperMix provides the same performance as the advanced augmentation methods, such as AutoAugment. On the distillation task, SuperMix sets a new state-of-the-art with a significantly simplified distillation method. Particularly, in six out of eight teacher-student setups from the same architectures, the students trained on the mixed data surpass their teachers with a notable margin.
Boosting Deep Face Recognition via Disentangling Appearance and Geometry
Jan 13, 2020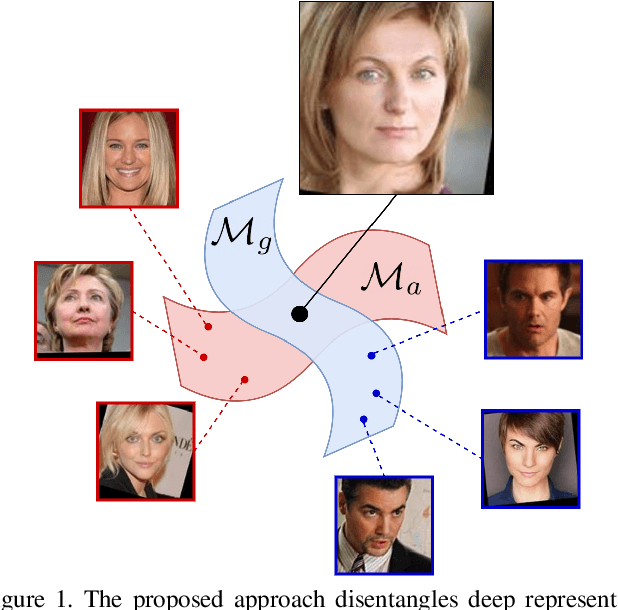
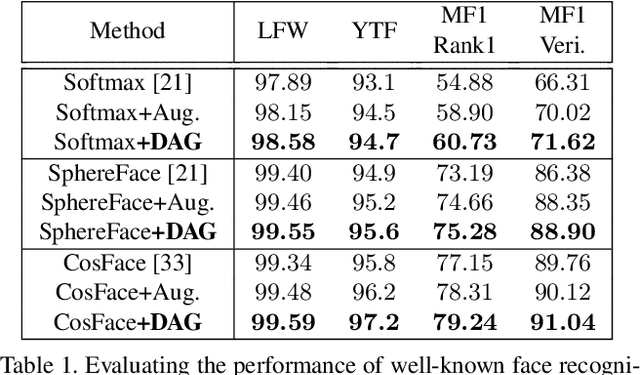

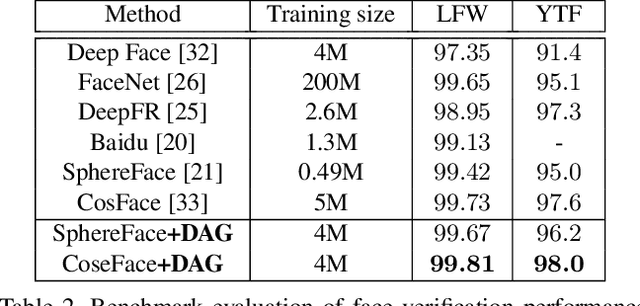
In this paper, we propose a framework for disentangling the appearance and geometry representations in the face recognition task. To provide supervision for this aim, we generate geometrically identical faces by incorporating spatial transformations. We demonstrate that the proposed approach enhances the performance of deep face recognition models by assisting the training process in two ways. First, it enforces the early and intermediate convolutional layers to learn more representative features that satisfy the properties of disentangled embeddings. Second, it augments the training set by altering faces geometrically. Through extensive experiments, we demonstrate that integrating the proposed approach into state-of-the-art face recognition methods effectively improves their performance on challenging datasets, such as LFW, YTF, and MegaFace. Both theoretical and practical aspects of the method are analyzed rigorously by concerning ablation studies and knowledge transfer tasks. Furthermore, we show that the knowledge leaned by the proposed method can favor other face-related tasks, such as attribute prediction.
Robust Facial Landmark Detection via Aggregation on Geometrically Manipulated Faces
Jan 07, 2020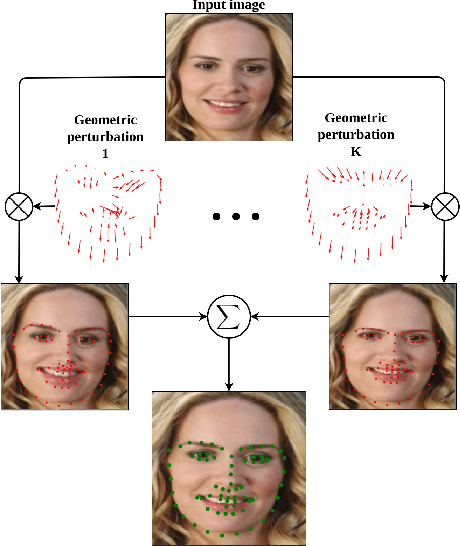

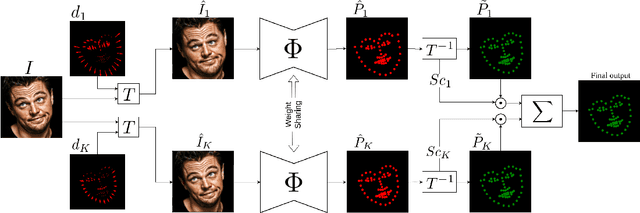
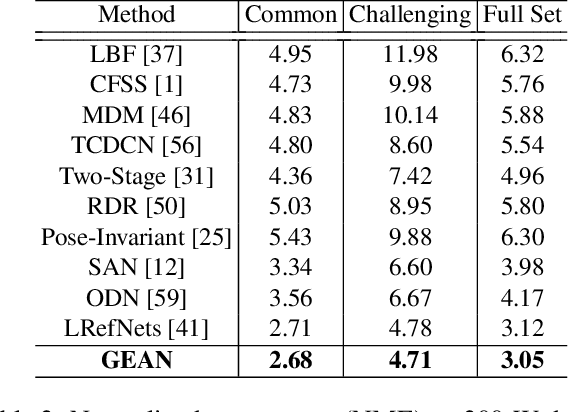
In this work, we present a practical approach to the problem of facial landmark detection. The proposed method can deal with large shape and appearance variations under the rich shape deformation. To handle the shape variations we equip our method with the aggregation of manipulated face images. The proposed framework generates different manipulated faces using only one given face image. The approach utilizes the fact that small but carefully crafted geometric manipulation in the input domain can fool deep face recognition models. We propose three different approaches to generate manipulated faces in which two of them perform the manipulations via adversarial attacks and the other one uses known transformations. Aggregating the manipulated faces provides a more robust landmark detection approach which is able to capture more important deformations and variations of the face shapes. Our approach is demonstrated its superiority compared to the state-of-the-art method on benchmark datasets AFLW, 300-W, and COFW.
SmoothFool: An Efficient Framework for Computing Smooth Adversarial Perturbations
Oct 08, 2019
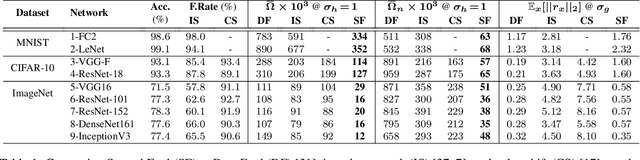
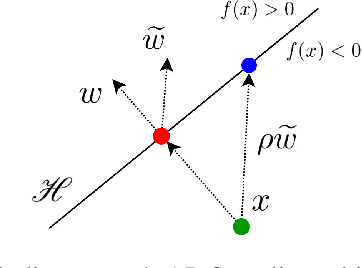
Deep neural networks are susceptible to adversarial manipulations in the input domain. The extent of vulnerability has been explored intensively in cases of $\ell_p$-bounded and $\ell_p$-minimal adversarial perturbations. However, the vulnerability of DNNs to adversarial perturbations with specific statistical properties or frequency-domain characteristics has not been sufficiently explored. In this paper, we study the smoothness of perturbations and propose SmoothFool, a general and computationally efficient framework for computing smooth adversarial perturbations. Through extensive experiments, we validate the efficacy of the proposed method for both the white-box and black-box attack scenarios. In particular, we demonstrate that: (i) there exist extremely smooth adversarial perturbations for well-established and widely used network architectures, (ii) smoothness significantly enhances the robustness of perturbations against state-of-the-art defense mechanisms, (iii) smoothness improves the transferability of adversarial perturbations across both data points and network architectures, and (iv) class categories exhibit a variable range of susceptibility to smooth perturbations. Our results suggest that smooth APs can play a significant role in exploring the vulnerability extent of DNNs to adversarial examples.
Defending Against Adversarial Iris Examples Using Wavelet Decomposition
Aug 08, 2019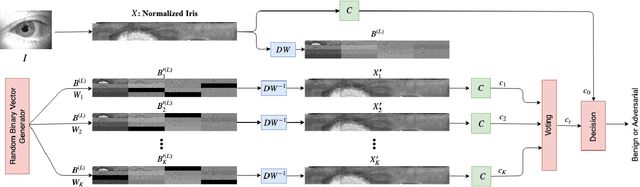
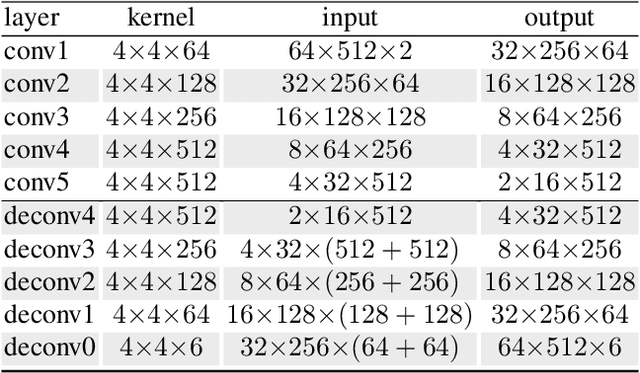
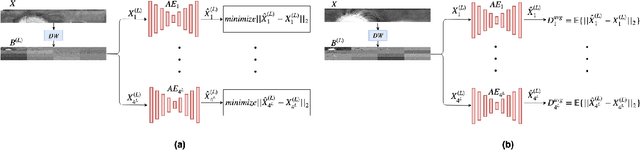

Deep neural networks have presented impressive performance in biometric applications. However, their performance is highly at risk when facing carefully crafted input samples known as adversarial examples. In this paper, we present three defense strategies to detect adversarial iris examples. These defense strategies are based on wavelet domain denoising of the input examples by investigating each wavelet sub-band and removing the sub-bands that are most affected by the adversary. The first proposed defense strategy reconstructs multiple denoised versions of the input example through manipulating the mid- and high-frequency components of the wavelet domain representation of the input example and makes a decision upon the classification result of the majority of the denoised examples. The second and third proposed defense strategies aim to denoise each wavelet domain sub-band and determine the sub-bands that are most likely affected by the adversary using the reconstruction error computed for each sub-band. We test the performance of the proposed defense strategies against several attack scenarios and compare the results with five state of the art defense strategies.
Adversarial Examples to Fool Iris Recognition Systems
Jul 18, 2019
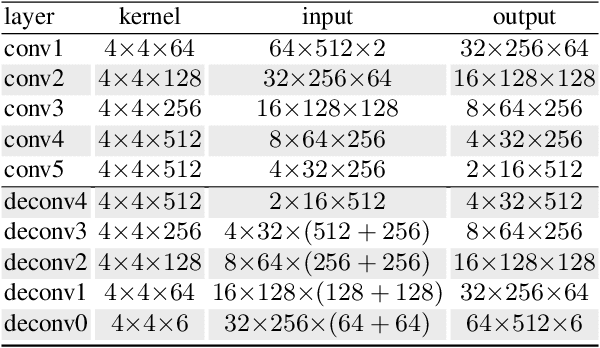
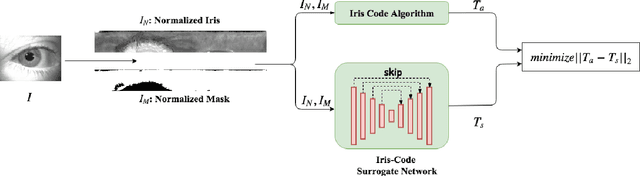
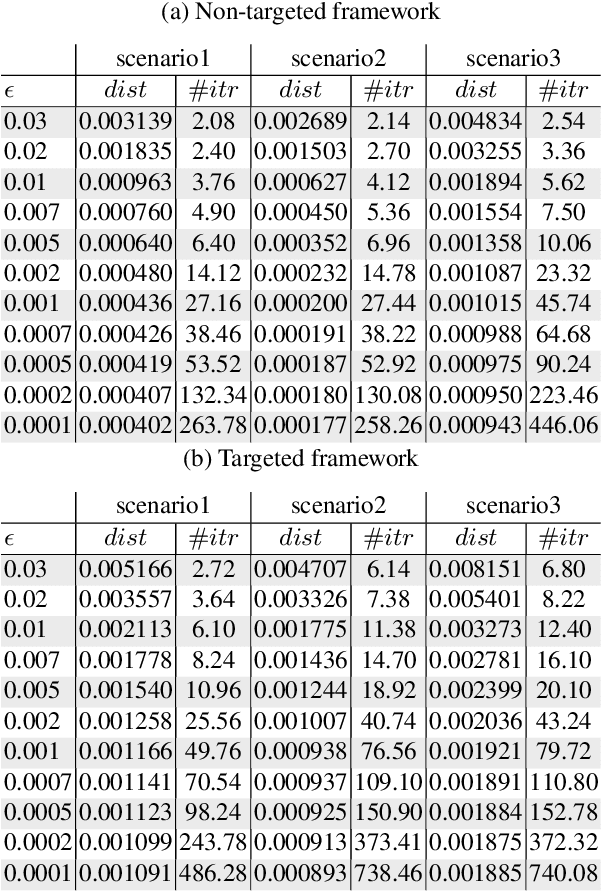
Adversarial examples have recently proven to be able to fool deep learning methods by adding carefully crafted small perturbation to the input space image. In this paper, we study the possibility of generating adversarial examples for code-based iris recognition systems. Since generating adversarial examples requires back-propagation of the adversarial loss, conventional filter bank-based iris-code generation frameworks cannot be employed in such a setup. Therefore, to compensate for this shortcoming, we propose to train a deep auto-encoder surrogate network to mimic the conventional iris code generation procedure. This trained surrogate network is then deployed to generate the adversarial examples using the iterative gradient sign method algorithm. We consider non-targeted and targeted attacks through three attack scenarios. Considering these attacks, we study the possibility of fooling an iris recognition system in white-box and black-box frameworks.
Fast Geometrically-Perturbed Adversarial Faces
Sep 28, 2018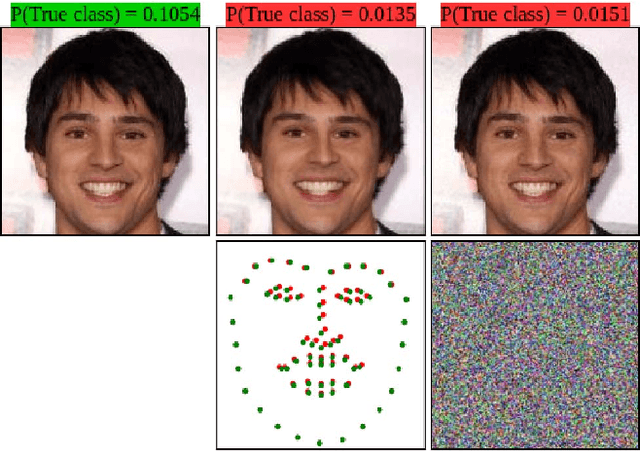
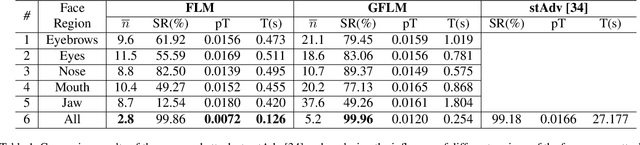
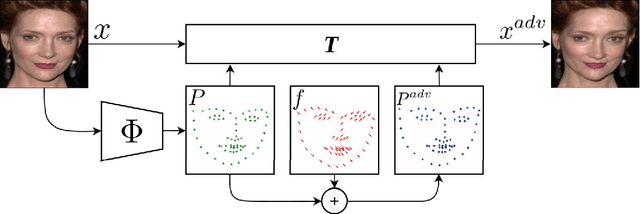
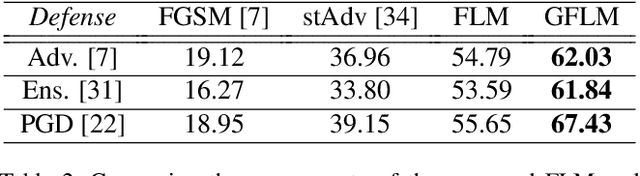
The state-of-the-art performance of deep learning algorithms has led to a considerable increase in the utilization of machine learning in security-sensitive and critical applications. However, it has recently been shown that a small and carefully crafted perturbation in the input space can completely fool a deep model. In this study, we explore the extent to which face recognition systems are vulnerable to geometrically-perturbed adversarial faces. We propose a fast landmark manipulation method for generating adversarial faces, which is approximately 200 times faster than the previous geometric attacks and obtains 99.86% success rate on the state-of-the-art face recognition models. To further force the generated samples to be natural, we introduce a second attack constrained on the semantic structure of the face which has the half speed of the first attack with the success rate of 99.96%. Both attacks are extremely robust against the state-of-the-art defense methods with the success rate of equal or greater than 53.59%. Code is available at https://github.com/alldbi/FLM
Deep Sketch-Photo Face Recognition Assisted by Facial Attributes
Jul 31, 2018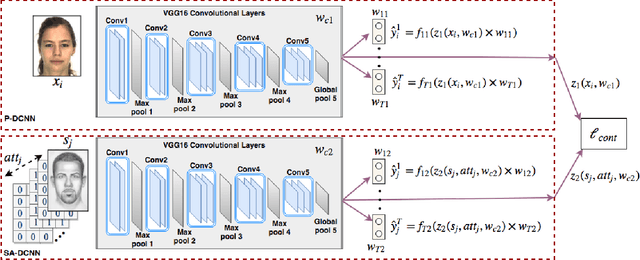

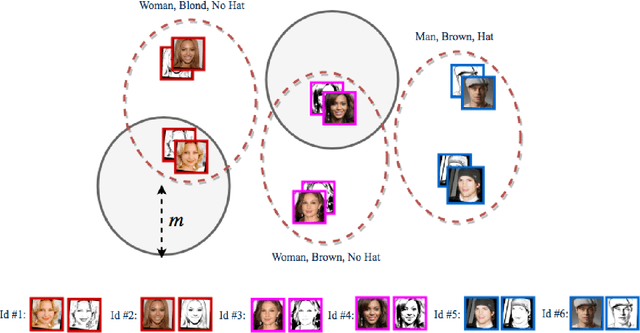
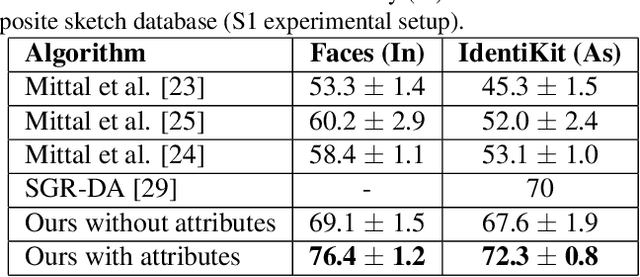
In this paper, we present a deep coupled framework to address the problem of matching sketch image against a gallery of mugshots. Face sketches have the essential in- formation about the spatial topology and geometric details of faces while missing some important facial attributes such as ethnicity, hair, eye, and skin color. We propose a cou- pled deep neural network architecture which utilizes facial attributes in order to improve the sketch-photo recognition performance. The proposed Attribute-Assisted Deep Con- volutional Neural Network (AADCNN) method exploits the facial attributes and leverages the loss functions from the facial attributes identification and face verification tasks in order to learn rich discriminative features in a common em- bedding subspace. The facial attribute identification task increases the inter-personal variations by pushing apart the embedded features extracted from individuals with differ- ent facial attributes, while the verification task reduces the intra-personal variations by pulling together all the fea- tures that are related to one person. The learned discrim- inative features can be well generalized to new identities not seen in the training data. The proposed architecture is able to make full use of the sketch and complementary fa- cial attribute information to train a deep model compared to the conventional sketch-photo recognition methods. Exten- sive experiments are performed on composite (E-PRIP) and semi-forensic (IIIT-D semi-forensic) datasets. The results show the superiority of our method compared to the state- of-the-art models in sketch-photo recognition algorithms