 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexey Skrynnik
Interactive Grounded Language Understanding in a Collaborative Environment: IGLU 2021
May 05, 2022

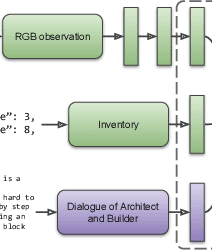
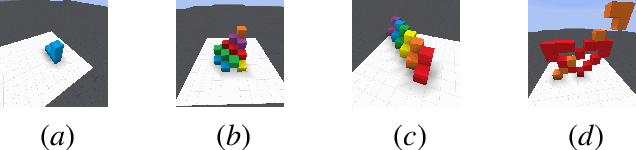
Human intelligence has the remarkable ability to quickly adapt to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose \emph{IGLU: Interactive Grounded Language Understanding in a Collaborative Environment}. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants.
* arXiv admin note: substantial text overlap with arXiv:2110.06536
NeurIPS 2021 Competition IGLU: Interactive Grounded Language Understanding in a Collaborative Environment
Oct 15, 2021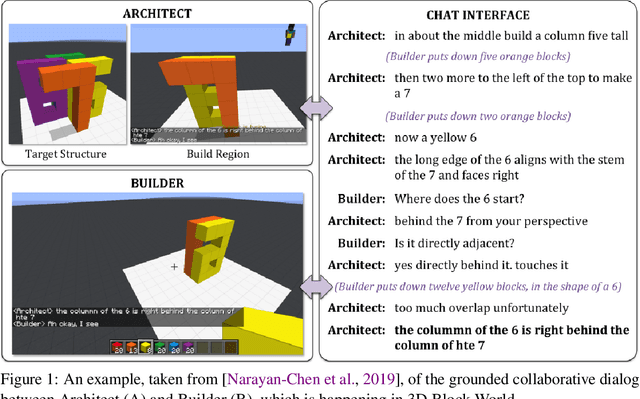

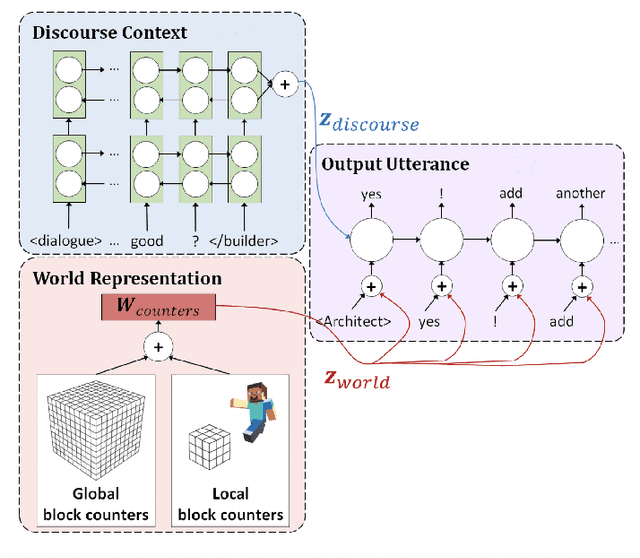
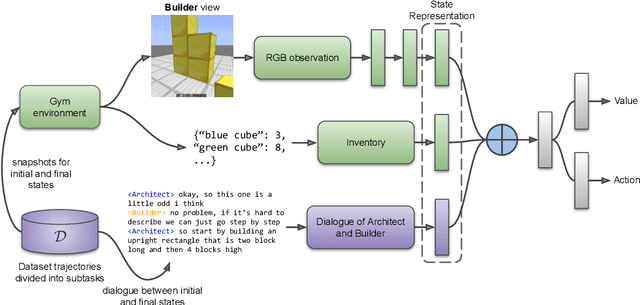
Human intelligence has the remarkable ability to adapt to new tasks and environments quickly. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants. This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the important challenges in AI. Another important aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.
Long-Term Exploration in Persistent MDPs
Sep 21, 2021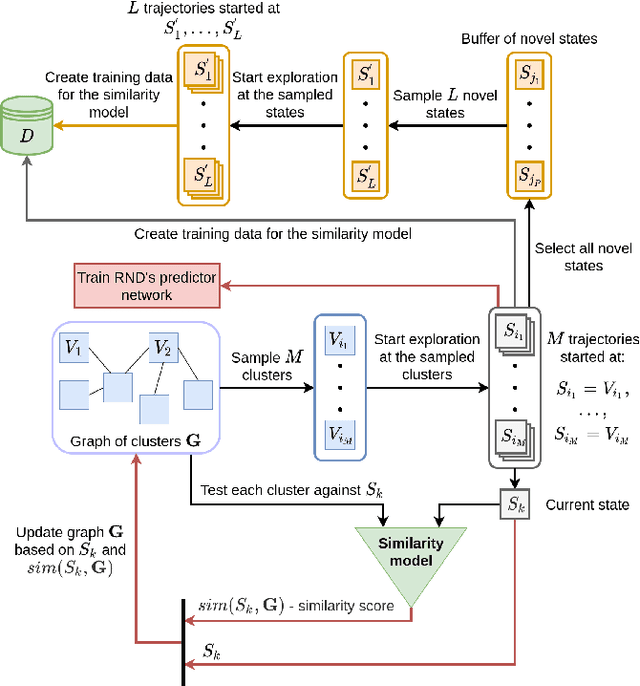
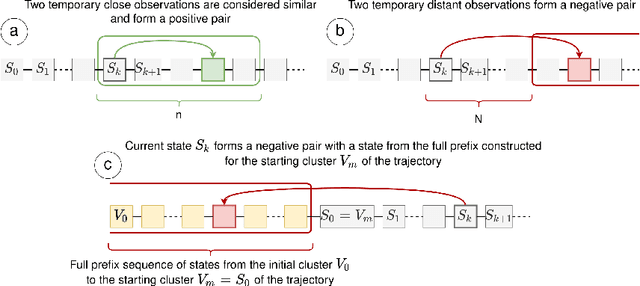
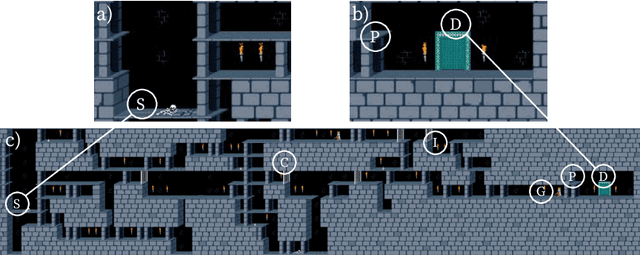

Exploration is an essential part of reinforcement learning, which restricts the quality of learned policy. Hard-exploration environments are defined by huge state space and sparse rewards. In such conditions, an exhaustive exploration of the environment is often impossible, and the successful training of an agent requires a lot of interaction steps. In this paper, we propose an exploration method called Rollback-Explore (RbExplore), which utilizes the concept of the persistent Markov decision process, in which agents during training can roll back to visited states. We test our algorithm in the hard-exploration Prince of Persia game, without rewards and domain knowledge. At all used levels of the game, our agent outperforms or shows comparable results with state-of-the-art curiosity methods with knowledge-based intrinsic motivation: ICM and RND. An implementation of RbExplore can be found at https://github.com/cds-mipt/RbExplore.
Q-Mixing Network for Multi-Agent Pathfinding in Partially Observable Grid Environments
Aug 13, 2021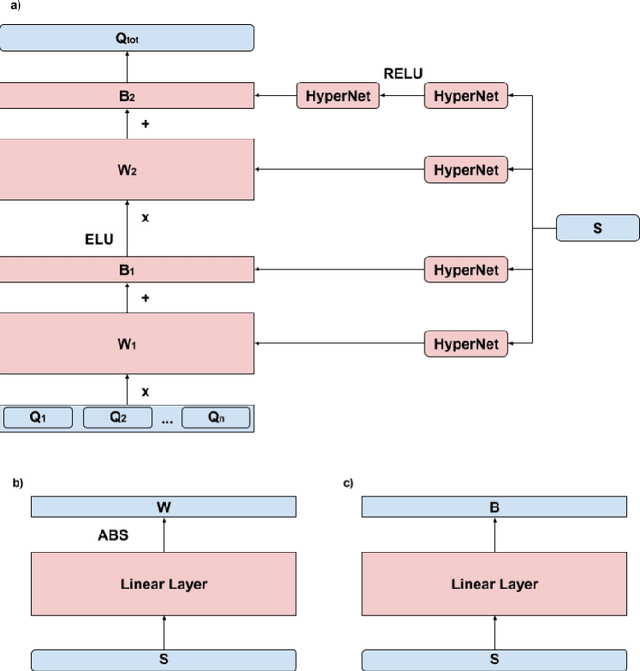

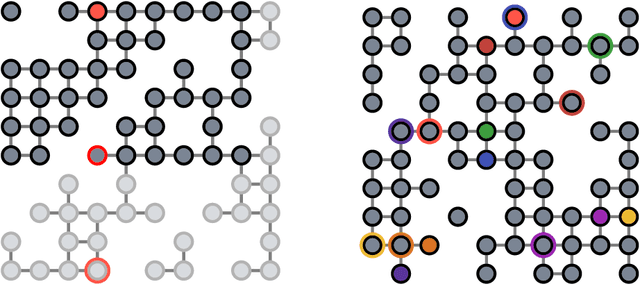

In this paper, we consider the problem of multi-agent navigation in partially observable grid environments. This problem is challenging for centralized planning approaches as they, typically, rely on the full knowledge of the environment. We suggest utilizing the reinforcement learning approach when the agents, first, learn the policies that map observations to actions and then follow these policies to reach their goals. To tackle the challenge associated with learning cooperative behavior, i.e. in many cases agents need to yield to each other to accomplish a mission, we use a mixing Q-network that complements learning individual policies. In the experimental evaluation, we show that such approach leads to plausible results and scales well to large number of agents.
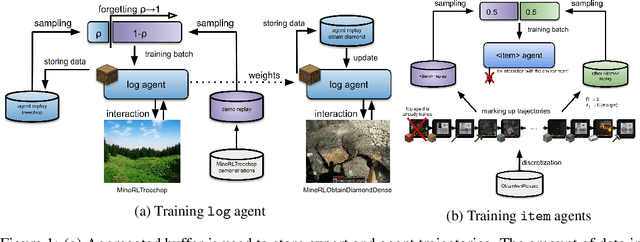
Forgetful Experience Replay in Hierarchical Reinforcement Learning from Demonstrations
Jun 17, 2020Currently, deep reinforcement learning (RL) shows impressive results in complex gaming and robotic environments. Often these results are achieved at the expense of huge computational costs and require an incredible number of episodes of interaction between the agent and the environment. There are two main approaches to improving the sample efficiency of reinforcement learning methods - using hierarchical methods and expert demonstrations. In this paper, we propose a combination of these approaches that allow the agent to use low-quality demonstrations in complex vision-based environments with multiple related goals. Our forgetful experience replay (ForgER) algorithm effectively handles errors in expert data and reduces quality losses when adapting the action space and states representation to the agent's capabilities. Our proposed goal-oriented structuring of replay buffer allows the agent to automatically highlight sub-goals for solving complex hierarchical tasks in demonstrations. Our method is universal and can be integrated into various off-policy methods. It surpasses all known existing state-of-the-art RL methods using expert demonstrations on various model environments. The solution based on our algorithm beats all the solutions for the famous MineRL competition and allows the agent to mine a diamond in the Minecraft environment.
Hierarchical Deep Q-Network from Imperfect Demonstrations in Minecraft
Feb 10, 2020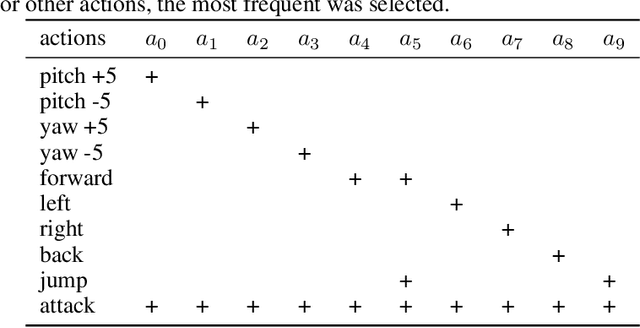

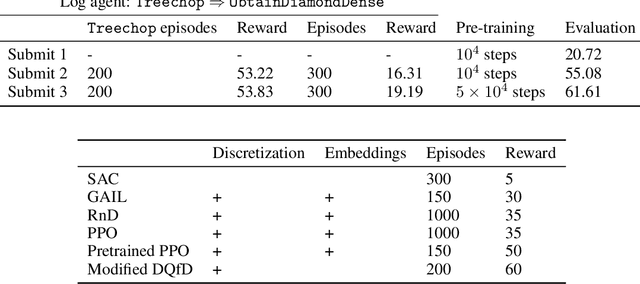
We present hierarchical Deep Q-Network with Forgetting (HDQF) that took first place in MineRL competition. HDQF works on imperfect demonstrations utilize hierarchical structure of expert trajectories extracting effective sequence of meta-actions and subgoals. We introduce structured task dependent replay buffer and forgetting technique that allow the HDQF agent to gradually erase poor-quality expert data from the buffer. In this paper we present the details of the HDQF algorithm and give the experimental results in Minecraft domain.
Hierarchical Deep Q-Network with Forgetting from Imperfect Demonstrations in Minecraft
Dec 18, 2019We present hierarchical Deep Q-Network with Forgetting (HDQF) that took first place in MineRL competition. HDQF works on imperfect demonstrations utilize hierarchical structure of expert trajectories extracting effective sequence of meta-actions and subgoals. We introduce structured task dependent replay buffer and forgetting technique that allow the HDQF agent to gradually erase poor-quality expert data from the buffer. In this paper we present the details of the HDQF algorithm and give the experimental results in Minecraft domain.