 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Reader-Parser on Hybrid Textual and Tabular Evidence for Open Domain Question Answering
Aug 05, 2021
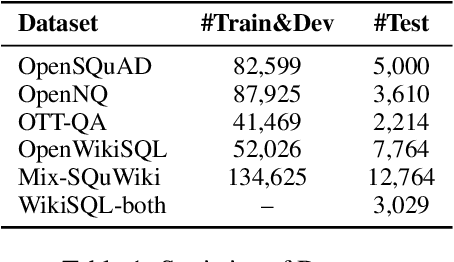
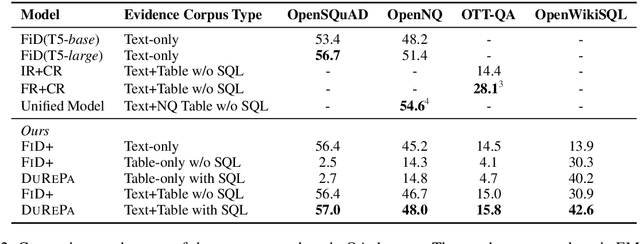
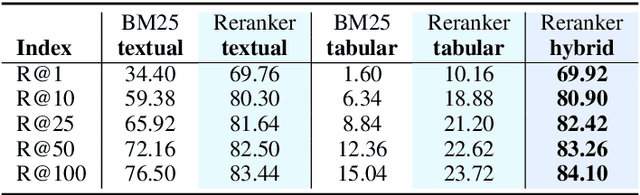
The current state-of-the-art generative models for open-domain question answering (ODQA) have focused on generating direct answers from unstructured textual information. However, a large amount of world's knowledge is stored in structured databases, and need to be accessed using query languages such as SQL. Furthermore, query languages can answer questions that require complex reasoning, as well as offering full explainability. In this paper, we propose a hybrid framework that takes both textual and tabular evidence as input and generates either direct answers or SQL queries depending on which form could better answer the question. The generated SQL queries can then be executed on the associated databases to obtain the final answers. To the best of our knowledge, this is the first paper that applies Text2SQL to ODQA tasks. Empirically, we demonstrate that on several ODQA datasets, the hybrid methods consistently outperforms the baseline models that only take homogeneous input by a large margin. Specifically we achieve state-of-the-art performance on OpenSQuAD dataset using a T5-base model. In a detailed analysis, we demonstrate that the being able to generate structural SQL queries can always bring gains, especially for those questions that requires complex reasoning.
Learning Contextual Representations for Semantic Parsing with Generation-Augmented Pre-Training
Dec 18, 2020
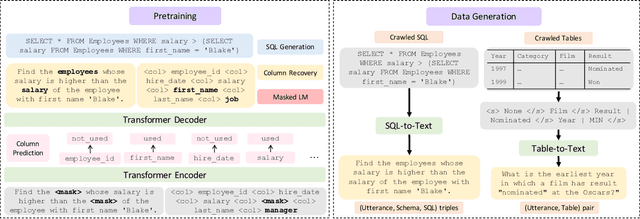
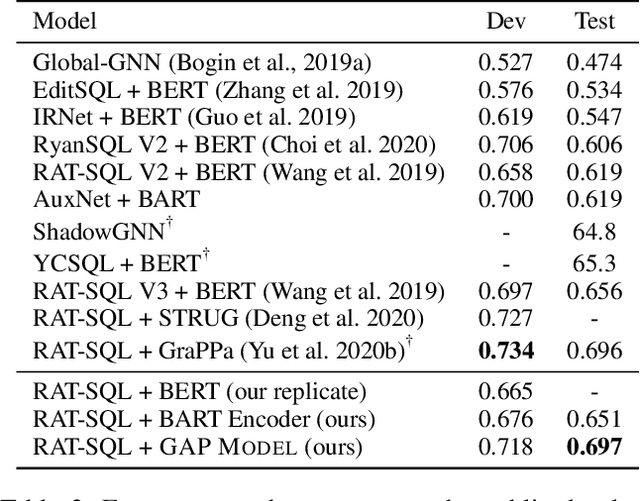
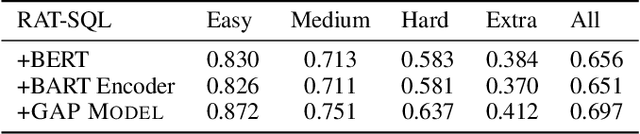
Most recently, there has been significant interest in learning contextual representations for various NLP tasks, by leveraging large scale text corpora to train large neural language models with self-supervised learning objectives, such as Masked Language Model (MLM). However, based on a pilot study, we observe three issues of existing general-purpose language models when they are applied to text-to-SQL semantic parsers: fail to detect column mentions in the utterances, fail to infer column mentions from cell values, and fail to compose complex SQL queries. To mitigate these issues, we present a model pre-training framework, Generation-Augmented Pre-training (GAP), that jointly learns representations of natural language utterances and table schemas by leveraging generation models to generate pre-train data. GAP MODEL is trained on 2M utterance-schema pairs and 30K utterance-schema-SQL triples, whose utterances are produced by generative models. Based on experimental results, neural semantic parsers that leverage GAP MODEL as a representation encoder obtain new state-of-the-art results on both SPIDER and CRITERIA-TO-SQL benchmarks.
Decomposed Adversarial Learned Inference
Apr 21, 2020

Effective inference for a generative adversarial model remains an important and challenging problem. We propose a novel approach, Decomposed Adversarial Learned Inference (DALI), which explicitly matches prior and conditional distributions in both data and code spaces, and puts a direct constraint on the dependency structure of the generative model. We derive an equivalent form of the prior and conditional matching objective that can be optimized efficiently without any parametric assumption on the data. We validate the effectiveness of DALI on the MNIST, CIFAR-10, and CelebA datasets by conducting quantitative and qualitative evaluations. Results demonstrate that DALI significantly improves both reconstruction and generation as compared to other adversarial inference models.
Censored Quantile Regression Forest
Jan 08, 2020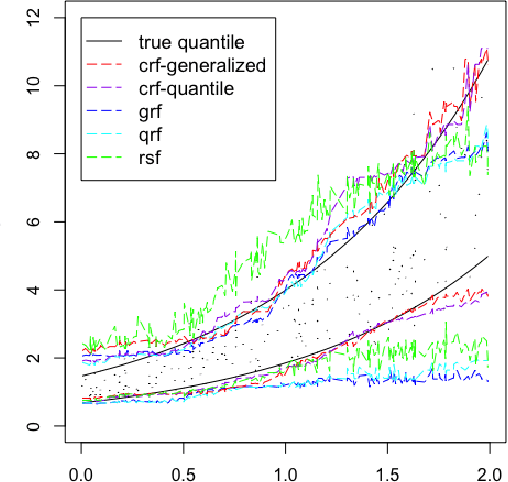
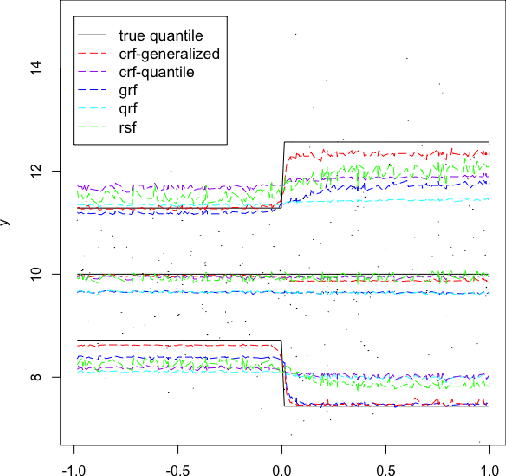
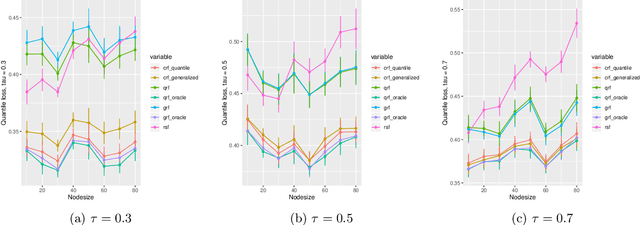
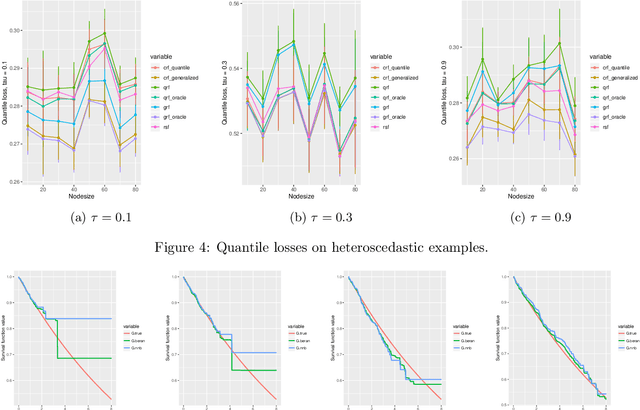
Random forests are powerful non-parametric regression method but are severely limited in their usage in the presence of randomly censored observations, and naively applied can exhibit poor predictive performance due to the incurred biases. Based on a local adaptive representation of random forests, we develop its regression adjustment for randomly censored regression quantile models. Regression adjustment is based on a new estimating equation that adapts to censoring and leads to quantile score whenever the data do not exhibit censoring. The proposed procedure named {\it censored quantile regression forest}, allows us to estimate quantiles of time-to-event without any parametric modeling assumption. We establish its consistency under mild model specifications. Numerical studies showcase a clear advantage of the proposed procedure.
* arXiv admin note: text overlap with arXiv:1902.03327
Semi-Supervised Learning for Text Classification by Layer Partitioning
Nov 26, 2019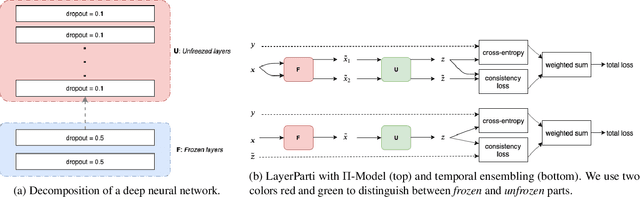
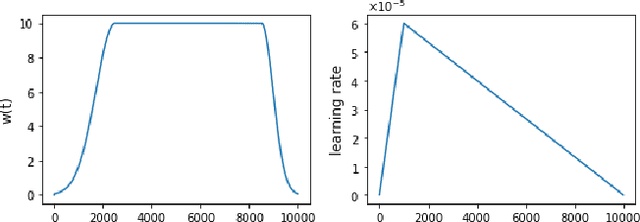
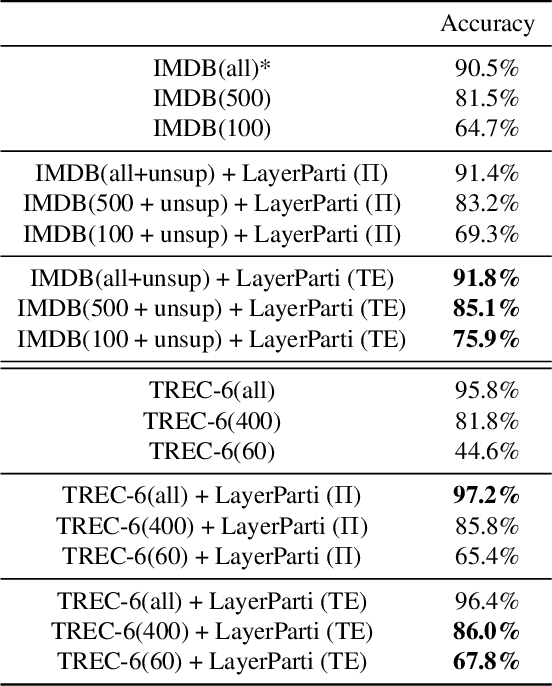
Most recent neural semi-supervised learning algorithms rely on adding small perturbation to either the input vectors or their representations. These methods have been successful on computer vision tasks as the images form a continuous manifold, but are not appropriate for discrete input such as sentence. To adapt these methods to text input, we propose to decompose a neural network $M$ into two components $F$ and $U$ so that $M = U\circ F$. The layers in $F$ are then frozen and only the layers in $U$ will be updated during most time of the training. In this way, $F$ serves as a feature extractor that maps the input to high-level representation and adds systematical noise using dropout. We can then train $U$ using any state-of-the-art SSL algorithms such as $\Pi$-model, temporal ensembling, mean teacher, etc. Furthermore, this gradually unfreezing schedule also prevents a pretrained model from catastrophic forgetting. The experimental results demonstrate that our approach provides improvements when compared to state of the art methods especially on short texts.
Knowledge Enhanced Attention for Robust Natural Language Inference
Aug 31, 2019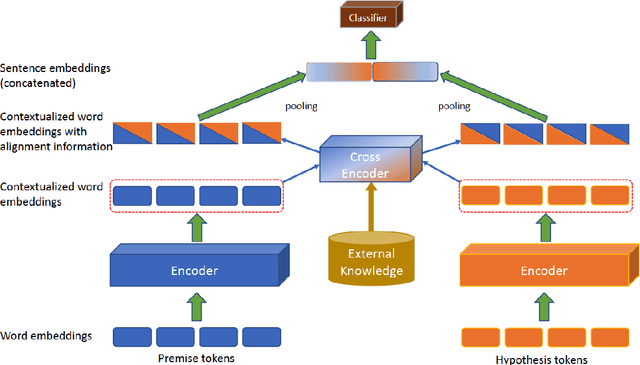
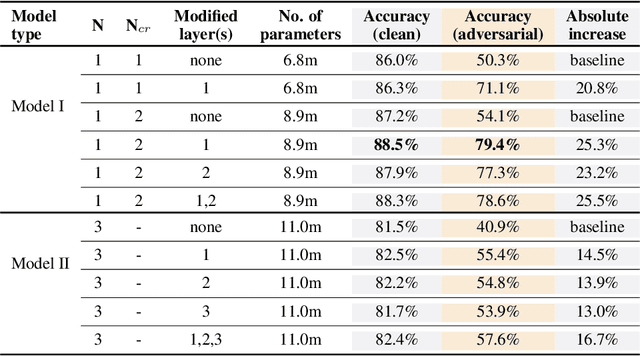
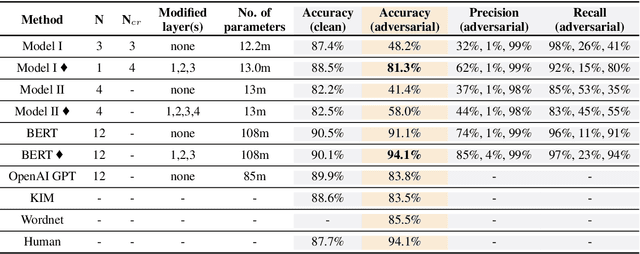
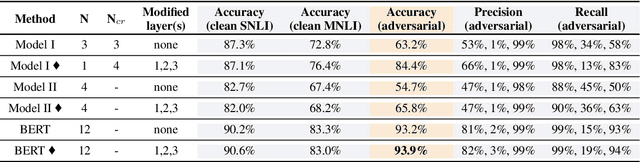
Neural network models have been very successful at achieving high accuracy on natural language inference (NLI) tasks. However, as demonstrated in recent literature, when tested on some simple adversarial examples, most of the models suffer a significant drop in performance. This raises the concern about the robustness of NLI models. In this paper, we propose to make NLI models robust by incorporating external knowledge to the attention mechanism using a simple transformation. We apply the new attention to two popular types of NLI models: one is Transformer encoder, and the other is a decomposable model, and show that our method can significantly improve their robustness. Moreover, when combined with BERT pretraining, our method achieves the human-level performance on the adversarial SNLI data set.
Censored Quantile Regression Forests
Feb 08, 2019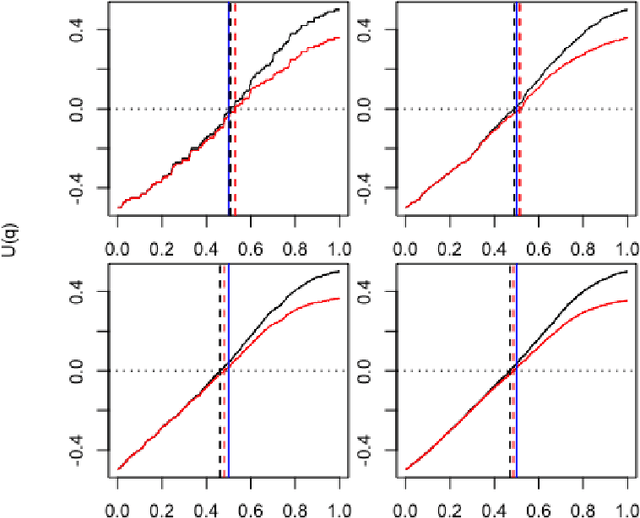
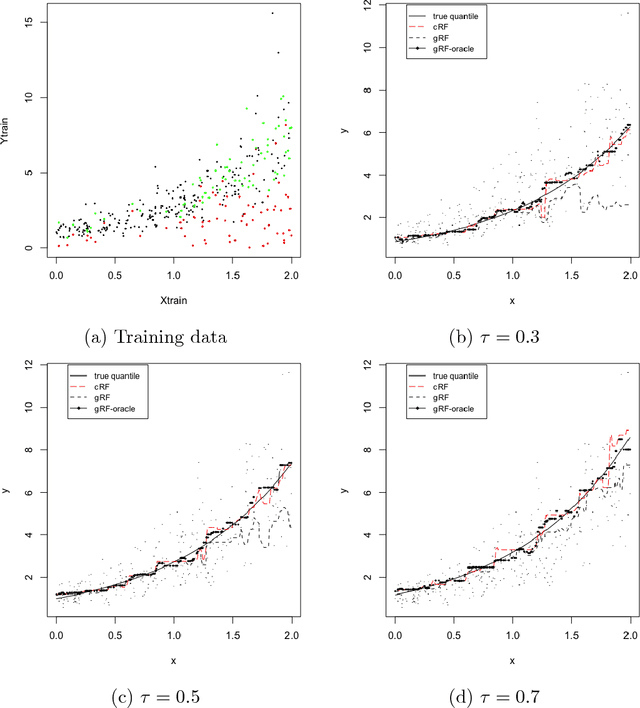
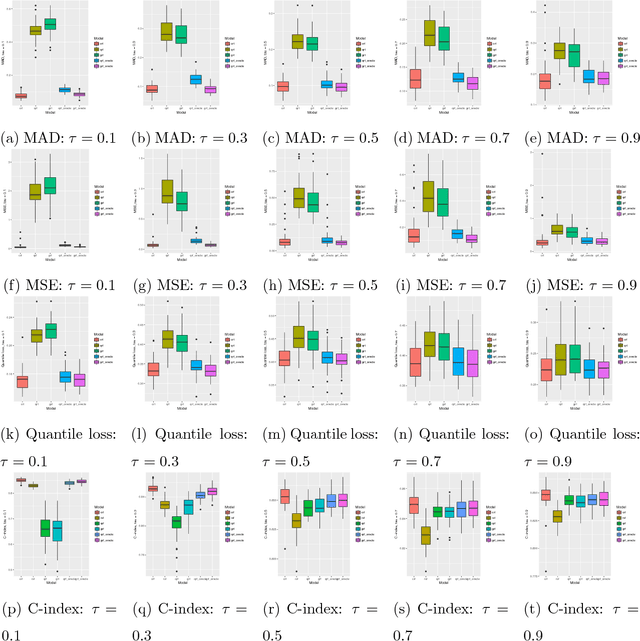
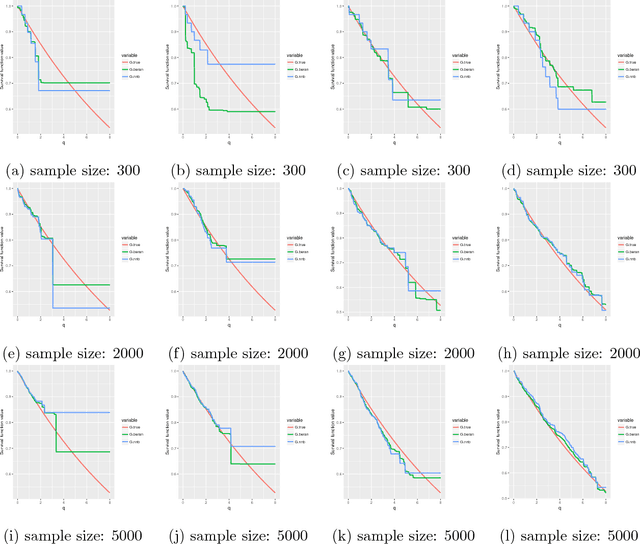
Random forests are powerful non-parametric regression method but are severely limited in their usage in the presence of randomly censored observations, and naively applied can exhibit poor predictive performance due to the incurred biases. Based on a local adaptive representation of random forests, we develop its regression adjustment for randomly censored regression quantile models. Regression adjustment is based on new estimating equations that adapt to censoring and lead to quantile score whenever the data do not exhibit censoring. The proposed procedure named censored quantile regression forest, allows us to estimate quantiles of time-to-event without any parametric modeling assumption. We establish its consistency under mild model specifications. Numerical studies showcase a clear advantage of the proposed procedure.
Boosting in the presence of outliers: adaptive classification with non-convex loss functions
Oct 05, 2015
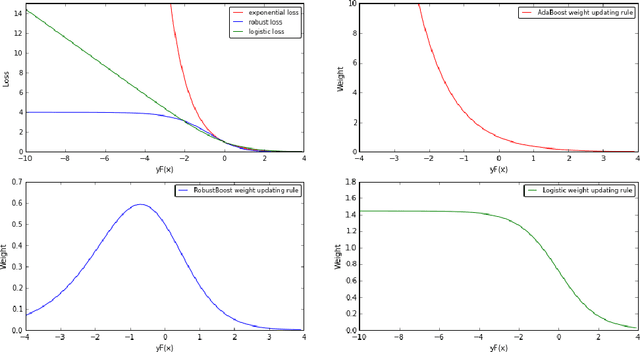

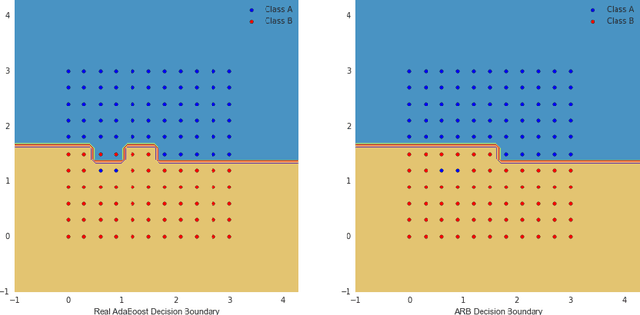
This paper examines the role and efficiency of the non-convex loss functions for binary classification problems. In particular, we investigate how to design a simple and effective boosting algorithm that is robust to the outliers in the data. The analysis of the role of a particular non-convex loss for prediction accuracy varies depending on the diminishing tail properties of the gradient of the loss -- the ability of the loss to efficiently adapt to the outlying data, the local convex properties of the loss and the proportion of the contaminated data. In order to use these properties efficiently, we propose a new family of non-convex losses named $\gamma$-robust losses. Moreover, we present a new boosting framework, {\it Arch Boost}, designed for augmenting the existing work such that its corresponding classification algorithm is significantly more adaptable to the unknown data contamination. Along with the Arch Boosting framework, the non-convex losses lead to the new class of boosting algorithms, named adaptive, robust, boosting (ARB). Furthermore, we present theoretical examples that demonstrate the robustness properties of the proposed algorithms. In particular, we develop a new breakdown point analysis and a new influence function analysis that demonstrate gains in robustness. Moreover, we present new theoretical results, based only on local curvatures, which may be used to establish statistical and optimization properties of the proposed Arch boosting algorithms with highly non-convex loss functions. Extensive numerical calculations are used to illustrate these theoretical properties and reveal advantages over the existing boosting methods when data exhibits a number of outliers.