 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Selection Through Sparse Maximum Likelihood Estimation
Jul 04, 2007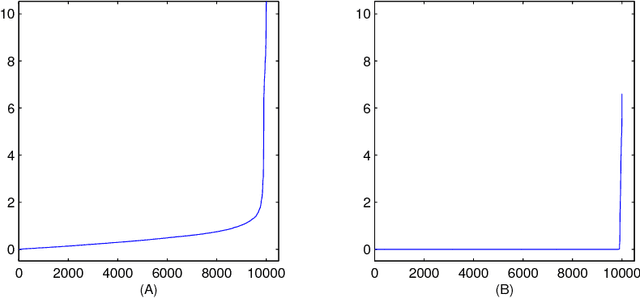

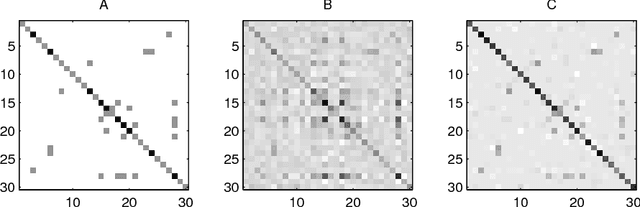
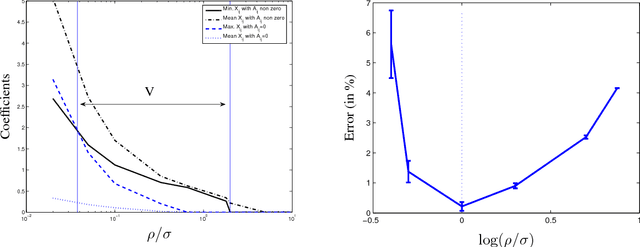
We consider the problem of estimating the parameters of a Gaussian or binary distribution in such a way that the resulting undirected graphical model is sparse. Our approach is to solve a maximum likelihood problem with an added l_1-norm penalty term. The problem as formulated is convex but the memory requirements and complexity of existing interior point methods are prohibitive for problems with more than tens of nodes. We present two new algorithms for solving problems with at least a thousand nodes in the Gaussian case. Our first algorithm uses block coordinate descent, and can be interpreted as recursive l_1-norm penalized regression. Our second algorithm, based on Nesterov's first order method, yields a complexity estimate with a better dependence on problem size than existing interior point methods. Using a log determinant relaxation of the log partition function (Wainwright & Jordan (2006)), we show that these same algorithms can be used to solve an approximate sparse maximum likelihood problem for the binary case. We test our algorithms on synthetic data, as well as on gene expression and senate voting records data.
Sparse Covariance Selection via Robust Maximum Likelihood Estimation
Jun 08, 2005
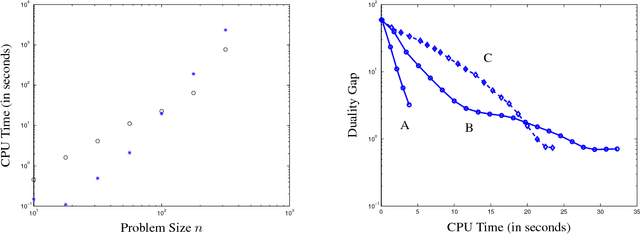
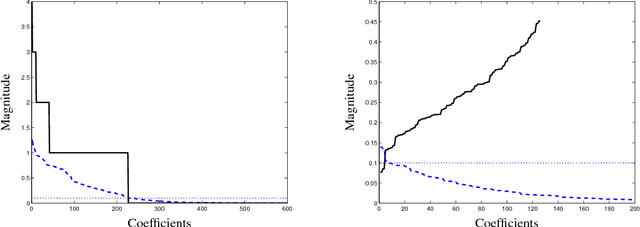
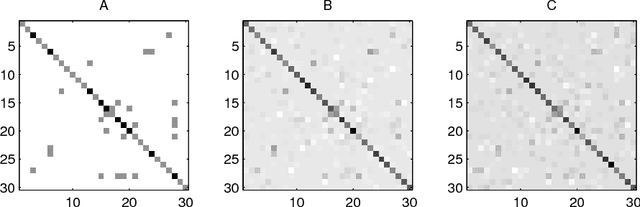
We address a problem of covariance selection, where we seek a trade-off between a high likelihood against the number of non-zero elements in the inverse covariance matrix. We solve a maximum likelihood problem with a penalty term given by the sum of absolute values of the elements of the inverse covariance matrix, and allow for imposing bounds on the condition number of the solution. The problem is directly amenable to now standard interior-point algorithms for convex optimization, but remains challenging due to its size. We first give some results on the theoretical computational complexity of the problem, by showing that a recent methodology for non-smooth convex optimization due to Nesterov can be applied to this problem, to greatly improve on the complexity estimate given by interior-point algorithms. We then examine two practical algorithms aimed at solving large-scale, noisy (hence dense) instances: one is based on a block-coordinate descent approach, where columns and rows are updated sequentially, another applies a dual version of Nesterov's method.