 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperresolution and Segmentation of OCT scans using Multi-Stage adversarial Guided Attention Training
Jun 10, 2022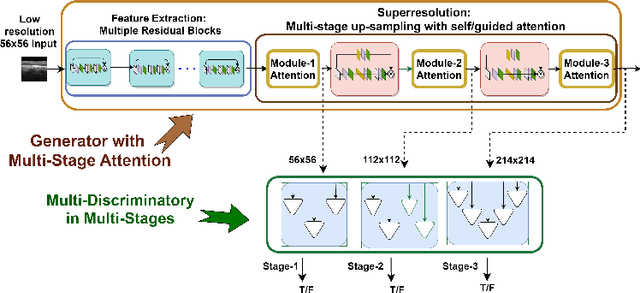

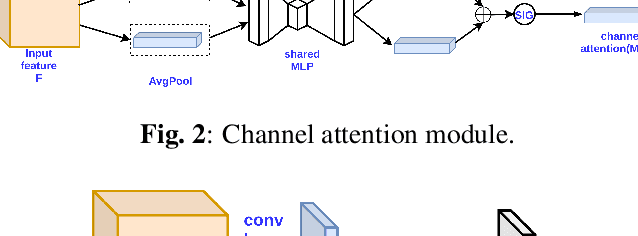
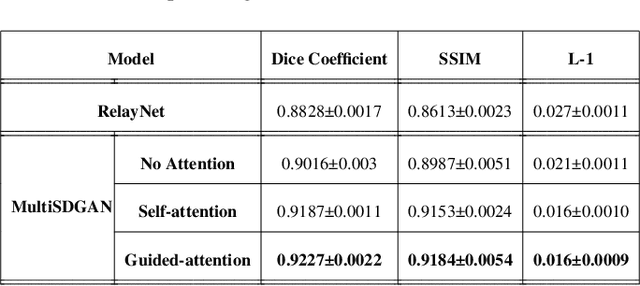
Optical coherence tomography (OCT) is one of the non-invasive and easy-to-acquire biomarkers (the thickness of the retinal layers, which is detectable within OCT scans) being investigated to diagnose Alzheimer's disease (AD). This work aims to segment the OCT images automatically; however, it is a challenging task due to various issues such as the speckle noise, small target region, and unfavorable imaging conditions. In our previous work, we have proposed the multi-stage & multi-discriminatory generative adversarial network (MultiSDGAN) to translate OCT scans in high-resolution segmentation labels. In this investigation, we aim to evaluate and compare various combinations of channel and spatial attention to the MultiSDGAN architecture to extract more powerful feature maps by capturing rich contextual relationships to improve segmentation performance. Moreover, we developed and evaluated a guided mutli-stage attention framework where we incorporated a guided attention mechanism by forcing an L-1 loss between a specifically designed binary mask and the generated attention maps. Our ablation study results on the WVU-OCT data-set in five-fold cross-validation (5-CV) suggest that the proposed MultiSDGAN with a serial attention module provides the most competitive performance, and guiding the spatial attention feature maps by binary masks further improves the performance in our proposed network. Comparing the baseline model with adding the guided-attention, our results demonstrated relative improvements of 21.44% and 19.45% on the Dice coefficient and SSIM, respectively.
Quality-Aware Multimodal Biometric Recognition
Dec 10, 2021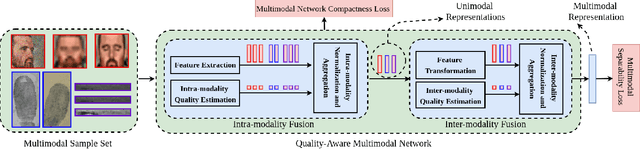
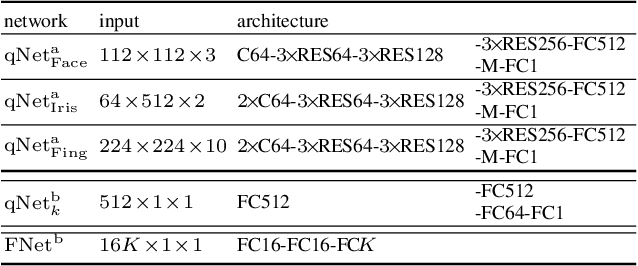
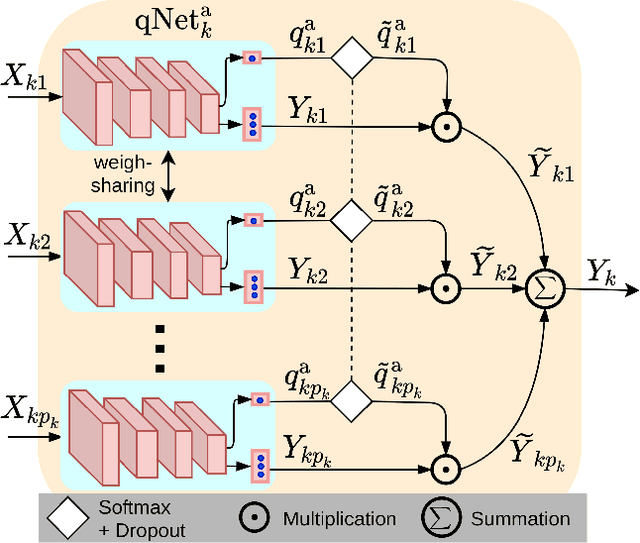
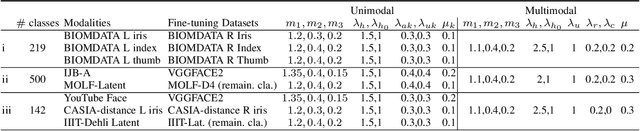
We present a quality-aware multimodal recognition framework that combines representations from multiple biometric traits with varying quality and number of samples to achieve increased recognition accuracy by extracting complimentary identification information based on the quality of the samples. We develop a quality-aware framework for fusing representations of input modalities by weighting their importance using quality scores estimated in a weakly-supervised fashion. This framework utilizes two fusion blocks, each represented by a set of quality-aware and aggregation networks. In addition to architecture modifications, we propose two task-specific loss functions: multimodal separability loss and multimodal compactness loss. The first loss assures that the representations of modalities for a class have comparable magnitudes to provide a better quality estimation, while the multimodal representations of different classes are distributed to achieve maximum discrimination in the embedding space. The second loss, which is considered to regularize the network weights, improves the generalization performance by regularizing the framework. We evaluate the performance by considering three multimodal datasets consisting of face, iris, and fingerprint modalities. The efficacy of the framework is demonstrated through comparison with the state-of-the-art algorithms. In particular, our framework outperforms the rank- and score-level fusion of modalities of BIOMDATA by more than 30% for true acceptance rate at false acceptance rate of $10^{-4}$.
Tasks Structure Regularization in Multi-Task Learning for Improving Facial Attribute Prediction
Aug 18, 2021
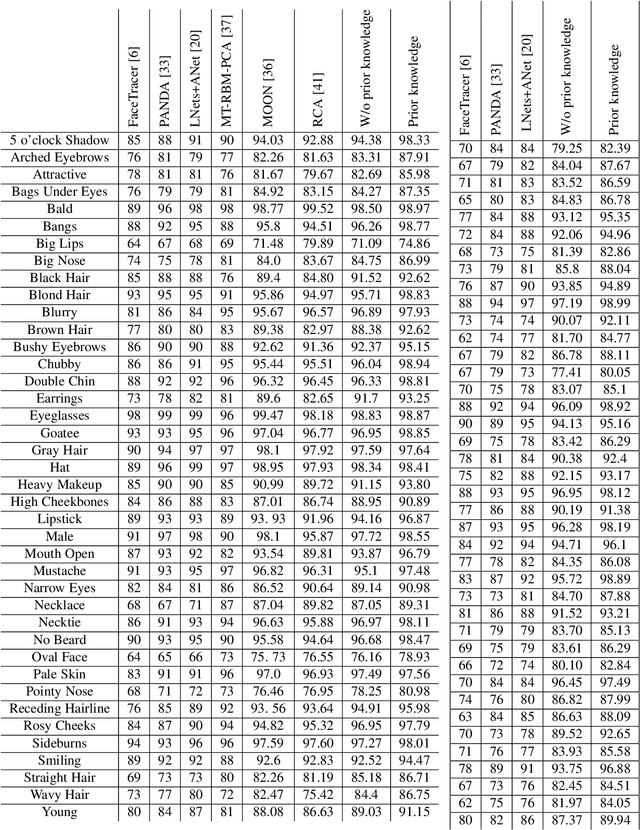
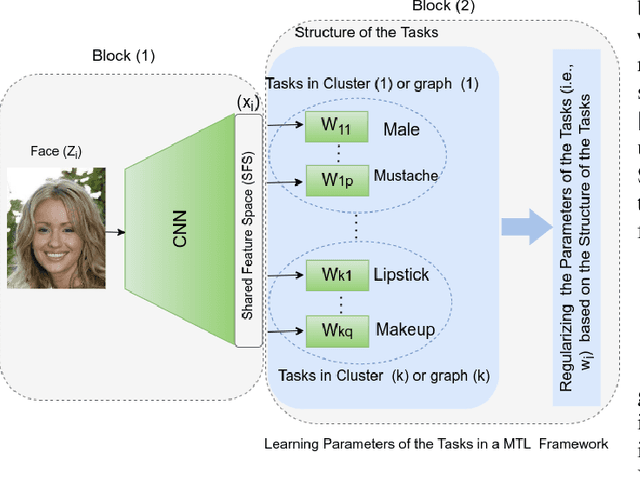
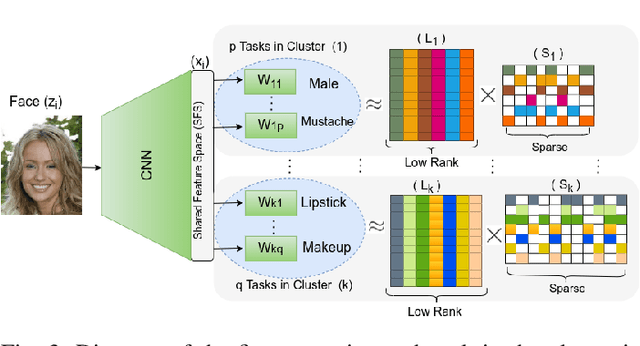
The great success of Convolutional Neural Networks (CNN) for facial attribute prediction relies on a large amount of labeled images. Facial image datasets are usually annotated by some commonly used attributes (e.g., gender), while labels for the other attributes (e.g., big nose) are limited which causes their prediction challenging. To address this problem, we use a new Multi-Task Learning (MTL) paradigm in which a facial attribute predictor uses the knowledge of other related attributes to obtain a better generalization performance. Here, we leverage MLT paradigm in two problem settings. First, it is assumed that the structure of the tasks (e.g., grouping pattern of facial attributes) is known as a prior knowledge, and parameters of the tasks (i.e., predictors) within the same group are represented by a linear combination of a limited number of underlying basis tasks. Here, a sparsity constraint on the coefficients of this linear combination is also considered such that each task is represented in a more structured and simpler manner. Second, it is assumed that the structure of the tasks is unknown, and then structure and parameters of the tasks are learned jointly by using a Laplacian regularization framework. Our MTL methods are compared with competing methods for facial attribute prediction to show its effectiveness.
Attribute Guided Sparse Tensor-Based Model for Person Re-Identification
Jul 29, 2021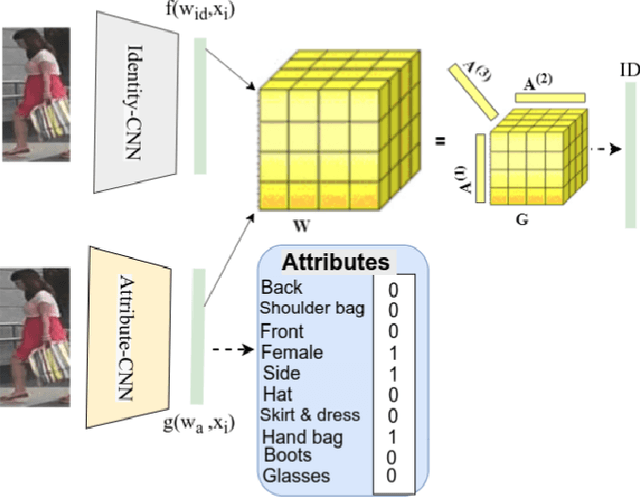

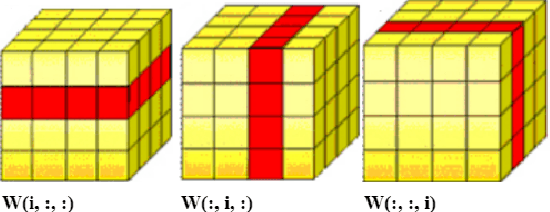

Visual perception of a person is easily influenced by many factors such as camera parameters, pose and viewpoint variations. These variations make person Re-Identification (ReID) a challenging problem. Nevertheless, human attributes usually stand as robust visual properties to such variations. In this paper, we propose a new method to leverage features from human attributes for person ReID. Our model uses a tensor to non-linearly fuse identity and attribute features, and then forces the parameters of the tensor in the loss function to generate discriminative fused features for ReID. Since tensor-based methods usually contain a large number of parameters, training all of these parameters becomes very slow, and the chance of overfitting increases as well. To address this issue, we propose two new techniques based on Structural Sparsity Learning (SSL) and Tensor Decomposition (TD) methods to create an accurate and stable learning problem. We conducted experiments on several standard pedestrian datasets, and experimental results indicate that our tensor-based approach significantly improves person ReID baselines and also outperforms state of the art methods.
FDeblur-GAN: Fingerprint Deblurring using Generative Adversarial Network
Jun 21, 2021
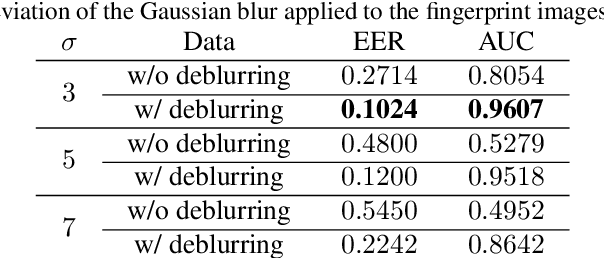
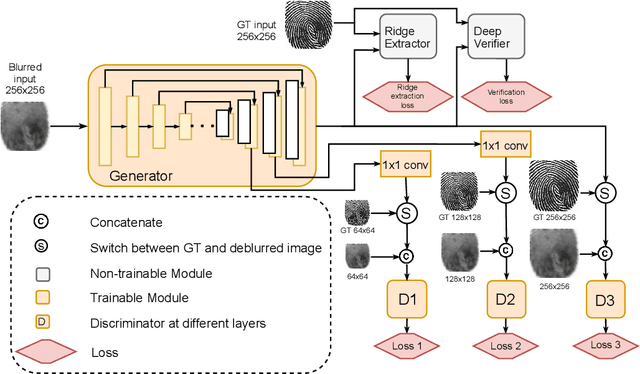
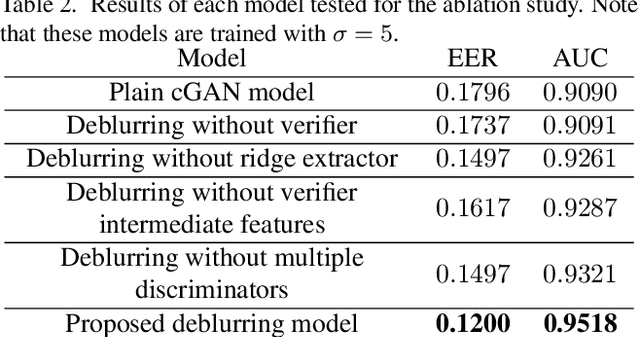
While working with fingerprint images acquired from crime scenes, mobile cameras, or low-quality sensors, it becomes difficult for automated identification systems to verify the identity due to image blur and distortion. We propose a fingerprint deblurring model FDeblur-GAN, based on the conditional Generative Adversarial Networks (cGANs) and multi-stage framework of the stack GAN. Additionally, we integrate two auxiliary sub-networks into the model for the deblurring task. The first sub-network is a ridge extractor model. It is added to generate ridge maps to ensure that fingerprint information and minutiae are preserved in the deblurring process and prevent the model from generating erroneous minutiae. The second sub-network is a verifier that helps the generator to preserve the ID information during the generation process. Using a database of blurred fingerprints and corresponding ridge maps, the deep network learns to deblur from the input blurry samples. We evaluate the proposed method in combination with two different fingerprint matching algorithms. We achieved an accuracy of 95.18% on our fingerprint database for the task of matching deblurred and ground truth fingerprints.
Super-resolution Guided Pore Detection for Fingerprint Recognition
Dec 10, 2020
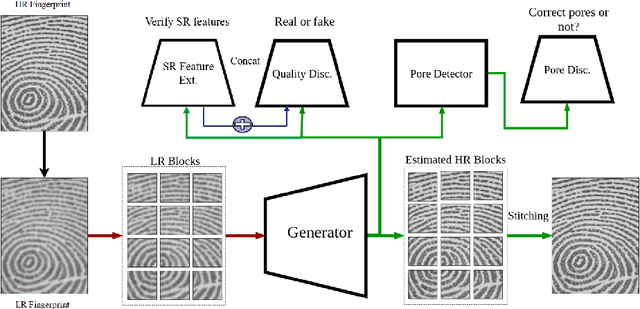

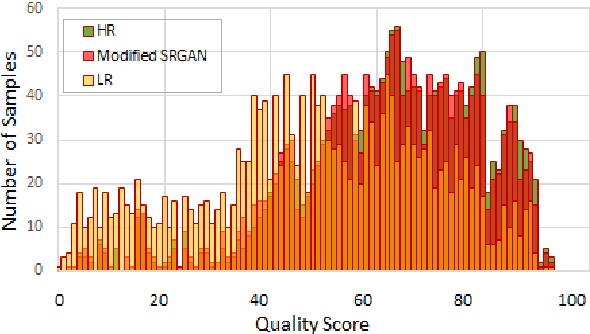
Performance of fingerprint recognition algorithms substantially rely on fine features extracted from fingerprints. Apart from minutiae and ridge patterns, pore features have proven to be usable for fingerprint recognition. Although features from minutiae and ridge patterns are quite attainable from low-resolution images, using pore features is practical only if the fingerprint image is of high resolution which necessitates a model that enhances the image quality of the conventional 500 ppi legacy fingerprints preserving the fine details. To find a solution for recovering pore information from low-resolution fingerprints, we adopt a joint learning-based approach that combines both super-resolution and pore detection networks. Our modified single image Super-Resolution Generative Adversarial Network (SRGAN) framework helps to reliably reconstruct high-resolution fingerprint samples from low-resolution ones assisting the pore detection network to identify pores with a high accuracy. The network jointly learns a distinctive feature representation from a real low-resolution fingerprint sample and successfully synthesizes a high-resolution sample from it. To add discriminative information and uniqueness for all the subjects, we have integrated features extracted from a deep fingerprint verifier with the SRGAN quality discriminator. We also add ridge reconstruction loss, utilizing ridge patterns to make the best use of extracted features. Our proposed method solves the recognition problem by improving the quality of fingerprint images. High recognition accuracy of the synthesized samples that is close to the accuracy achieved using the original high-resolution images validate the effectiveness of our proposed model.
Differential Morphed Face Detection Using Deep Siamese Networks
Dec 05, 2020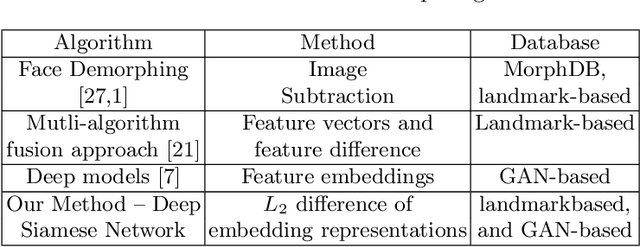

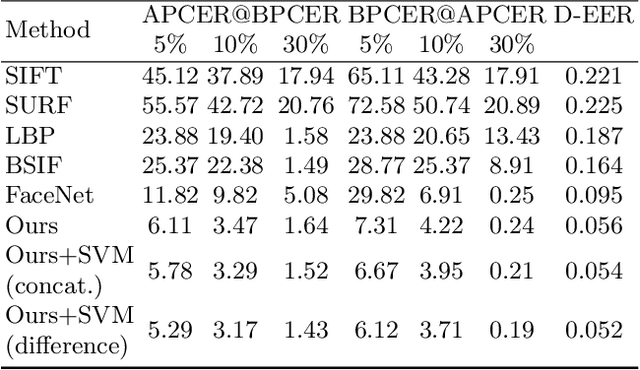
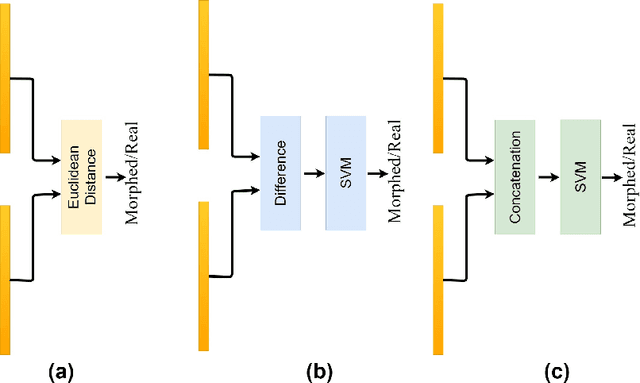
Although biometric facial recognition systems are fast becoming part of security applications, these systems are still vulnerable to morphing attacks, in which a facial reference image can be verified as two or more separate identities. In border control scenarios, a successful morphing attack allows two or more people to use the same passport to cross borders. In this paper, we propose a novel differential morph attack detection framework using a deep Siamese network. To the best of our knowledge, this is the first research work that makes use of a Siamese network architecture for morph attack detection. We compare our model with other classical and deep learning models using two distinct morph datasets, VISAPP17 and MorGAN. We explore the embedding space generated by the contrastive loss using three decision making frameworks using Euclidean distance, feature difference and a support vector machine classifier, and feature concatenation and a support vector machine classifier.
Matching Distributions via Optimal Transport for Semi-Supervised Learning
Dec 04, 2020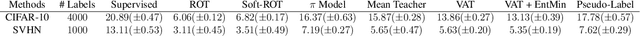
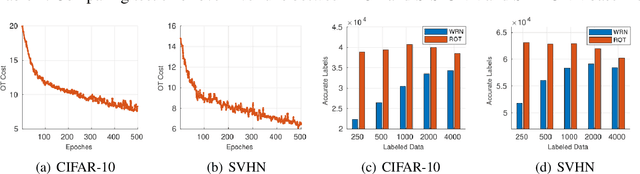
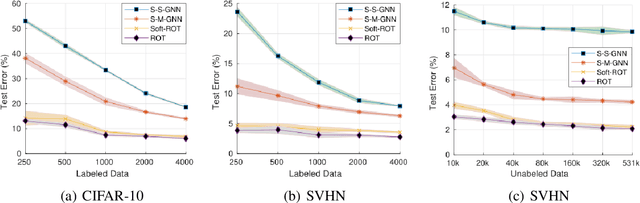
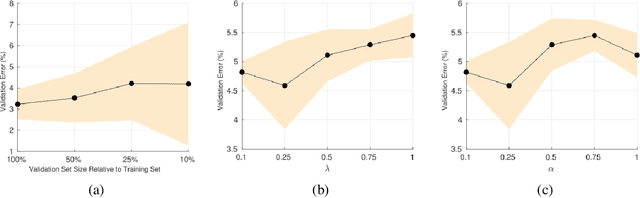
Semi-Supervised Learning (SSL) approaches have been an influential framework for the usage of unlabeled data when there is not a sufficient amount of labeled data available over the course of training. SSL methods based on Convolutional Neural Networks (CNNs) have recently provided successful results on standard benchmark tasks such as image classification. In this work, we consider the general setting of SSL problem where the labeled and unlabeled data come from the same underlying probability distribution. We propose a new approach that adopts an Optimal Transport (OT) technique serving as a metric of similarity between discrete empirical probability measures to provide pseudo-labels for the unlabeled data, which can then be used in conjunction with the initial labeled data to train the CNN model in an SSL manner. We have evaluated and compared our proposed method with state-of-the-art SSL algorithms on standard datasets to demonstrate the superiority and effectiveness of our SSL algorithm.
Mutual Information Maximization on Disentangled Representations for Differential Morph Detection
Dec 02, 2020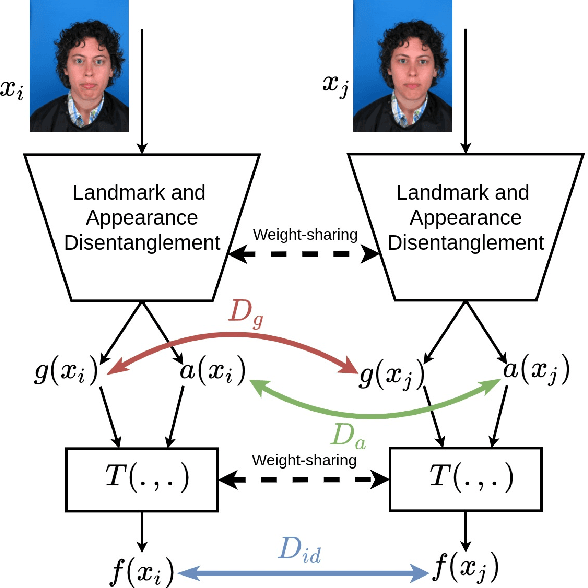
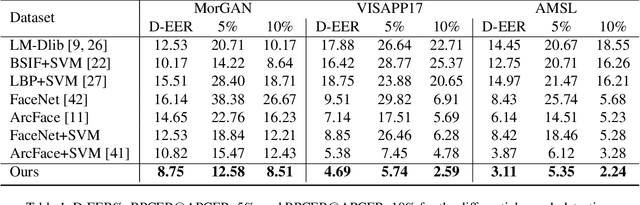
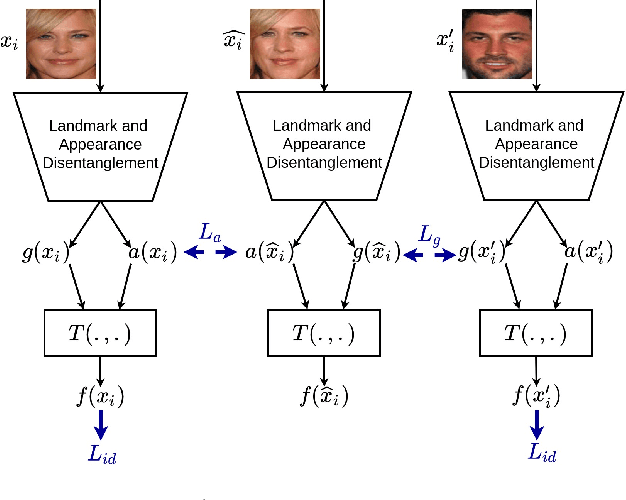
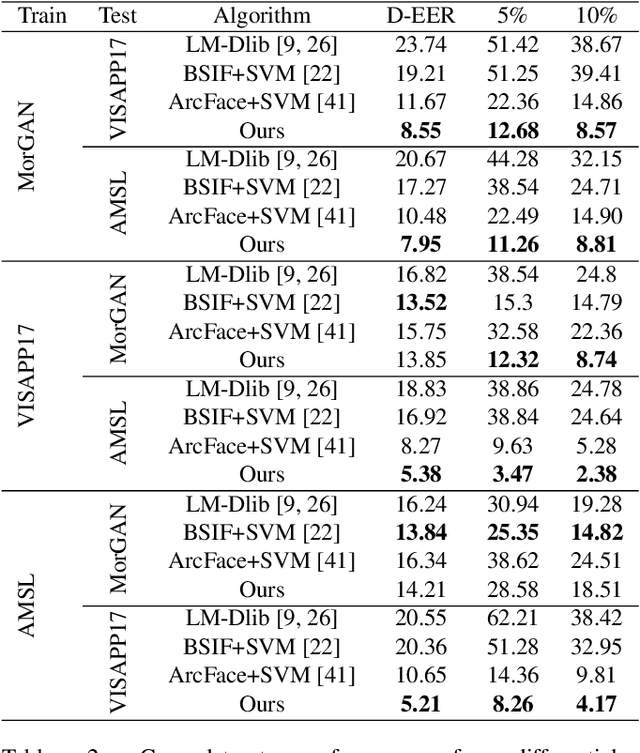
In this paper, we present a novel differential morph detection framework, utilizing landmark and appearance disentanglement. In our framework, the face image is represented in the embedding domain using two disentangled but complementary representations. The network is trained by triplets of face images, in which the intermediate image inherits the landmarks from one image and the appearance from the other image. This initially trained network is further trained for each dataset using contrastive representations. We demonstrate that, by employing appearance and landmark disentanglement, the proposed framework can provide state-of-the-art differential morph detection performance. This functionality is achieved by the using distances in landmark, appearance, and ID domains. The performance of the proposed framework is evaluated using three morph datasets generated with different methodologies.
Attribute Adaptive Margin Softmax Loss using Privileged Information
Sep 04, 2020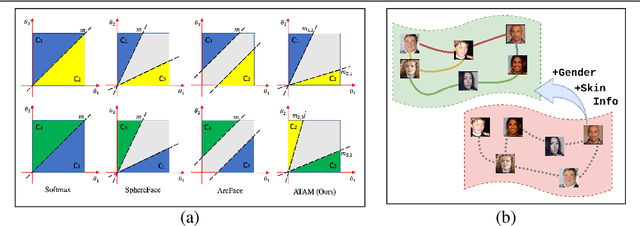
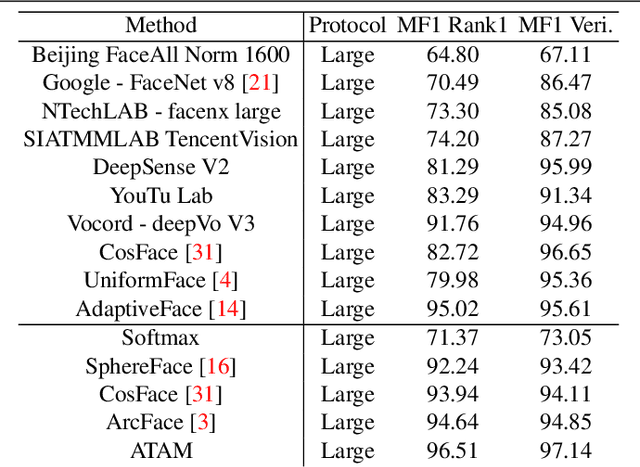
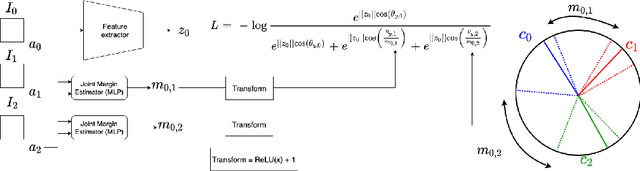
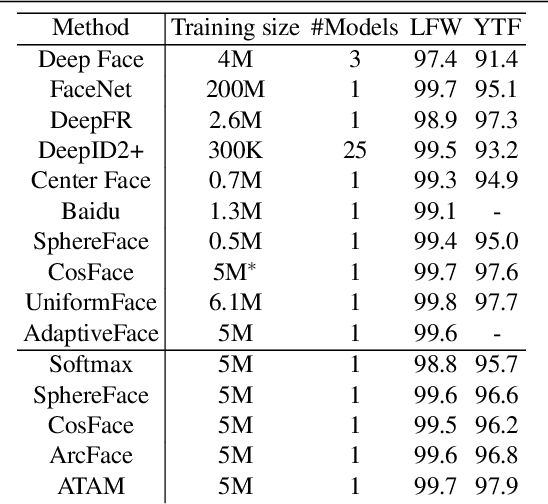
We present a novel framework to exploit privileged information for recognition which is provided only during the training phase. Here, we focus on recognition task where images are provided as the main view and soft biometric traits (attributes) are provided as the privileged data (only available during training phase). We demonstrate that more discriminative feature space can be learned by enforcing a deep network to adjust adaptive margins between classes utilizing attributes. This tight constraint also effectively reduces the class imbalance inherent in the local data neighborhood, thus carving more balanced class boundaries locally and using feature space more efficiently. Extensive experiments are performed on five different datasets and the results show the superiority of our method compared to the state-of-the-art models in both tasks of face recognition and person re-identification.