 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAjmal Mian
Vision Transformer Based Model for Describing a Set of Images as a Story
Oct 11, 2022

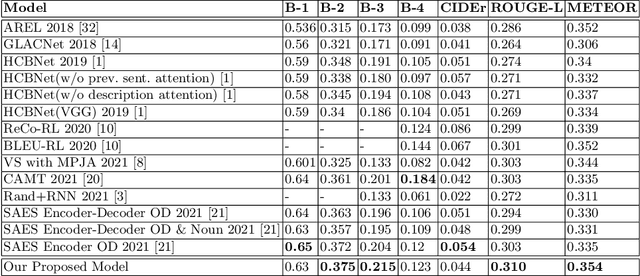
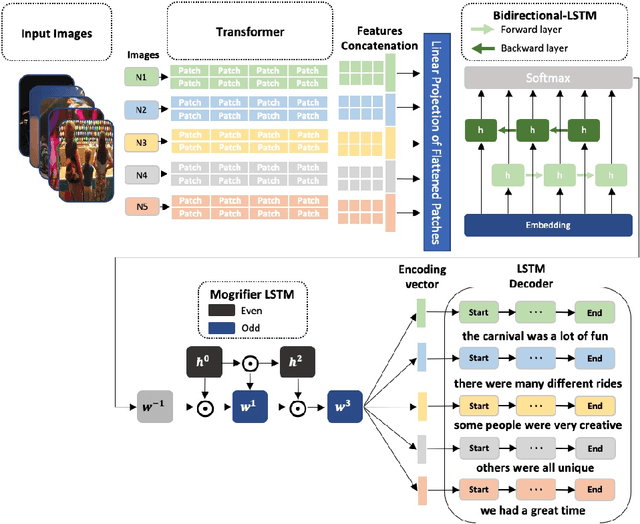

Visual Story-Telling is the process of forming a multi-sentence story from a set of images. Appropriately including visual variation and contextual information captured inside the input images is one of the most challenging aspects of visual storytelling. Consequently, stories developed from a set of images often lack cohesiveness, relevance, and semantic relationship. In this paper, we propose a novel Vision Transformer Based Model for describing a set of images as a story. The proposed method extracts the distinct features of the input images using a Vision Transformer (ViT). Firstly, input images are divided into 16X16 patches and bundled into a linear projection of flattened patches. The transformation from a single image to multiple image patches captures the visual variety of the input visual patterns. These features are used as input to a Bidirectional-LSTM which is part of the sequence encoder. This captures the past and future image context of all image patches. Then, an attention mechanism is implemented and used to increase the discriminatory capacity of the data fed into the language model, i.e. a Mogrifier-LSTM. The performance of our proposed model is evaluated using the Visual Story-Telling dataset (VIST), and the results show that our model outperforms the current state of the art models.
Vision Transformers for Action Recognition: A Survey
Sep 13, 2022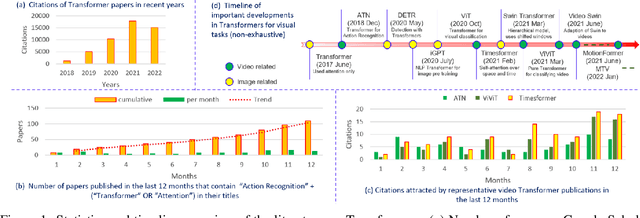
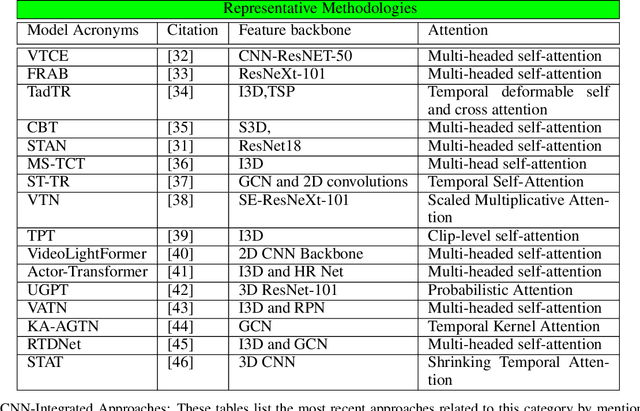
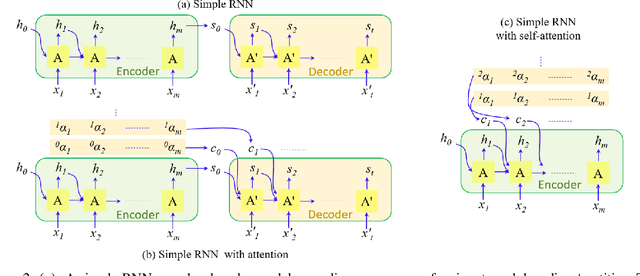
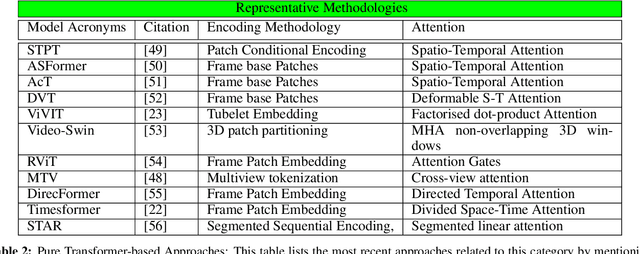
Vision transformers are emerging as a powerful tool to solve computer vision problems. Recent techniques have also proven the efficacy of transformers beyond the image domain to solve numerous video-related tasks. Among those, human action recognition is receiving special attention from the research community due to its widespread applications. This article provides the first comprehensive survey of vision transformer techniques for action recognition. We analyze and summarize the existing and emerging literature in this direction while highlighting the popular trends in adapting transformers for action recognition. Due to their specialized application, we collectively refer to these methods as ``action transformers''. Our literature review provides suitable taxonomies for action transformers based on their architecture, modality, and intended objective. Within the context of action transformers, we explore the techniques to encode spatio-temporal data, dimensionality reduction, frame patch and spatio-temporal cube construction, and various representation methods. We also investigate the optimization of spatio-temporal attention in transformer layers to handle longer sequences, typically by reducing the number of tokens in a single attention operation. Moreover, we also investigate different network learning strategies, such as self-supervised and zero-shot learning, along with their associated losses for transformer-based action recognition. This survey also summarizes the progress towards gaining grounds on evaluation metric scores on important benchmarks with action transformers. Finally, it provides a discussion on the challenges, outlook, and future avenues for this research direction.
Domain-invariant Prototypes for Semantic Segmentation
Aug 12, 2022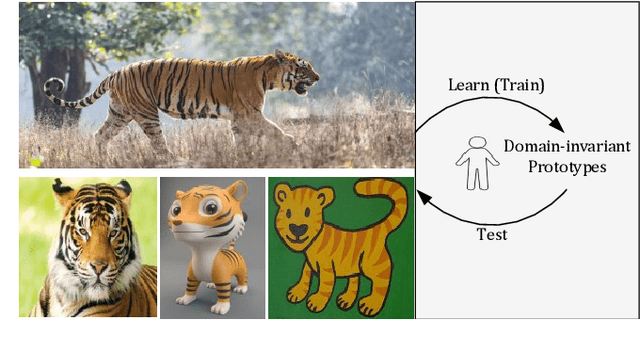
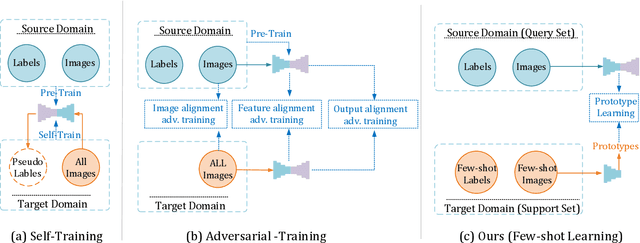
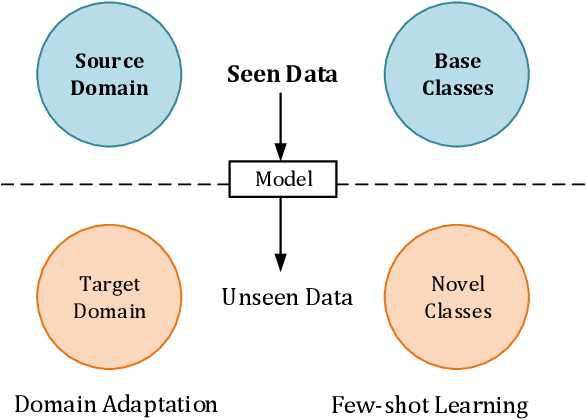
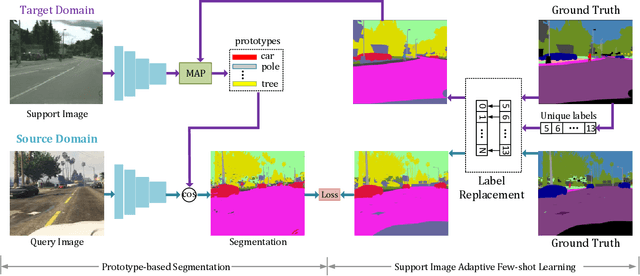
Deep Learning has greatly advanced the performance of semantic segmentation, however, its success relies on the availability of large amounts of annotated data for training. Hence, many efforts have been devoted to domain adaptive semantic segmentation that focuses on transferring semantic knowledge from a labeled source domain to an unlabeled target domain. Existing self-training methods typically require multiple rounds of training, while another popular framework based on adversarial training is known to be sensitive to hyper-parameters. In this paper, we present an easy-to-train framework that learns domain-invariant prototypes for domain adaptive semantic segmentation. In particular, we show that domain adaptation shares a common character with few-shot learning in that both aim to recognize some types of unseen data with knowledge learned from large amounts of seen data. Thus, we propose a unified framework for domain adaptation and few-shot learning. The core idea is to use the class prototypes extracted from few-shot annotated target images to classify pixels of both source images and target images. Our method involves only one-stage training and does not need to be trained on large-scale un-annotated target images. Moreover, our method can be extended to variants of both domain adaptation and few-shot learning. Experiments on adapting GTA5-to-Cityscapes and SYNTHIA-to-Cityscapes show that our method achieves competitive performance to state-of-the-art.
On Higher Adversarial Susceptibility of Contrastive Self-Supervised Learning
Jul 22, 2022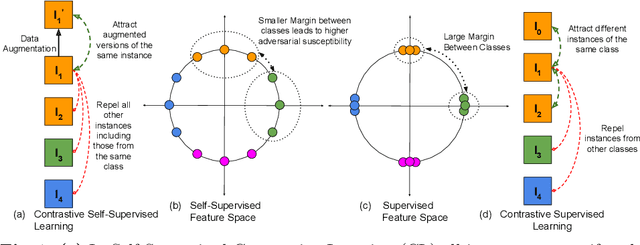

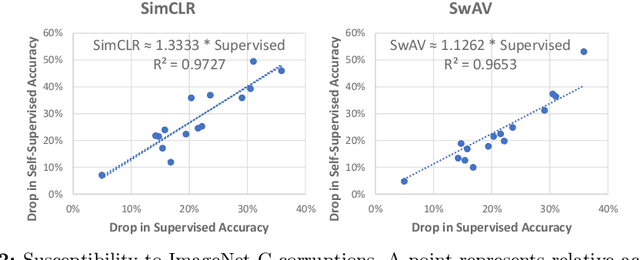

Contrastive self-supervised learning (CSL) has managed to match or surpass the performance of supervised learning in image and video classification. However, it is still largely unknown if the nature of the representation induced by the two learning paradigms is similar. We investigate this under the lens of adversarial robustness. Our analytical treatment of the problem reveals intrinsic higher sensitivity of CSL over supervised learning. It identifies the uniform distribution of data representation over a unit hypersphere in the CSL representation space as the key contributor to this phenomenon. We establish that this increases model sensitivity to input perturbations in the presence of false negatives in the training data. Our finding is supported by extensive experiments for image and video classification using adversarial perturbations and other input corruptions. Building on the insights, we devise strategies that are simple, yet effective in improving model robustness with CSL training. We demonstrate up to 68% reduction in the performance gap between adversarially attacked CSL and its supervised counterpart. Finally, we contribute to robust CSL paradigm by incorporating our findings in adversarial self-supervised learning. We demonstrate an average gain of about 5% over two different state-of-the-art methods in this domain.
Region Aware Video Object Segmentation with Deep Motion Modeling
Jul 21, 2022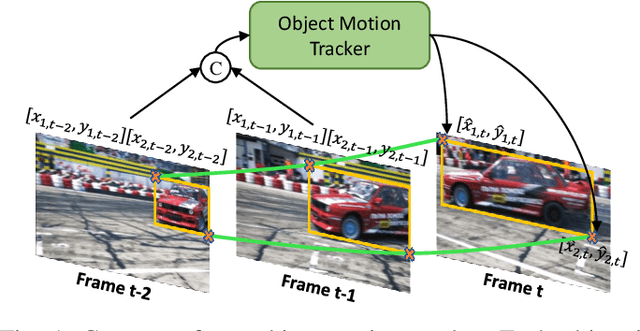
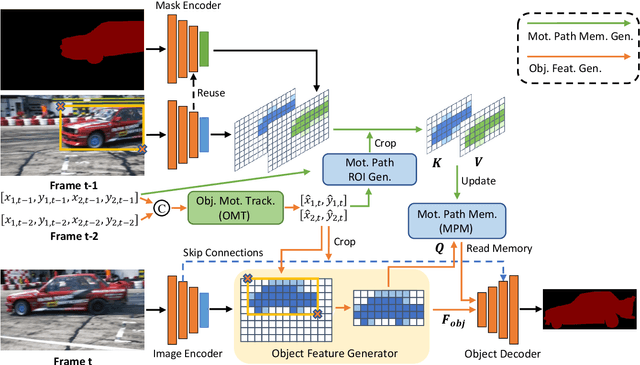

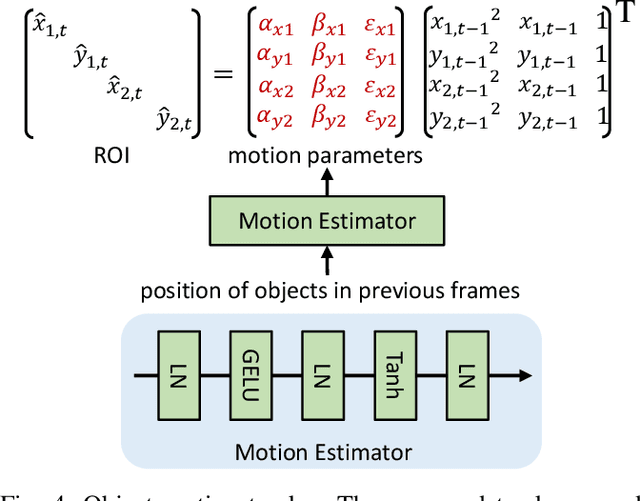
Current semi-supervised video object segmentation (VOS) methods usually leverage the entire features of one frame to predict object masks and update memory. This introduces significant redundant computations. To reduce redundancy, we present a Region Aware Video Object Segmentation (RAVOS) approach that predicts regions of interest (ROIs) for efficient object segmentation and memory storage. RAVOS includes a fast object motion tracker to predict their ROIs in the next frame. For efficient segmentation, object features are extracted according to the ROIs, and an object decoder is designed for object-level segmentation. For efficient memory storage, we propose motion path memory to filter out redundant context by memorizing the features within the motion path of objects between two frames. Besides RAVOS, we also propose a large-scale dataset, dubbed OVOS, to benchmark the performance of VOS models under occlusions. Evaluation on DAVIS and YouTube-VOS benchmarks and our new OVOS dataset show that our method achieves state-of-the-art performance with significantly faster inference time, e.g., 86.1 J&F at 42 FPS on DAVIS and 84.4 J&F at 23 FPS on YouTube-VOS.
Learning from Pixel-Level Noisy Label : A New Perspective for Light Field Saliency Detection
Apr 28, 2022

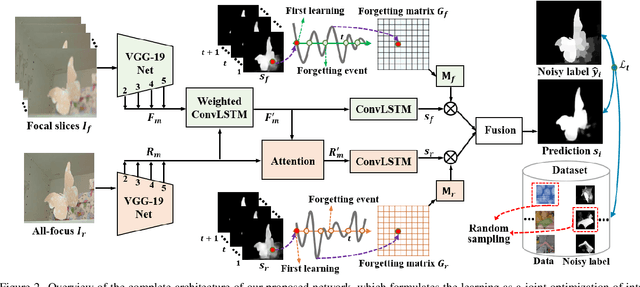
Saliency detection with light field images is becoming attractive given the abundant cues available, however, this comes at the expense of large-scale pixel level annotated data which is expensive to generate. In this paper, we propose to learn light field saliency from pixel-level noisy labels obtained from unsupervised hand crafted featured based saliency methods. Given this goal, a natural question is: can we efficiently incorporate the relationships among light field cues while identifying clean labels in a unified framework? We address this question by formulating the learning as a joint optimization of intra light field features fusion stream and inter scenes correlation stream to generate the predictions. Specially, we first introduce a pixel forgetting guided fusion module to mutually enhance the light field features and exploit pixel consistency across iterations to identify noisy pixels. Next, we introduce a cross scene noise penalty loss for better reflecting latent structures of training data and enabling the learning to be invariant to noise. Extensive experiments on multiple benchmark datasets demonstrate the superiority of our framework showing that it learns saliency prediction comparable to state-of-the-art fully supervised light field saliency methods. Our code is available at https://github.com/OLobbCode/NoiseLF.
Visual Attention Methods in Deep Learning: An In-Depth Survey
Apr 21, 2022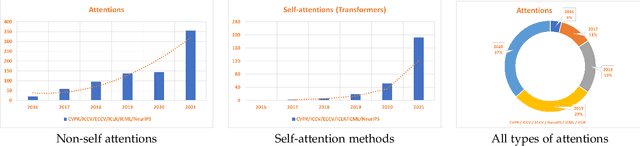
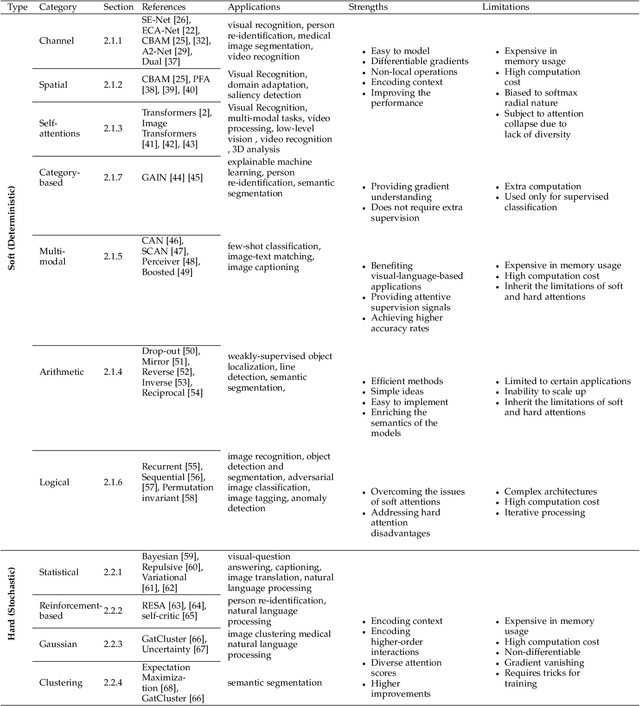
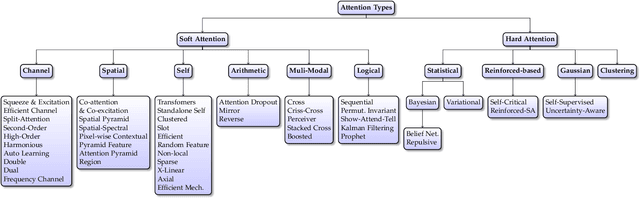
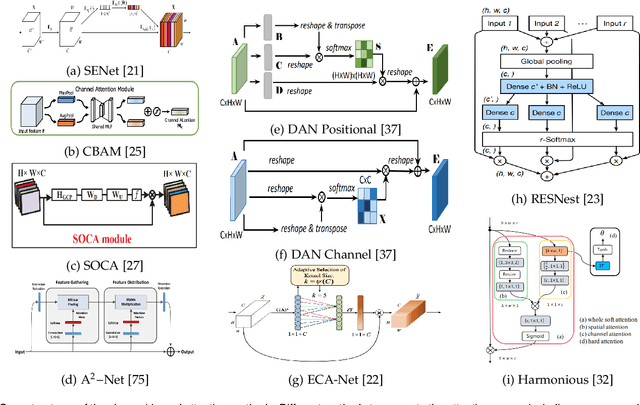
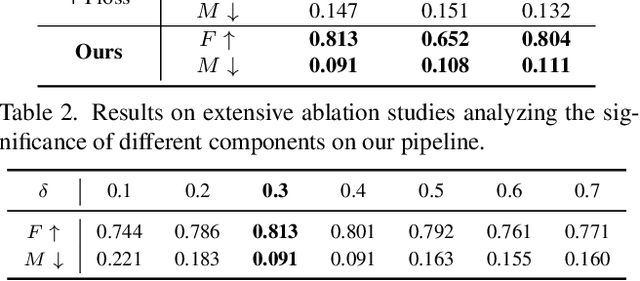
Inspired by the human cognitive system, attention is a mechanism that imitates the human cognitive awareness about specific information, amplifying critical details to focus more on the essential aspects of data. Deep learning has employed attention to boost performance for many applications. Interestingly, the same attention design can suit processing different data modalities and can easily be incorporated into large networks. Furthermore, multiple complementary attention mechanisms can be incorporated in one network. Hence, attention techniques have become extremely attractive. However, the literature lacks a comprehensive survey specific to attention techniques to guide researchers in employing attention in their deep models. Note that, besides being demanding in terms of training data and computational resources, transformers only cover a single category in self-attention out of the many categories available. We fill this gap and provide an in-depth survey of 50 attention techniques categorizing them by their most prominent features. We initiate our discussion by introducing the fundamental concepts behind the success of attention mechanism. Next, we furnish some essentials such as the strengths and limitations of each attention category, describe their fundamental building blocks, basic formulations with primary usage, and applications specifically for computer vision. We also discuss the challenges and open questions related to attention mechanism in general. Finally, we recommend possible future research directions for deep attention.
UNICON: Combating Label Noise Through Uniform Selection and Contrastive Learning
Apr 05, 2022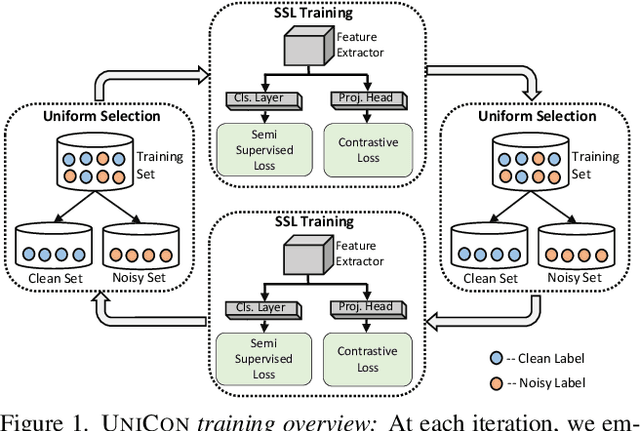

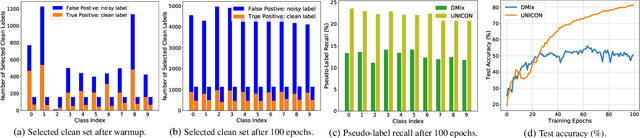
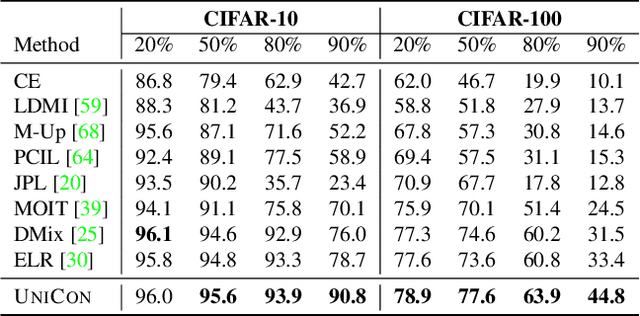
Supervised deep learning methods require a large repository of annotated data; hence, label noise is inevitable. Training with such noisy data negatively impacts the generalization performance of deep neural networks. To combat label noise, recent state-of-the-art methods employ some sort of sample selection mechanism to select a possibly clean subset of data. Next, an off-the-shelf semi-supervised learning method is used for training where rejected samples are treated as unlabeled data. Our comprehensive analysis shows that current selection methods disproportionately select samples from easy (fast learnable) classes while rejecting those from relatively harder ones. This creates class imbalance in the selected clean set and in turn, deteriorates performance under high label noise. In this work, we propose UNICON, a simple yet effective sample selection method which is robust to high label noise. To address the disproportionate selection of easy and hard samples, we introduce a Jensen-Shannon divergence based uniform selection mechanism which does not require any probabilistic modeling and hyperparameter tuning. We complement our selection method with contrastive learning to further combat the memorization of noisy labels. Extensive experimentation on multiple benchmark datasets demonstrates the effectiveness of UNICON; we obtain an 11.4% improvement over the current state-of-the-art on CIFAR100 dataset with a 90% noise rate. Our code is publicly available
DualConv: Dual Convolutional Kernels for Lightweight Deep Neural Networks
Feb 15, 2022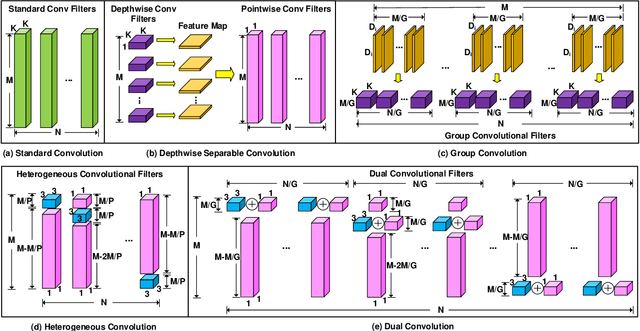
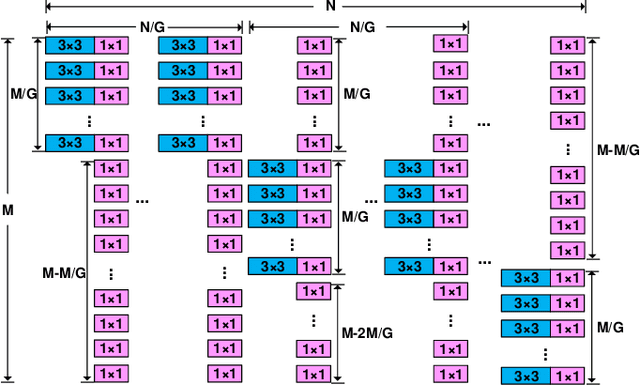
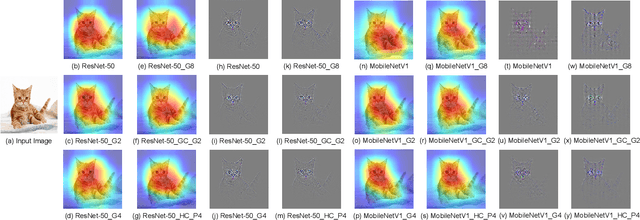
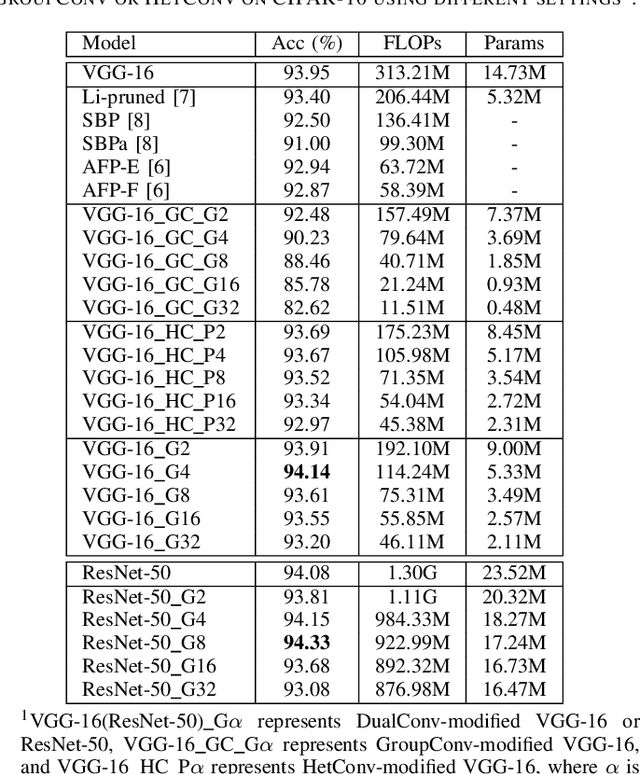
CNN architectures are generally heavy on memory and computational requirements which makes them infeasible for embedded systems with limited hardware resources. We propose dual convolutional kernels (DualConv) for constructing lightweight deep neural networks. DualConv combines 3$\times$3 and 1$\times$1 convolutional kernels to process the same input feature map channels simultaneously and exploits the group convolution technique to efficiently arrange convolutional filters. DualConv can be employed in any CNN model such as VGG-16 and ResNet-50 for image classification, YOLO and R-CNN for object detection, or FCN for semantic segmentation. In this paper, we extensively test DualConv for classification since these network architectures form the backbones for many other tasks. We also test DualConv for image detection on YOLO-V3. Experimental results show that, combined with our structural innovations, DualConv significantly reduces the computational cost and number of parameters of deep neural networks while surprisingly achieving slightly higher accuracy than the original models in some cases. We use DualConv to further reduce the number of parameters of the lightweight MobileNetV2 by 54% with only 0.68% drop in accuracy on CIFAR-100 dataset. When the number of parameters is not an issue, DualConv increases the accuracy of MobileNetV1 by 4.11% on the same dataset. Furthermore, DualConv significantly improves the YOLO-V3 object detection speed and improves its accuracy by 4.4% on PASCAL VOC dataset.
Bi-CLKT: Bi-Graph Contrastive Learning based Knowledge Tracing
Jan 22, 2022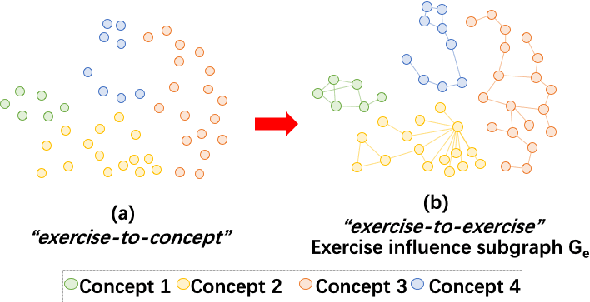
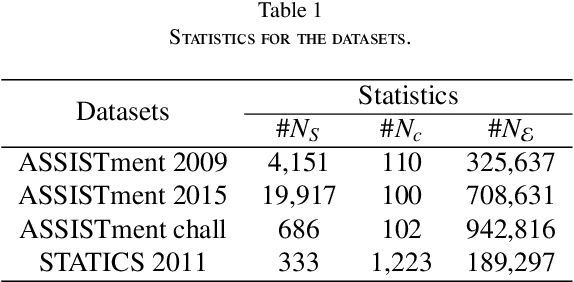
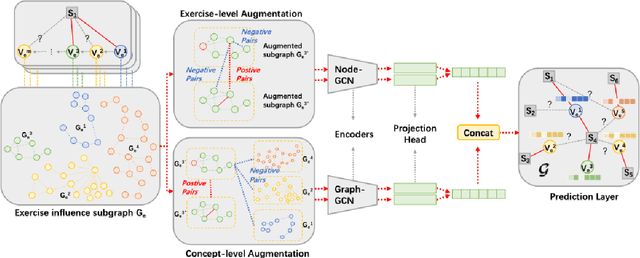
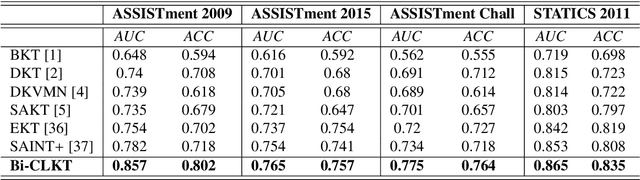
The goal of Knowledge Tracing (KT) is to estimate how well students have mastered a concept based on their historical learning of related exercises. The benefit of knowledge tracing is that students' learning plans can be better organised and adjusted, and interventions can be made when necessary. With the recent rise of deep learning, Deep Knowledge Tracing (DKT) has utilised Recurrent Neural Networks (RNNs) to accomplish this task with some success. Other works have attempted to introduce Graph Neural Networks (GNNs) and redefine the task accordingly to achieve significant improvements. However, these efforts suffer from at least one of the following drawbacks: 1) they pay too much attention to details of the nodes rather than to high-level semantic information; 2) they struggle to effectively establish spatial associations and complex structures of the nodes; and 3) they represent either concepts or exercises only, without integrating them. Inspired by recent advances in self-supervised learning, we propose a Bi-Graph Contrastive Learning based Knowledge Tracing (Bi-CLKT) to address these limitations. Specifically, we design a two-layer contrastive learning scheme based on an "exercise-to-exercise" (E2E) relational subgraph. It involves node-level contrastive learning of subgraphs to obtain discriminative representations of exercises, and graph-level contrastive learning to obtain discriminative representations of concepts. Moreover, we designed a joint contrastive loss to obtain better representations and hence better prediction performance. Also, we explored two different variants, using RNN and memory-augmented neural networks as the prediction layer for comparison to obtain better representations of exercises and concepts respectively. Extensive experiments on four real-world datasets show that the proposed Bi-CLKT and its variants outperform other baseline models.