 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexander D'Amour
Boosting the interpretability of clinical risk scores with intervention predictions
Jul 06, 2022
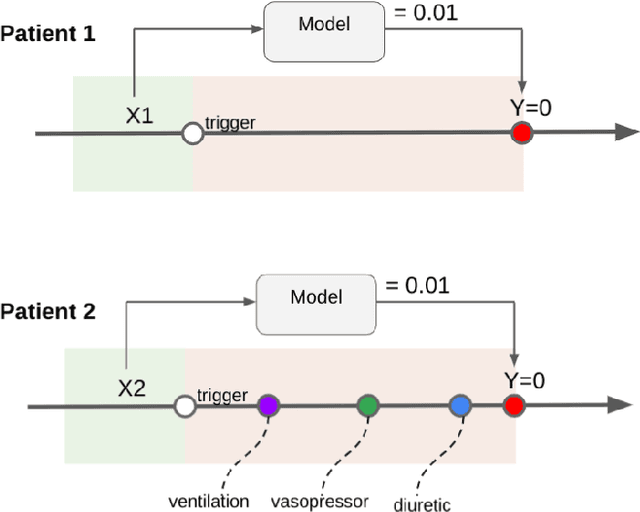
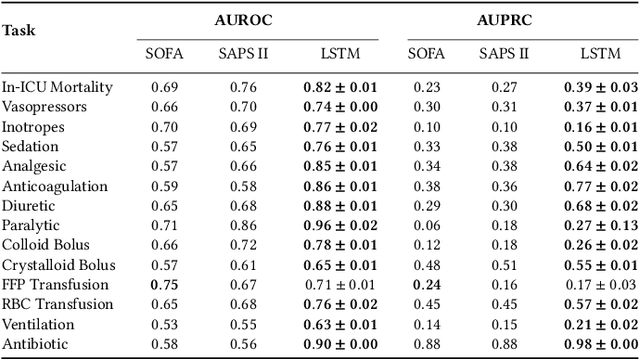
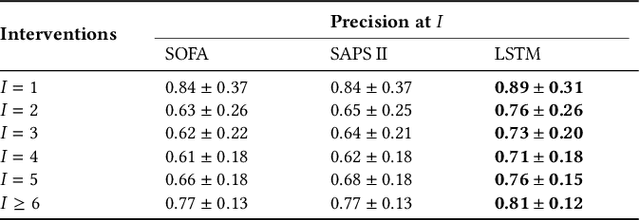
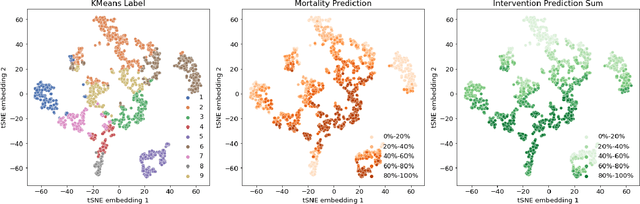
Machine learning systems show significant promise for forecasting patient adverse events via risk scores. However, these risk scores implicitly encode assumptions about future interventions that the patient is likely to receive, based on the intervention policy present in the training data. Without this important context, predictions from such systems are less interpretable for clinicians. We propose a joint model of intervention policy and adverse event risk as a means to explicitly communicate the model's assumptions about future interventions. We develop such an intervention policy model on MIMIC-III, a real world de-identified ICU dataset, and discuss some use cases that highlight the utility of this approach. We show how combining typical risk scores, such as the likelihood of mortality, with future intervention probability scores leads to more interpretable clinical predictions.
Maintaining fairness across distribution shift: do we have viable solutions for real-world applications?
Feb 02, 2022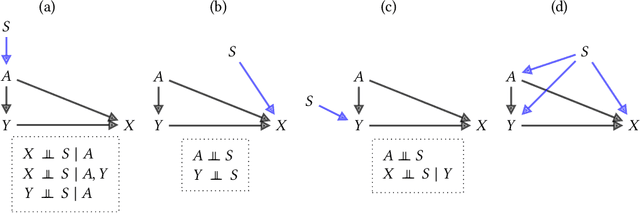
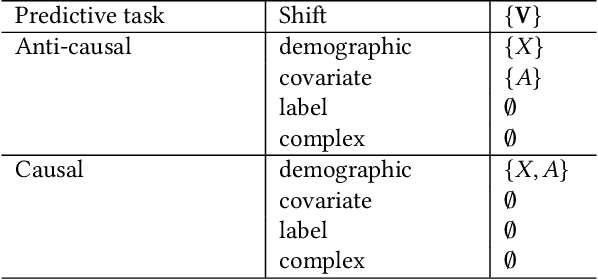
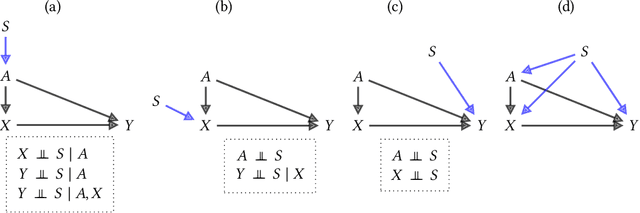
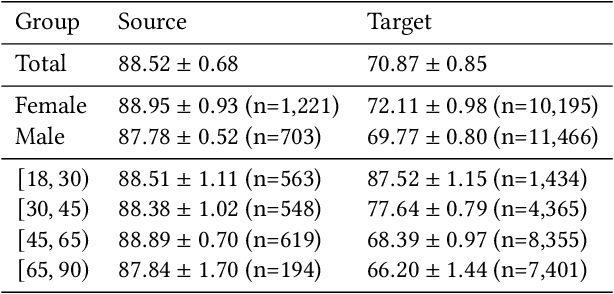
Fairness and robustness are often considered as orthogonal dimensions when evaluating machine learning models. However, recent work has revealed interactions between fairness and robustness, showing that fairness properties are not necessarily maintained under distribution shift. In healthcare settings, this can result in e.g. a model that performs fairly according to a selected metric in "hospital A" showing unfairness when deployed in "hospital B". While a nascent field has emerged to develop provable fair and robust models, it typically relies on strong assumptions about the shift, limiting its impact for real-world applications. In this work, we explore the settings in which recently proposed mitigation strategies are applicable by referring to a causal framing. Using examples of predictive models in dermatology and electronic health records, we show that real-world applications are complex and often invalidate the assumptions of such methods. Our work hence highlights technical, practical, and engineering gaps that prevent the development of robustly fair machine learning models for real-world applications. Finally, we discuss potential remedies at each step of the machine learning pipeline.
The MultiBERTs: BERT Reproductions for Robustness Analysis
Jun 30, 2021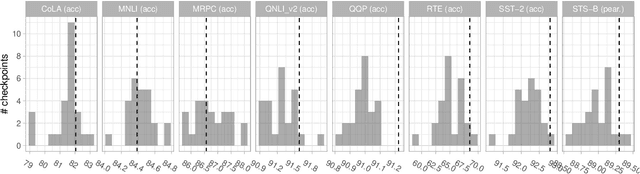
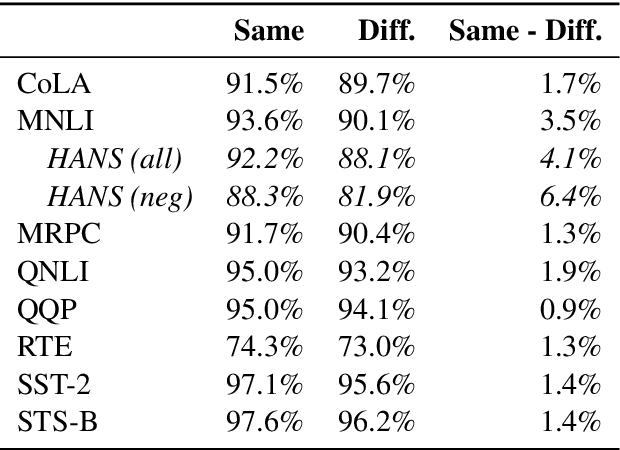
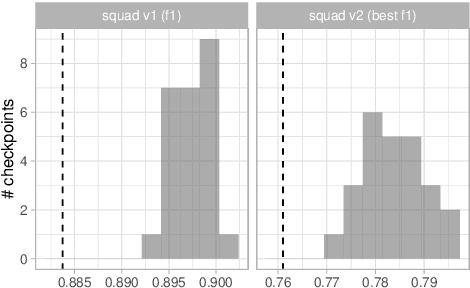
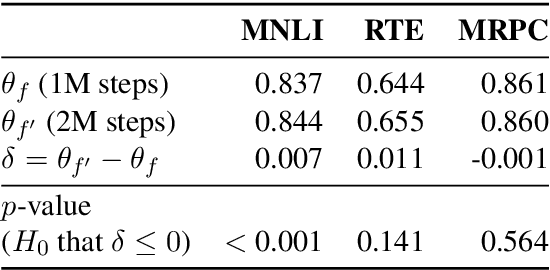
Experiments with pretrained models such as BERT are often based on a single checkpoint. While the conclusions drawn apply to the artifact (i.e., the particular instance of the model), it is not always clear whether they hold for the more general procedure (which includes the model architecture, training data, initialization scheme, and loss function). Recent work has shown that re-running pretraining can lead to substantially different conclusions about performance, suggesting that alternative evaluations are needed to make principled statements about procedures. To address this question, we introduce MultiBERTs: a set of 25 BERT-base checkpoints, trained with similar hyper-parameters as the original BERT model but differing in random initialization and data shuffling. The aim is to enable researchers to draw robust and statistically justified conclusions about pretraining procedures. The full release includes 25 fully trained checkpoints, as well as statistical guidelines and a code library implementing our recommended hypothesis testing methods. Finally, for five of these models we release a set of 28 intermediate checkpoints in order to support research on learning dynamics.
Causally-motivated Shortcut Removal Using Auxiliary Labels
Jun 03, 2021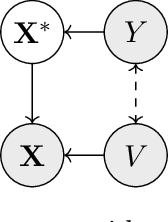

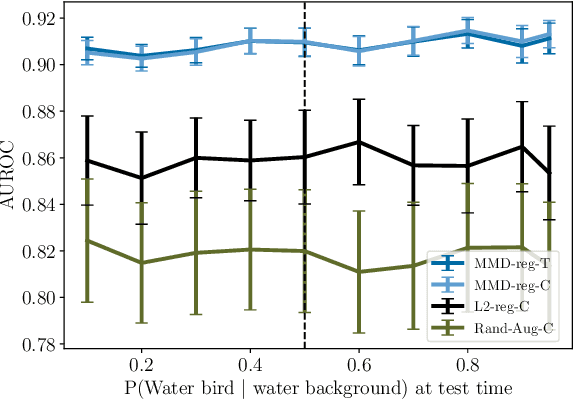
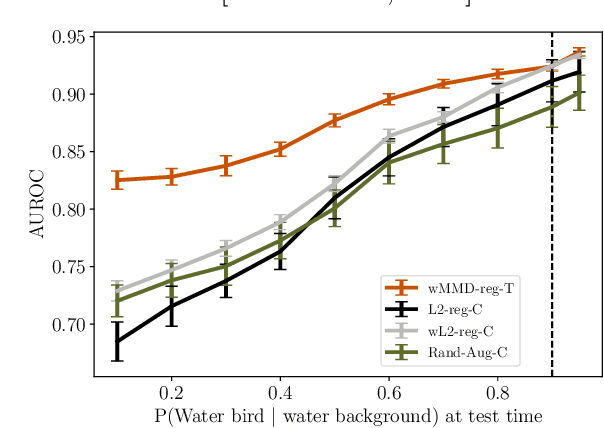
Robustness to certain forms of distribution shift is a key concern in many ML applications. Often, robustness can be formulated as enforcing invariances to particular interventions on the data generating process. Here, we study a flexible, causally-motivated approach to enforcing such invariances, paying special attention to shortcut learning, where a robust predictor can achieve optimal i.i.d generalization in principle, but instead it relies on spurious correlations or shortcuts in practice. Our approach uses auxiliary labels, typically available at training time, to enforce conditional independences between the latent factors that determine these labels. We show both theoretically and empirically that causally-motivated regularization schemes (a) lead to more robust estimators that generalize well under distribution shift, and (b) have better finite sample efficiency compared to usual regularization schemes, even in the absence of distribution shifts. Our analysis highlights important theoretical properties of training techniques commonly used in causal inference, fairness, and disentanglement literature.
Counterfactual Invariance to Spurious Correlations: Why and How to Pass Stress Tests
Jun 02, 2021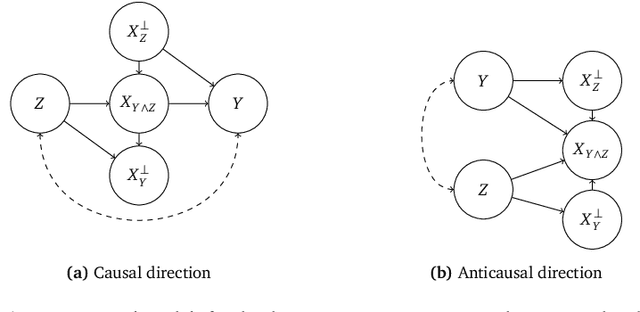

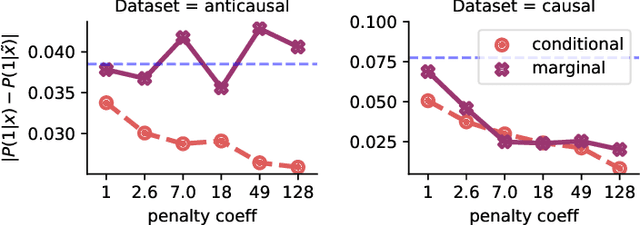
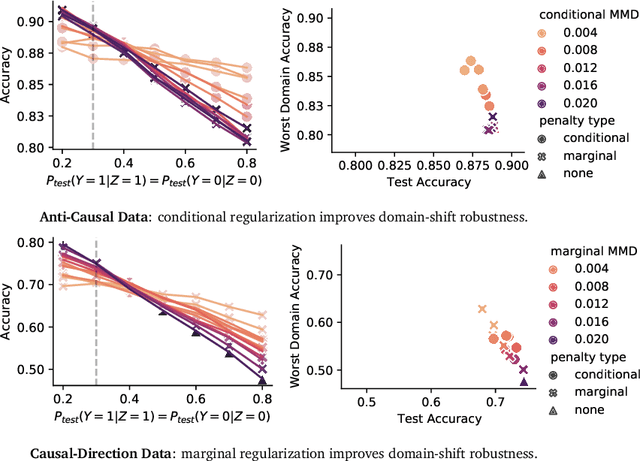
Informally, a `spurious correlation' is the dependence of a model on some aspect of the input data that an analyst thinks shouldn't matter. In machine learning, these have a know-it-when-you-see-it character; e.g., changing the gender of a sentence's subject changes a sentiment predictor's output. To check for spurious correlations, we can `stress test' models by perturbing irrelevant parts of input data and seeing if model predictions change. In this paper, we study stress testing using the tools of causal inference. We introduce \emph{counterfactual invariance} as a formalization of the requirement that changing irrelevant parts of the input shouldn't change model predictions. We connect counterfactual invariance to out-of-domain model performance, and provide practical schemes for learning (approximately) counterfactual invariant predictors (without access to counterfactual examples). It turns out that both the means and implications of counterfactual invariance depend fundamentally on the true underlying causal structure of the data. Distinct causal structures require distinct regularization schemes to induce counterfactual invariance. Similarly, counterfactual invariance implies different domain shift guarantees depending on the underlying causal structure. This theory is supported by empirical results on text classification.
Deconfounding Scores: Feature Representations for Causal Effect Estimation with Weak Overlap
Apr 12, 2021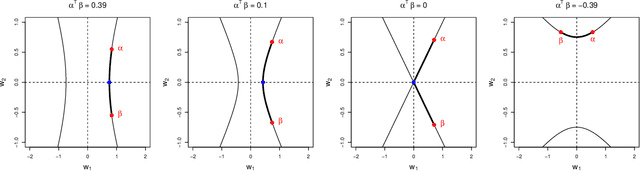

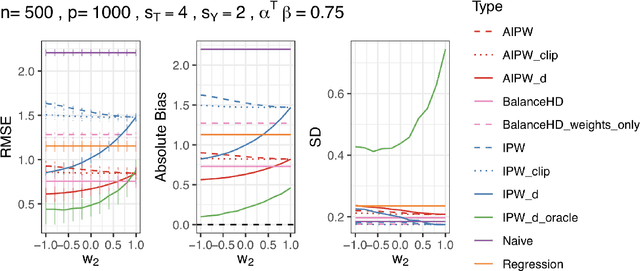
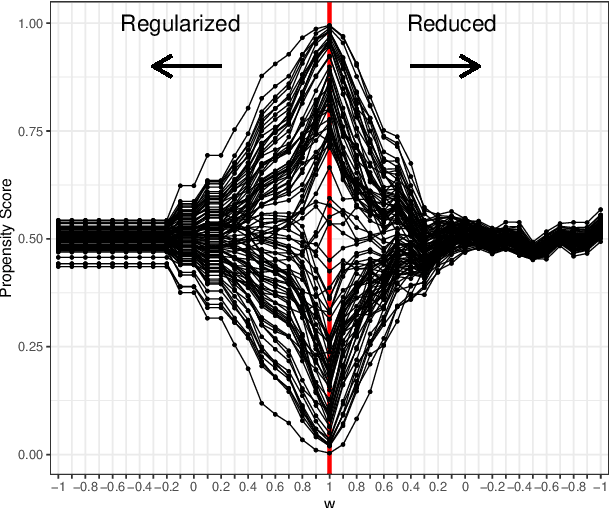
A key condition for obtaining reliable estimates of the causal effect of a treatment is overlap (a.k.a. positivity): the distributions of the features used to perform causal adjustment cannot be too different in the treated and control groups. In cases where overlap is poor, causal effect estimators can become brittle, especially when they incorporate weighting. To address this problem, a number of proposals (including confounder selection or dimension reduction methods) incorporate feature representations to induce better overlap between the treated and control groups. A key concern in these proposals is that the representation may introduce confounding bias into the effect estimator. In this paper, we introduce deconfounding scores, which are feature representations that induce better overlap without biasing the target of estimation. We show that deconfounding scores satisfy a zero-covariance condition that is identifiable in observed data. As a proof of concept, we characterize a family of deconfounding scores in a simplified setting with Gaussian covariates, and show that in some simple simulations, these scores can be used to construct estimators with good finite-sample properties. In particular, we show that this technique could be an attractive alternative to standard regularizations that are often applied to IPW and balancing weights.
Revisiting Rashomon: A Comment on "The Two Cultures"
Apr 05, 2021Here, I provide some reflections on Prof. Leo Breiman's "The Two Cultures" paper. I focus specifically on the phenomenon that Breiman dubbed the "Rashomon Effect", describing the situation in which there are many models that satisfy predictive accuracy criteria equally well, but process information in the data in substantially different ways. This phenomenon can make it difficult to draw conclusions or automate decisions based on a model fit to data. I make connections to recent work in the Machine Learning literature that explore the implications of this issue, and note that grappling with it can be a fruitful area of collaboration between the algorithmic and data modeling cultures.
SLOE: A Faster Method for Statistical Inference in High-Dimensional Logistic Regression
Mar 23, 2021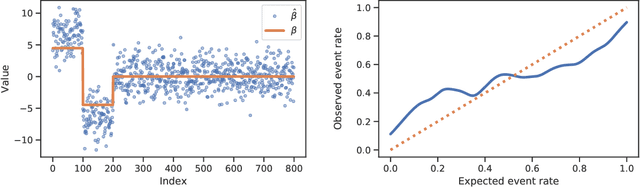
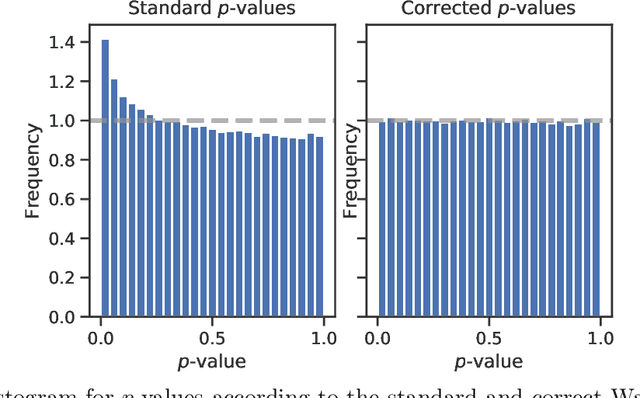
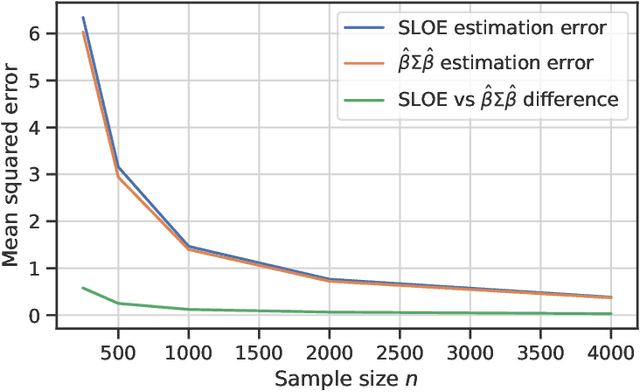
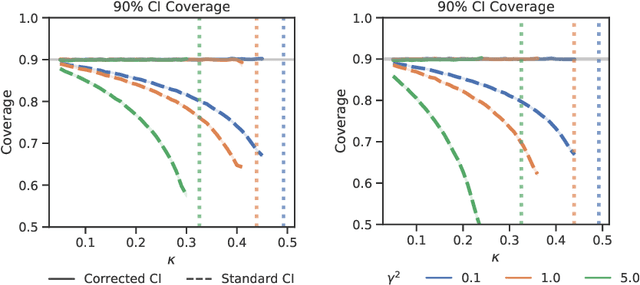
Logistic regression remains one of the most widely used tools in applied statistics, machine learning and data science. Practical datasets often have a substantial number of features $d$ relative to the sample size $n$. In these cases, the logistic regression maximum likelihood estimator (MLE) is biased, and its standard large-sample approximation is poor. In this paper, we develop an improved method for debiasing predictions and estimating frequentist uncertainty for such datasets. We build on recent work characterizing the asymptotic statistical behavior of the MLE in the regime where the aspect ratio $d / n$, instead of the number of features $d$, remains fixed as $n$ grows. In principle, this approximation facilitates bias and uncertainty corrections, but in practice, these corrections require an estimate of the signal strength of the predictors. Our main contribution is SLOE, an estimator of the signal strength with convergence guarantees that reduces the computation time of estimation and inference by orders of magnitude. The bias correction that this facilitates also reduces the variance of the predictions, yielding narrower confidence intervals with higher (valid) coverage of the true underlying probabilities and parameters. We provide an open source package for this method, available at https://github.com/google-research/sloe-logistic.