 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexander Levine
Tight Second-Order Certificates for Randomized Smoothing
Oct 20, 2020
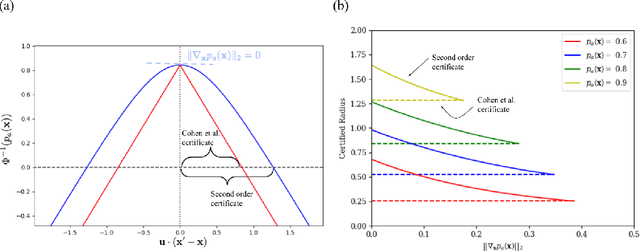

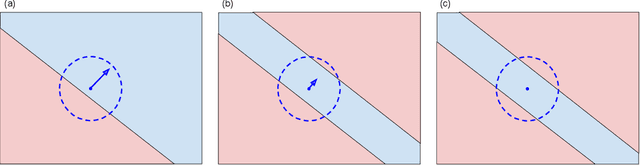
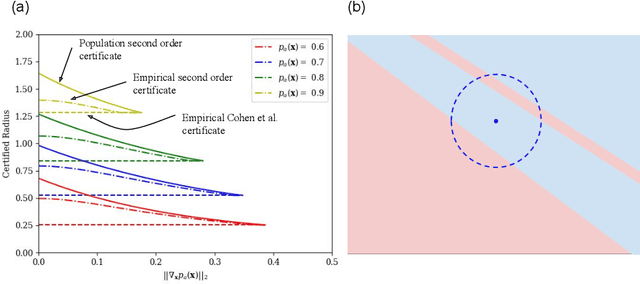
Randomized smoothing is a popular way of providing robustness guarantees against adversarial attacks: randomly-smoothed functions have a universal Lipschitz-like bound, allowing for robustness certificates to be easily computed. In this work, we show that there also exists a universal curvature-like bound for Gaussian random smoothing: given the exact value and gradient of a smoothed function, we compute a lower bound on the distance of a point to its closest adversarial example, called the Second-order Smoothing (SoS) robustness certificate. In addition to proving the correctness of this novel certificate, we show that SoS certificates are realizable and therefore tight. Interestingly, we show that the maximum achievable benefits, in terms of certified robustness, from using the additional information of the gradient norm are relatively small: because our bounds are tight, this is a fundamental negative result. The gain of SoS certificates further diminishes if we consider the estimation error of the gradient norms, for which we have developed an estimator. We therefore additionally develop a variant of Gaussian smoothing, called \textit{Gaussian dipole smoothing}, which provides similar bounds to randomized smoothing with gradient information, but with much-improved sample efficiency. This allows us to achieve (marginally) improved robustness certificates on high-dimensional datasets such as CIFAR-10 and ImageNet. Code is available at https://github.com/alevine0/smoothing_second_order.
Certifying Confidence via Randomized Smoothing
Sep 17, 2020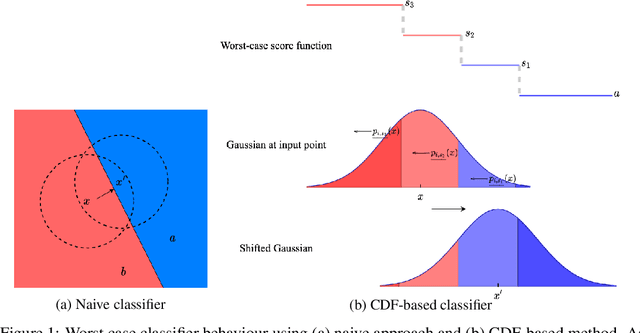
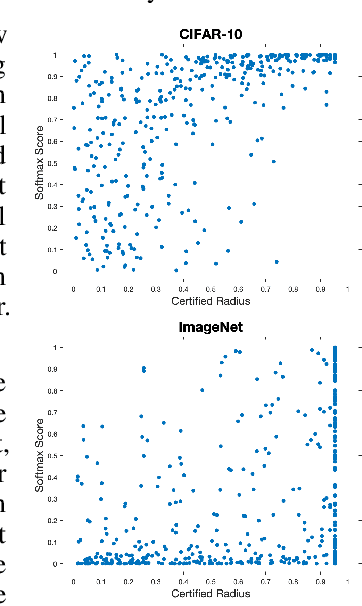

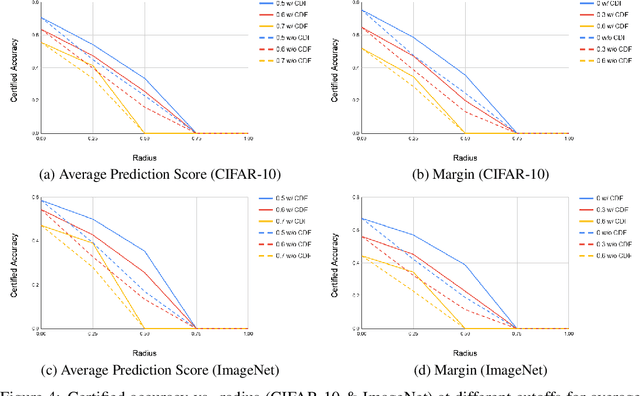
Randomized smoothing has been shown to provide good certified-robustness guarantees for high-dimensional classification problems. It uses the probabilities of predicting the top two most-likely classes around an input point under a smoothing distribution to generate a certified radius for a classifier's prediction. However, most smoothing methods do not give us any information about the \emph{confidence} with which the underlying classifier (e.g., deep neural network) makes a prediction. In this work, we propose a method to generate certified radii for the prediction confidence of the smoothed classifier. We consider two notions for quantifying confidence: average prediction score of a class and the margin by which the average prediction score of one class exceeds that of another. We modify the Neyman-Pearson lemma (a key theorem in randomized smoothing) to design a procedure for computing the certified radius where the confidence is guaranteed to stay above a certain threshold. Our experimental results on CIFAR-10 and ImageNet datasets show that using information about the distribution of the confidence scores allows us to achieve a significantly better certified radius than ignoring it. Thus, we demonstrate that extra information about the base classifier at the input point can help improve certified guarantees for the smoothed classifier.
Dual Manifold Adversarial Robustness: Defense against Lp and non-Lp Adversarial Attacks
Sep 05, 2020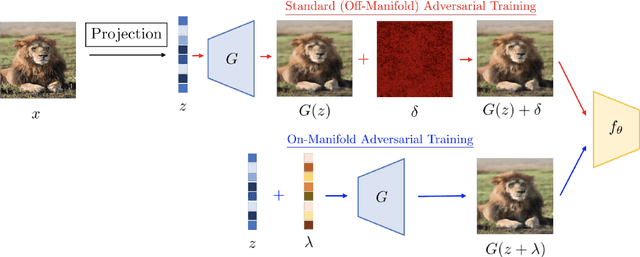



Adversarial training is a popular defense strategy against attack threat models with bounded Lp norms. However, it often degrades the model performance on normal images and the defense does not generalize well to novel attacks. Given the success of deep generative models such as GANs and VAEs in characterizing the underlying manifold of images, we investigate whether or not the aforementioned problems can be remedied by exploiting the underlying manifold information. To this end, we construct an "On-Manifold ImageNet" (OM-ImageNet) dataset by projecting the ImageNet samples onto the manifold learned by StyleGSN. For this dataset, the underlying manifold information is exact. Using OM-ImageNet, we first show that adversarial training in the latent space of images improves both standard accuracy and robustness to on-manifold attacks. However, since no out-of-manifold perturbations are realized, the defense can be broken by Lp adversarial attacks. We further propose Dual Manifold Adversarial Training (DMAT) where adversarial perturbations in both latent and image spaces are used in robustifying the model. Our DMAT improves performance on normal images, and achieves comparable robustness to the standard adversarial training against Lp attacks. In addition, we observe that models defended by DMAT achieve improved robustness against novel attacks which manipulate images by global color shifts or various types of image filtering. Interestingly, similar improvements are also achieved when the defended models are tested on out-of-manifold natural images. These results demonstrate the potential benefits of using manifold information in enhancing robustness of deep learning models against various types of novel adversarial attacks.
Deep Partition Aggregation: Provable Defense against General Poisoning Attacks
Jun 26, 2020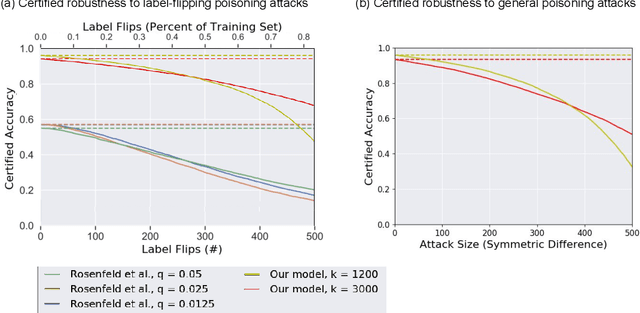
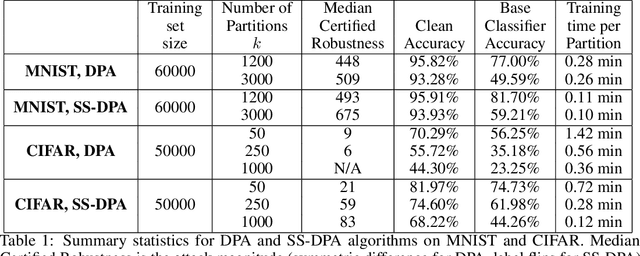
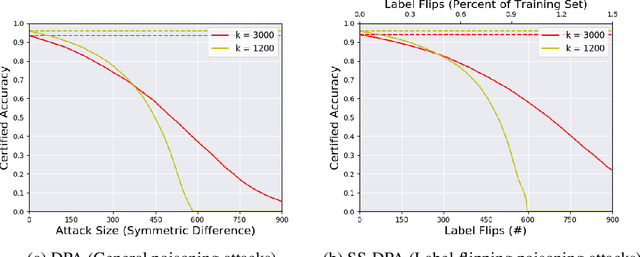
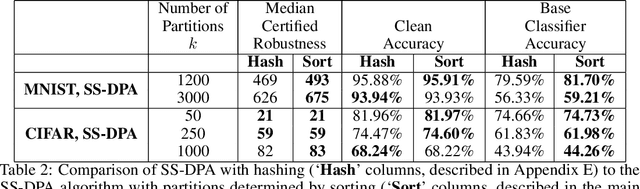
Adversarial poisoning attacks distort training data in order to corrupt the test-time behavior of a classifier. A provable defense provides a certificate for each test sample, which is a lower bound on the magnitude of any adversarial distortion of the training set that can corrupt the test sample's classification. We propose two provable defenses against poisoning attacks: (i) Deep Partition Aggregation (DPA), a certified defense against a general poisoning threat model, defined as the insertion or deletion of a bounded number of samples to the training set -- by implication, this threat model also includes arbitrary distortions to a bounded number of images and/or labels; and (ii) Semi-Supervised DPA (SS-DPA), a certified defense against label-flipping poisoning attacks. DPA is an ensemble method where base models are trained on partitions of the training set determined by a hash function. DPA is related to subset aggregation, a well-studied ensemble method in classical machine learning. DPA can also be viewed as an extension of randomized ablation (Levine & Feizi, 2020a), a certified defense against sparse evasion attacks, to the poisoning domain. Our label-flipping defense, SS-DPA, uses a semi-supervised learning algorithm as its base classifier model: we train each base classifier using the entire unlabeled training set in addition to the labels for a partition. SS-DPA outperforms the existing certified defense for label-flipping attacks (Rosenfeld et al., 2020). SS-DPA certifies >= 50% of test images against 675 label flips (vs. < 200 label flips with the existing defense) on MNIST and 83 label flips on CIFAR-10. Against general poisoning attacks (no prior certified defense), DPA certifies >= 50% of test images against > 500 poison image insertions on MNIST, and nine insertions on CIFAR-10. These results establish new state-of-the-art provable defenses against poison attacks.
(De)Randomized Smoothing for Certifiable Defense against Patch Attacks
Feb 25, 2020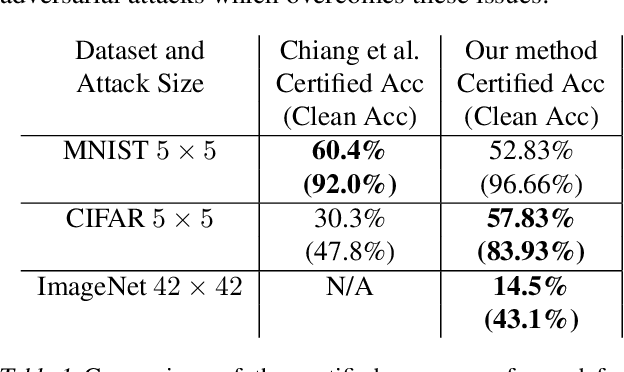

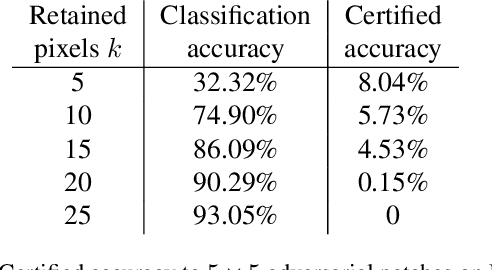

Patch adversarial attacks on images, in which the attacker can distort pixels within a region of bounded size, are an important threat model since they provide a quantitative model for physical adversarial attacks. In this paper, we introduce a certifiable defense against patch attacks that guarantees for a given image and patch attack size, no patch adversarial examples exist. Our method is related to the broad class of randomized smoothing robustness schemes which provide high-confidence probabilistic robustness certificates. By exploiting the fact that patch attacks are more constrained than general sparse attacks, we derive meaningfully large robustness certificates. Additionally, the algorithm we propose is de-randomized, providing deterministic certificates. To the best of our knowledge, there exists only one prior method for certifiable defense against patch attacks, which relies on interval bound propagation. While this sole existing method performs well on MNIST, it has several limitations: it requires computationally expensive training, does not scale to ImageNet, and performs poorly on CIFAR-10. In contrast, our proposed method effectively addresses all of these issues: our classifier can be trained quickly, achieves high clean and certified robust accuracy on CIFAR-10, and provides certificates at the ImageNet scale. For example, for a 5*5 patch attack on CIFAR-10, our method achieves up to around 57.8% certified accuracy (with a classifier around 83.9% clean accuracy), compared to at most 30.3% certified accuracy for the existing method (with a classifier with around 47.8% clean accuracy), effectively establishing a new state-of-the-art. Code is available at https://github.com/alevine0/patchSmoothing.
Curse of Dimensionality on Randomized Smoothing for Certifiable Robustness
Feb 08, 2020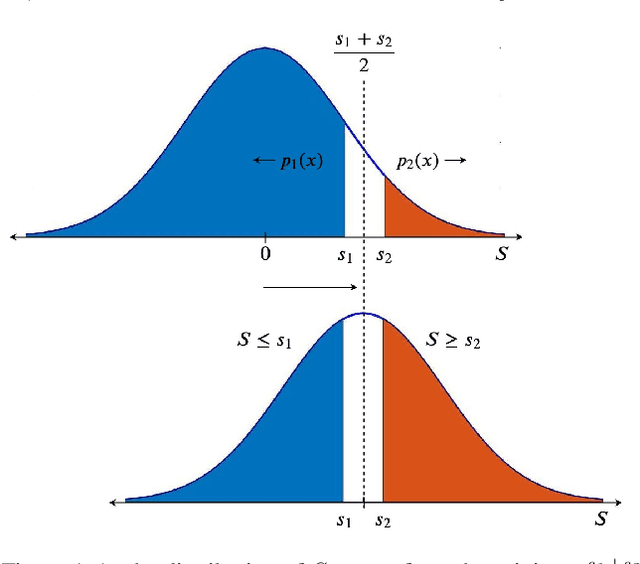
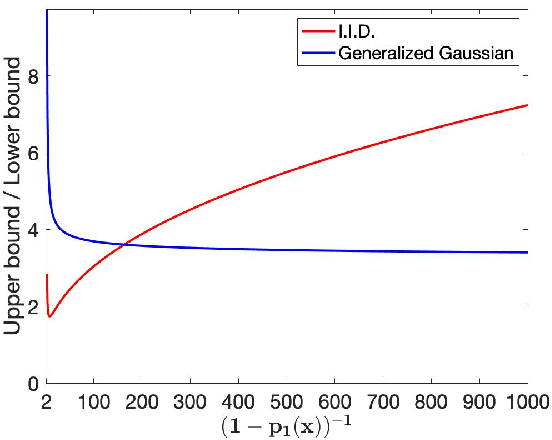
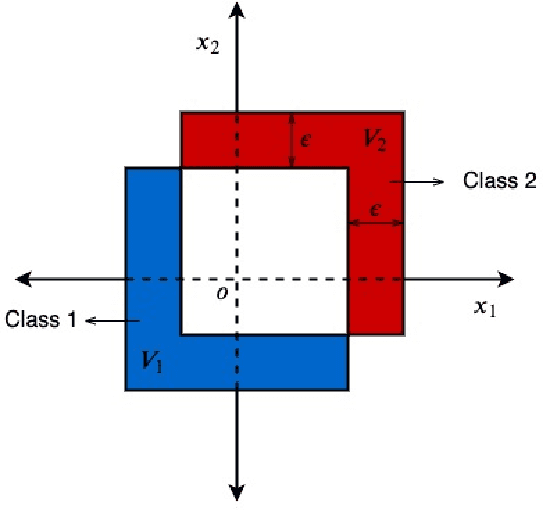
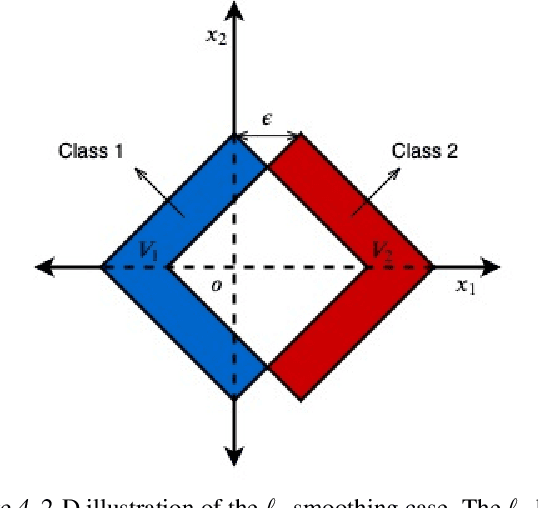
Randomized smoothing, using just a simple isotropic Gaussian distribution, has been shown to produce good robustness guarantees against $\ell_2$-norm bounded adversaries. In this work, we show that extending the smoothing technique to defend against other attack models can be challenging, especially in the high-dimensional regime. In particular, for a vast class of i.i.d. smoothing distributions, we prove that the largest $\ell_p$-radius that can be certified decreases as $O(1/d^{\frac{1}{2} - \frac{1}{p}})$ with dimension $d$ for $p > 2$. Notably, for $p \geq 2$, this dependence on $d$ is no better than that of the $\ell_p$-radius that can be certified using isotropic Gaussian smoothing, essentially putting a matching lower bound on the robustness radius. When restricted to generalized Gaussian smoothing, these two bounds can be shown to be within a constant factor of each other in an asymptotic sense, establishing that Gaussian smoothing provides the best possible results, up to a constant factor, when $p \geq 2$. We present experimental results on CIFAR to validate our theory. For other smoothing distributions, such as, a uniform distribution within an $\ell_1$ or an $\ell_\infty$-norm ball, we show upper bounds of the form $O(1 / d)$ and $O(1 / d^{1 - \frac{1}{p}})$ respectively, which have an even worse dependence on $d$.
Robustness Certificates for Sparse Adversarial Attacks by Randomized Ablation
Nov 21, 2019
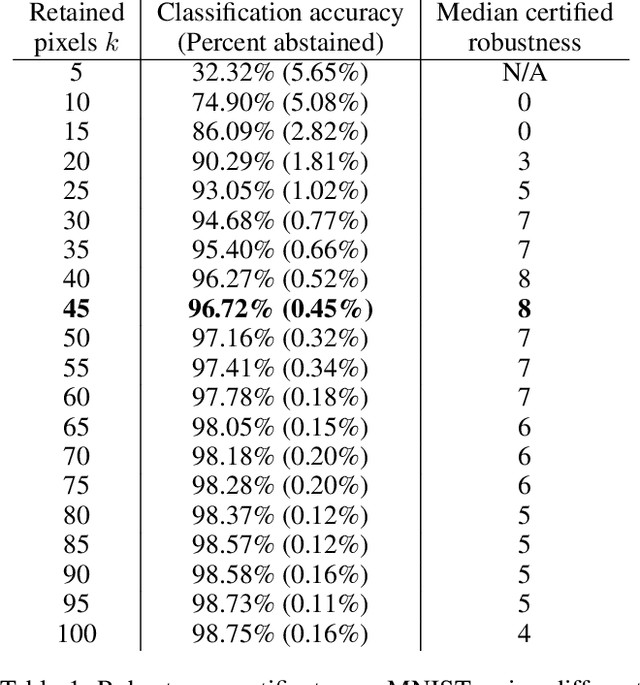
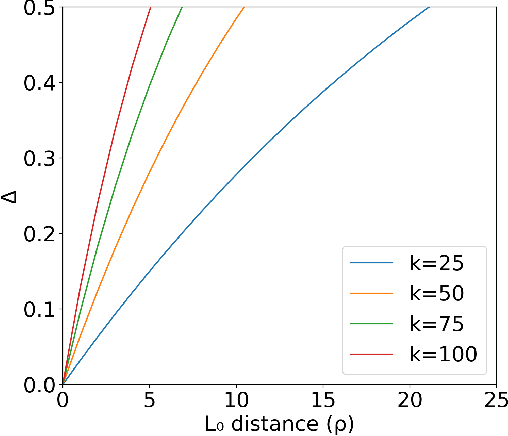
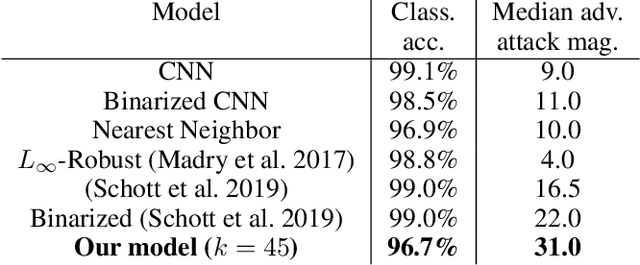
Recently, techniques have been developed to provably guarantee the robustness of a classifier to adversarial perturbations of bounded L_1 and L_2 magnitudes by using randomized smoothing: the robust classification is a consensus of base classifications on randomly noised samples where the noise is additive. In this paper, we extend this technique to the L_0 threat model. We propose an efficient and certifiably robust defense against sparse adversarial attacks by randomly ablating input features, rather than using additive noise. Experimentally, on MNIST, we can certify the classifications of over 50% of images to be robust to any distortion of at most 8 pixels. This is comparable to the observed empirical robustness of unprotected classifiers on MNIST to modern L_0 attacks, demonstrating the tightness of the proposed robustness certificate. We also evaluate our certificate on ImageNet and CIFAR-10. Our certificates represent an improvement on those provided in a concurrent work (Lee et al. 2019) which uses random noise rather than ablation (median certificates of 8 pixels versus 4 pixels on MNIST; 16 pixels versus 1 pixel on ImageNet.) Additionally, we empirically demonstrate that our classifier is highly robust to modern sparse adversarial attacks on MNIST. Our classifications are robust, in median, to adversarial perturbations of up to 31 pixels, compared to 22 pixels reported as the state-of-the-art defense, at the cost of a slight decrease (around 2.3%) in the classification accuracy. Code is available at https://github.com/alevine0/randomizedAblation/.
Wasserstein Smoothing: Certified Robustness against Wasserstein Adversarial Attacks
Oct 23, 2019
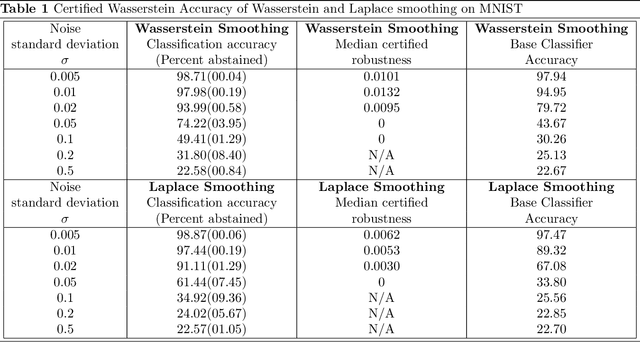

In the last couple of years, several adversarial attack methods based on different threat models have been proposed for the image classification problem. Most existing defenses consider additive threat models in which sample perturbations have bounded L_p norms. These defenses, however, can be vulnerable against adversarial attacks under non-additive threat models. An example of an attack method based on a non-additive threat model is the Wasserstein adversarial attack proposed by Wong et al. (2019), where the distance between an image and its adversarial example is determined by the Wasserstein metric ("earth-mover distance") between their normalized pixel intensities. Until now, there has been no certifiable defense against this type of attack. In this work, we propose the first defense with certified robustness against Wasserstein Adversarial attacks using randomized smoothing. We develop this certificate by considering the space of possible flows between images, and representing this space such that Wasserstein distance between images is upper-bounded by L_1 distance in this flow-space. We can then apply existing randomized smoothing certificates for the L_1 metric. In MNIST and CIFAR-10 datasets, we find that our proposed defense is also practically effective, demonstrating significantly improved accuracy under Wasserstein adversarial attack compared to unprotected models.
Certifiably Robust Interpretation in Deep Learning
Jun 10, 2019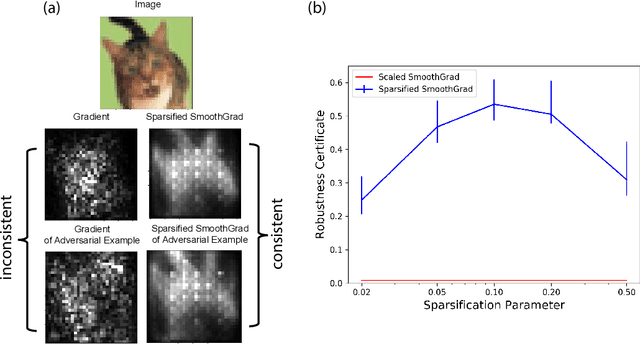

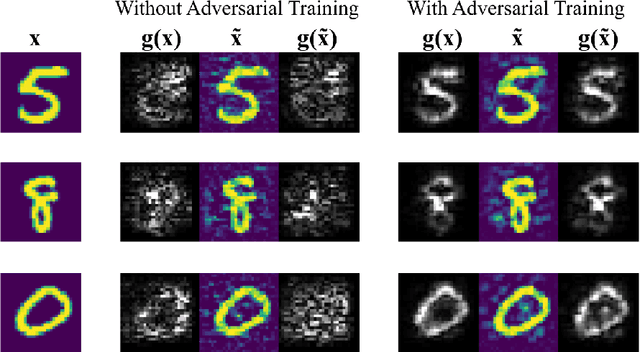

Although gradient-based saliency maps are popular methods for deep learning interpretation, they can be extremely vulnerable to adversarial attacks. This is worrisome especially due to the lack of practical defenses for protecting deep learning interpretations against attacks. In this paper, we address this problem and provide two defense methods for deep learning interpretation. First, we show that a sparsified version of the popular SmoothGrad method, which computes the average saliency maps over random perturbations of the input, is certifiably robust against adversarial perturbations. We obtain this result by extending recent bounds for certifiably robust smooth classifiers to the interpretation setting. Experiments on ImageNet samples validate our theory. Second, we introduce an adversarial training approach to further robustify deep learning interpretation by adding a regularization term to penalize the inconsistency of saliency maps between normal and crafted adversarial samples. Empirically, we observe that this approach not only improves the robustness of deep learning interpretation to adversarial attacks, but it also improves the quality of the gradient-based saliency maps.