 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexandros G. Dimakis
The Sparse Recovery Autoencoder
Jul 05, 2018
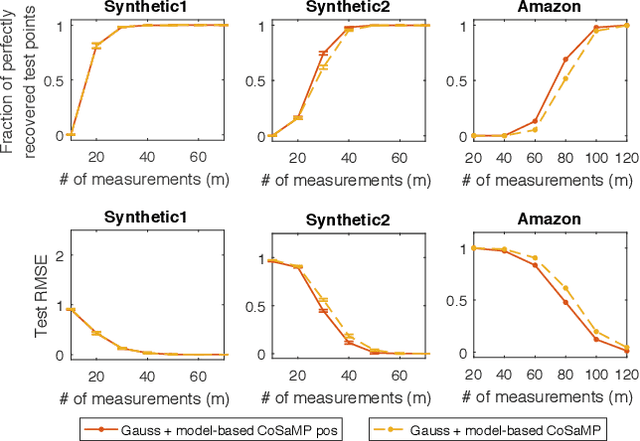
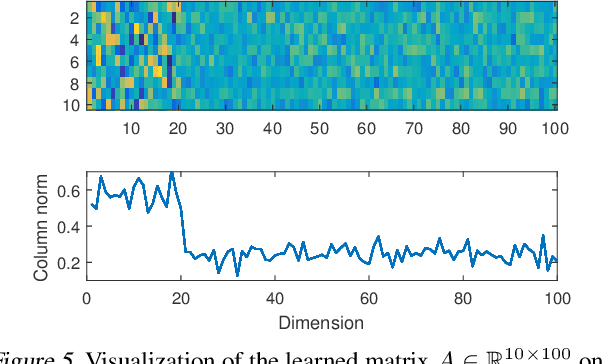
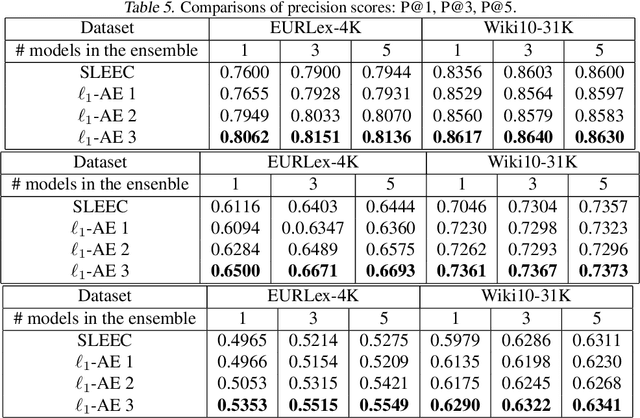
Linear encoding of sparse vectors is widely popular, but is most commonly data-independent -- missing any possible extra (but a-priori unknown) structure beyond sparsity. In this paper we present a new method to learn linear encoders that adapt to data, while still performing well with the widely used $\ell_1$ decoder. The convex $\ell_1$ decoder prevents gradient propagation as needed in standard autoencoder training. Our method is based on the insight that unfolding the convex decoder into $T$ projected gradient steps can address this issue. Our method can be seen as a data-driven way to learn a compressed sensing matrix. Our experiments show that there is indeed additional structure beyond sparsity in several real datasets. Our autoencoder is able to discover it and exploit it to create excellent reconstructions with fewer measurements compared to the previous state of the art methods.
Compressed Sensing with Deep Image Prior and Learned Regularization
Jun 17, 2018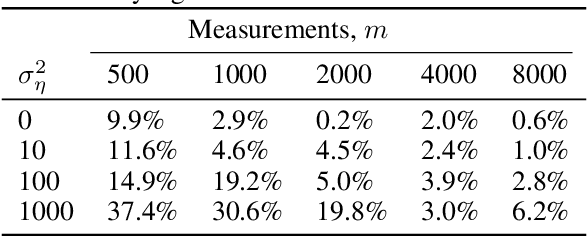
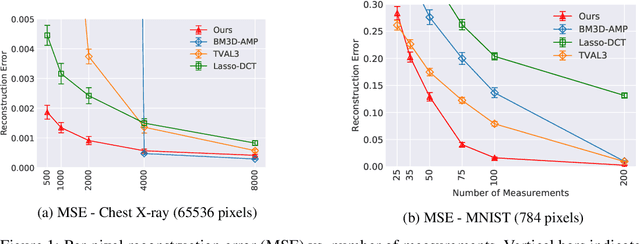

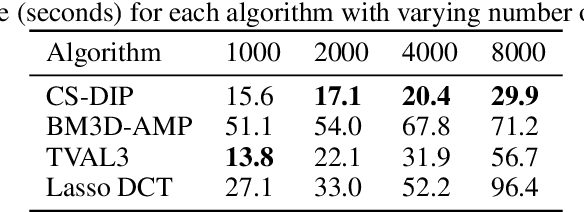
We propose a novel method for compressed sensing recovery using untrained deep generative models. Our method is based on the recently proposed Deep Image Prior (DIP), wherein the convolutional weights of the network are optimized to match the observed measurements. We show that this approach can be applied to solve any differentiable inverse problem. We also introduce a novel learned regularization technique which incorporates a small amount of prior information, further reducing the number of measurements required for a given reconstruction error. Our algorithm requires approximately 4-6x fewer measurements than classical Lasso methods. Unlike previous approaches based on generative models, our method does not require the model to be pre-trained. As such, we can apply our method to various medical imaging datasets for which data acquisition is expensive and no known generative models exist.
The Robust Manifold Defense: Adversarial Training using Generative Models
Dec 26, 2017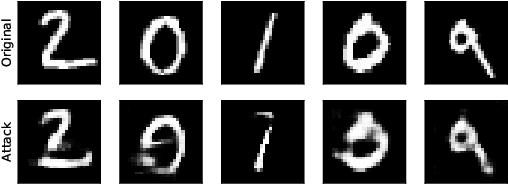
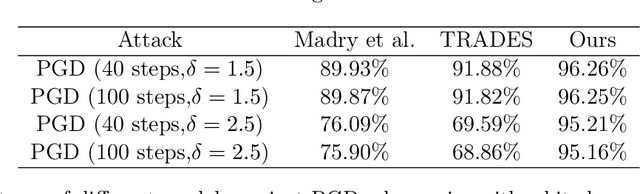

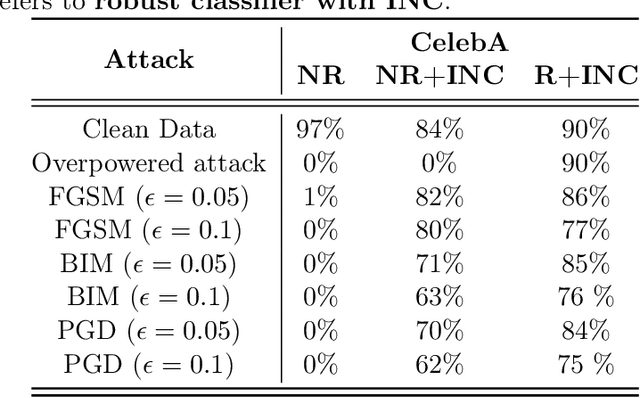
Deep neural networks are demonstrating excellent performance on several classical vision problems. However, these networks are vulnerable to adversarial examples, minutely modified images that induce arbitrary attacker-chosen output from the network. We propose a mechanism to protect against these adversarial inputs based on a generative model of the data. We introduce a pre-processing step that projects on the range of a generative model using gradient descent before feeding an input into a classifier. We show that this step provides the classifier with robustness against first-order, substitute model, and combined adversarial attacks. Using a min-max formulation, we show that there may exist adversarial examples even in the range of the generator, natural-looking images extremely close to the decision boundary for which the classifier has unjustifiedly high confidence. We show that adversarial training on the generative manifold can be used to make a classifier that is robust to these attacks. Finally, we show how our method can be applied even without a pre-trained generative model using a recent method called the deep image prior. We evaluate our method on MNIST, CelebA and Imagenet and show robustness against the current state of the art attacks.
Streaming Weak Submodularity: Interpreting Neural Networks on the Fly
Nov 22, 2017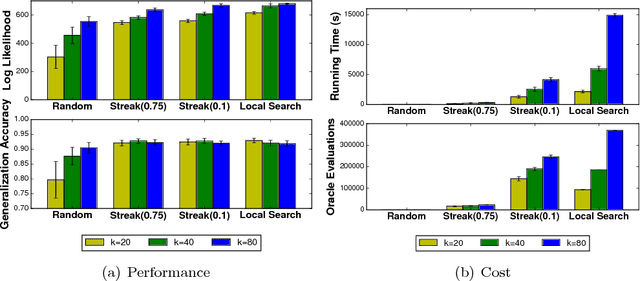
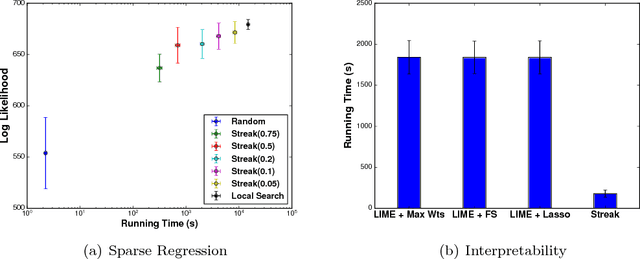
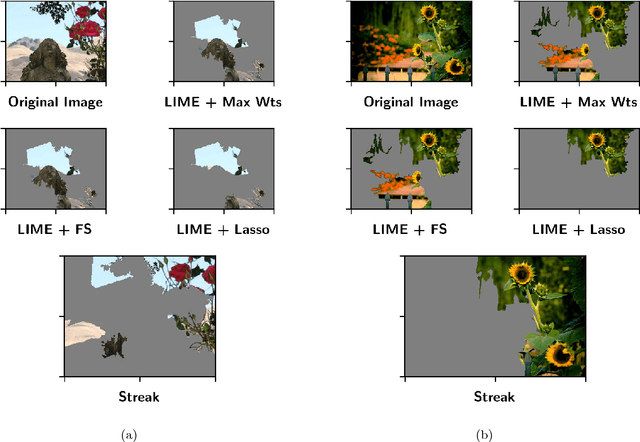

In many machine learning applications, it is important to explain the predictions of a black-box classifier. For example, why does a deep neural network assign an image to a particular class? We cast interpretability of black-box classifiers as a combinatorial maximization problem and propose an efficient streaming algorithm to solve it subject to cardinality constraints. By extending ideas from Badanidiyuru et al. [2014], we provide a constant factor approximation guarantee for our algorithm in the case of random stream order and a weakly submodular objective function. This is the first such theoretical guarantee for this general class of functions, and we also show that no such algorithm exists for a worst case stream order. Our algorithm obtains similar explanations of Inception V3 predictions $10$ times faster than the state-of-the-art LIME framework of Ribeiro et al. [2016].
Restricted Strong Convexity Implies Weak Submodularity
Oct 12, 2017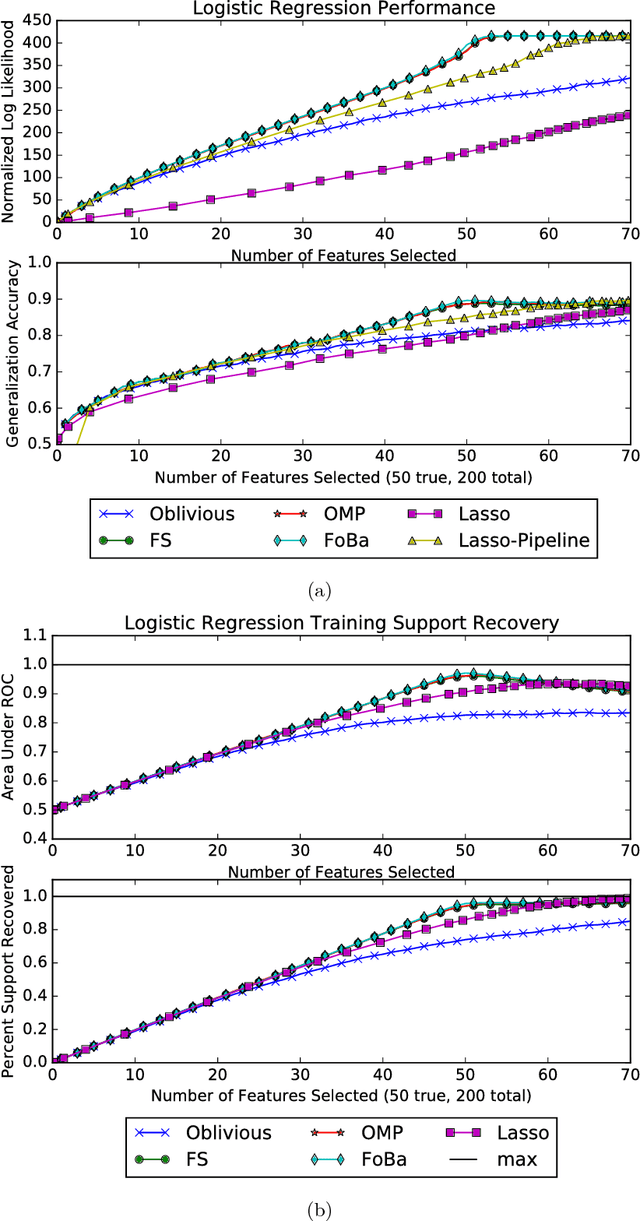
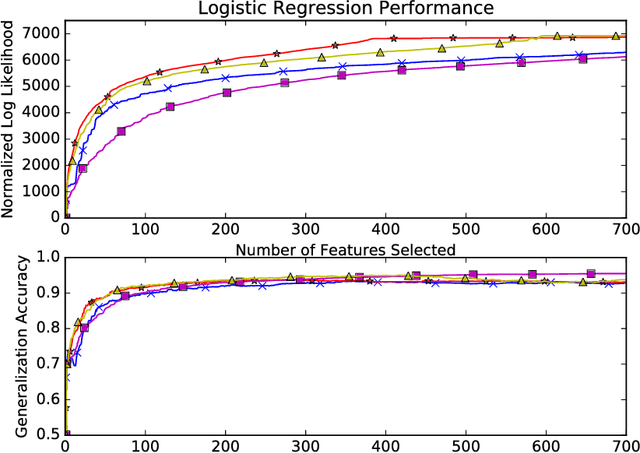
We connect high-dimensional subset selection and submodular maximization. Our results extend the work of Das and Kempe (2011) from the setting of linear regression to arbitrary objective functions. For greedy feature selection, this connection allows us to obtain strong multiplicative performance bounds on several methods without statistical modeling assumptions. We also derive recovery guarantees of this form under standard assumptions. Our work shows that greedy algorithms perform within a constant factor from the best possible subset-selection solution for a broad class of general objective functions. Our methods allow a direct control over the number of obtained features as opposed to regularization parameters that only implicitly control sparsity. Our proof technique uses the concept of weak submodularity initially defined by Das and Kempe. We draw a connection between convex analysis and submodular set function theory which may be of independent interest for other statistical learning applications that have combinatorial structure.
Model-Powered Conditional Independence Test
Sep 18, 2017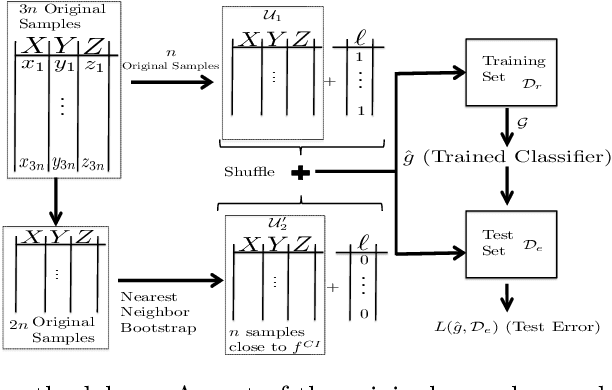
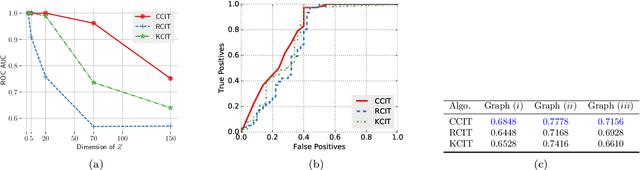
We consider the problem of non-parametric Conditional Independence testing (CI testing) for continuous random variables. Given i.i.d samples from the joint distribution $f(x,y,z)$ of continuous random vectors $X,Y$ and $Z,$ we determine whether $X \perp Y | Z$. We approach this by converting the conditional independence test into a classification problem. This allows us to harness very powerful classifiers like gradient-boosted trees and deep neural networks. These models can handle complex probability distributions and allow us to perform significantly better compared to the prior state of the art, for high-dimensional CI testing. The main technical challenge in the classification problem is the need for samples from the conditional product distribution $f^{CI}(x,y,z) = f(x|z)f(y|z)f(z)$ -- the joint distribution if and only if $X \perp Y | Z.$ -- when given access only to i.i.d. samples from the true joint distribution $f(x,y,z)$. To tackle this problem we propose a novel nearest neighbor bootstrap procedure and theoretically show that our generated samples are indeed close to $f^{CI}$ in terms of total variational distance. We then develop theoretical results regarding the generalization bounds for classification for our problem, which translate into error bounds for CI testing. We provide a novel analysis of Rademacher type classification bounds in the presence of non-i.i.d near-independent samples. We empirically validate the performance of our algorithm on simulated and real datasets and show performance gains over previous methods.
CausalGAN: Learning Causal Implicit Generative Models with Adversarial Training
Sep 14, 2017
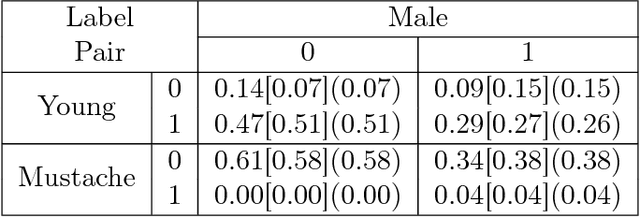

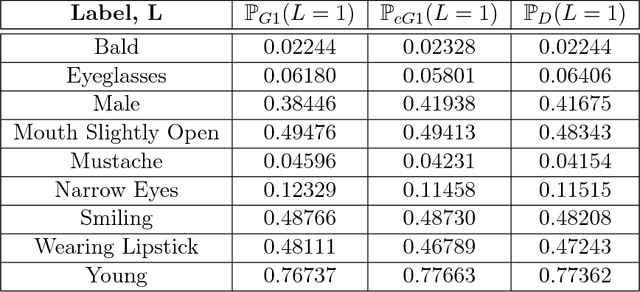
We propose an adversarial training procedure for learning a causal implicit generative model for a given causal graph. We show that adversarial training can be used to learn a generative model with true observational and interventional distributions if the generator architecture is consistent with the given causal graph. We consider the application of generating faces based on given binary labels where the dependency structure between the labels is preserved with a causal graph. This problem can be seen as learning a causal implicit generative model for the image and labels. We devise a two-stage procedure for this problem. First we train a causal implicit generative model over binary labels using a neural network consistent with a causal graph as the generator. We empirically show that WassersteinGAN can be used to output discrete labels. Later, we propose two new conditional GAN architectures, which we call CausalGAN and CausalBEGAN. We show that the optimal generator of the CausalGAN, given the labels, samples from the image distributions conditioned on these labels. The conditional GAN combined with a trained causal implicit generative model for the labels is then a causal implicit generative model over the labels and the generated image. We show that the proposed architectures can be used to sample from observational and interventional image distributions, even for interventions which do not naturally occur in the dataset.
Identifying Best Interventions through Online Importance Sampling
Mar 09, 2017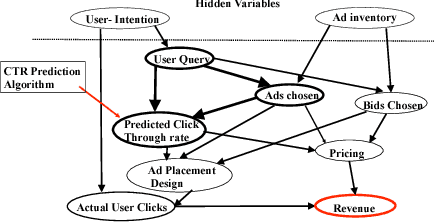
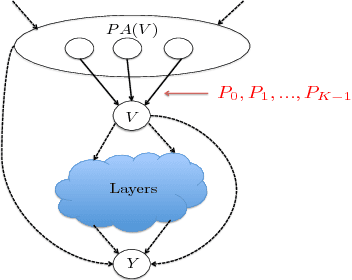
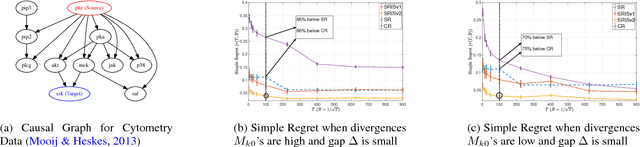

Motivated by applications in computational advertising and systems biology, we consider the problem of identifying the best out of several possible soft interventions at a source node $V$ in an acyclic causal directed graph, to maximize the expected value of a target node $Y$ (located downstream of $V$). Our setting imposes a fixed total budget for sampling under various interventions, along with cost constraints on different types of interventions. We pose this as a best arm identification bandit problem with $K$ arms where each arm is a soft intervention at $V,$ and leverage the information leakage among the arms to provide the first gap dependent error and simple regret bounds for this problem. Our results are a significant improvement over the traditional best arm identification results. We empirically show that our algorithms outperform the state of the art in the Flow Cytometry data-set, and also apply our algorithm for model interpretation of the Inception-v3 deep net that classifies images.
Compressed Sensing using Generative Models
Mar 09, 2017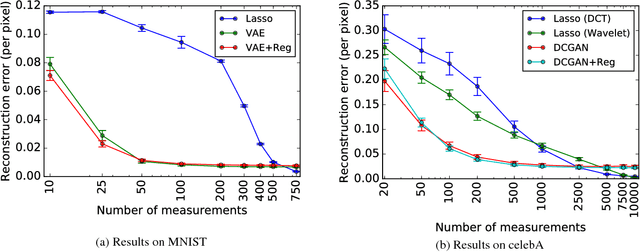
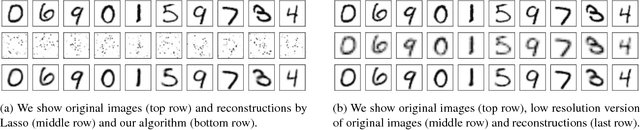


The goal of compressed sensing is to estimate a vector from an underdetermined system of noisy linear measurements, by making use of prior knowledge on the structure of vectors in the relevant domain. For almost all results in this literature, the structure is represented by sparsity in a well-chosen basis. We show how to achieve guarantees similar to standard compressed sensing but without employing sparsity at all. Instead, we suppose that vectors lie near the range of a generative model $G: \mathbb{R}^k \to \mathbb{R}^n$. Our main theorem is that, if $G$ is $L$-Lipschitz, then roughly $O(k \log L)$ random Gaussian measurements suffice for an $\ell_2/\ell_2$ recovery guarantee. We demonstrate our results using generative models from published variational autoencoder and generative adversarial networks. Our method can use $5$-$10$x fewer measurements than Lasso for the same accuracy.
Scalable Greedy Feature Selection via Weak Submodularity
Mar 08, 2017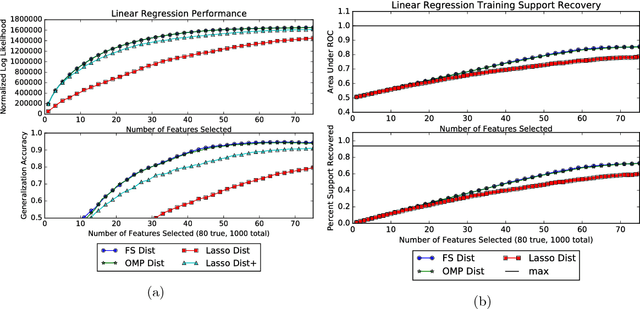
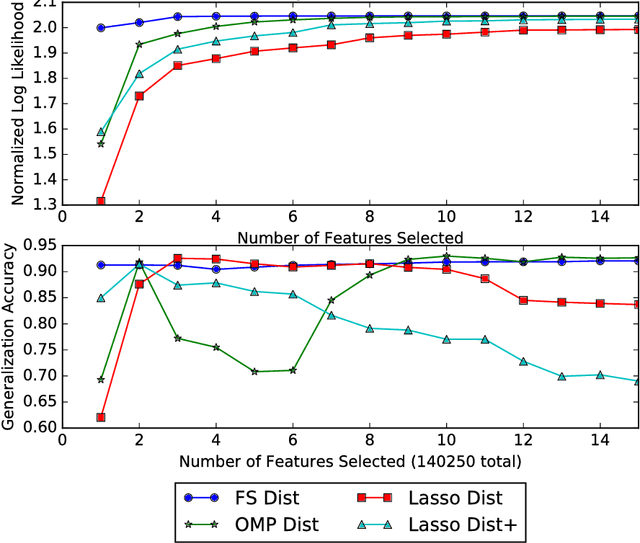
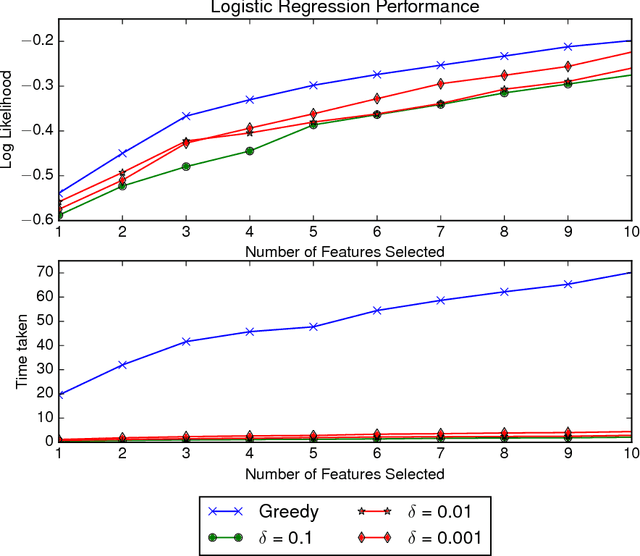
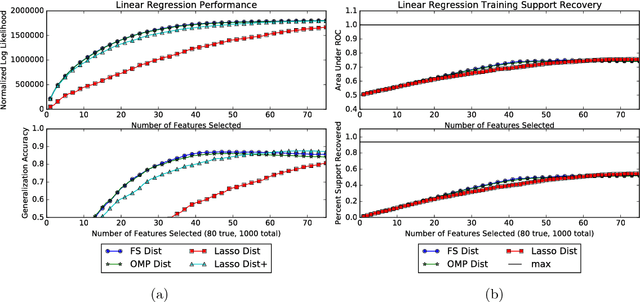
Greedy algorithms are widely used for problems in machine learning such as feature selection and set function optimization. Unfortunately, for large datasets, the running time of even greedy algorithms can be quite high. This is because for each greedy step we need to refit a model or calculate a function using the previously selected choices and the new candidate. Two algorithms that are faster approximations to the greedy forward selection were introduced recently ([Mirzasoleiman et al. 2013, 2015]). They achieve better performance by exploiting distributed computation and stochastic evaluation respectively. Both algorithms have provable performance guarantees for submodular functions. In this paper we show that divergent from previously held opinion, submodularity is not required to obtain approximation guarantees for these two algorithms. Specifically, we show that a generalized concept of weak submodularity suffices to give multiplicative approximation guarantees. Our result extends the applicability of these algorithms to a larger class of functions. Furthermore, we show that a bounded submodularity ratio can be used to provide data dependent bounds that can sometimes be tighter also for submodular functions. We empirically validate our work by showing superior performance of fast greedy approximations versus several established baselines on artificial and real datasets.