 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompRess: Self-Supervised Learning by Compressing Representations
Oct 28, 2020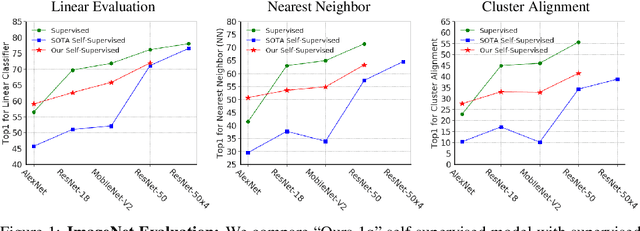
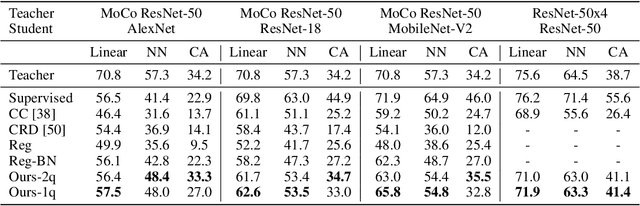
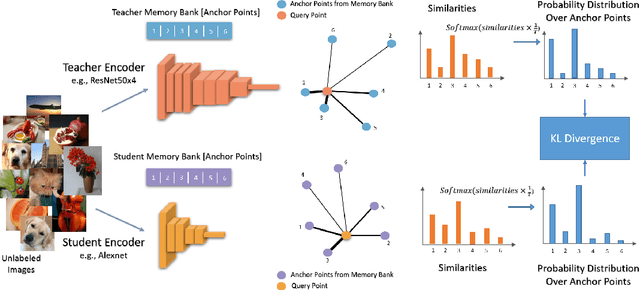

Self-supervised learning aims to learn good representations with unlabeled data. Recent works have shown that larger models benefit more from self-supervised learning than smaller models. As a result, the gap between supervised and self-supervised learning has been greatly reduced for larger models. In this work, instead of designing a new pseudo task for self-supervised learning, we develop a model compression method to compress an already learned, deep self-supervised model (teacher) to a smaller one (student). We train the student model so that it mimics the relative similarity between the data points in the teacher's embedding space. For AlexNet, our method outperforms all previous methods including the fully supervised model on ImageNet linear evaluation (59.0% compared to 56.5%) and on nearest neighbor evaluation (50.7% compared to 41.4%). To the best of our knowledge, this is the first time a self-supervised AlexNet has outperformed supervised one on ImageNet classification. Our code is available here: https://github.com/UMBCvision/CompRess
A simple baseline for domain adaptation using rotation prediction
Dec 26, 2019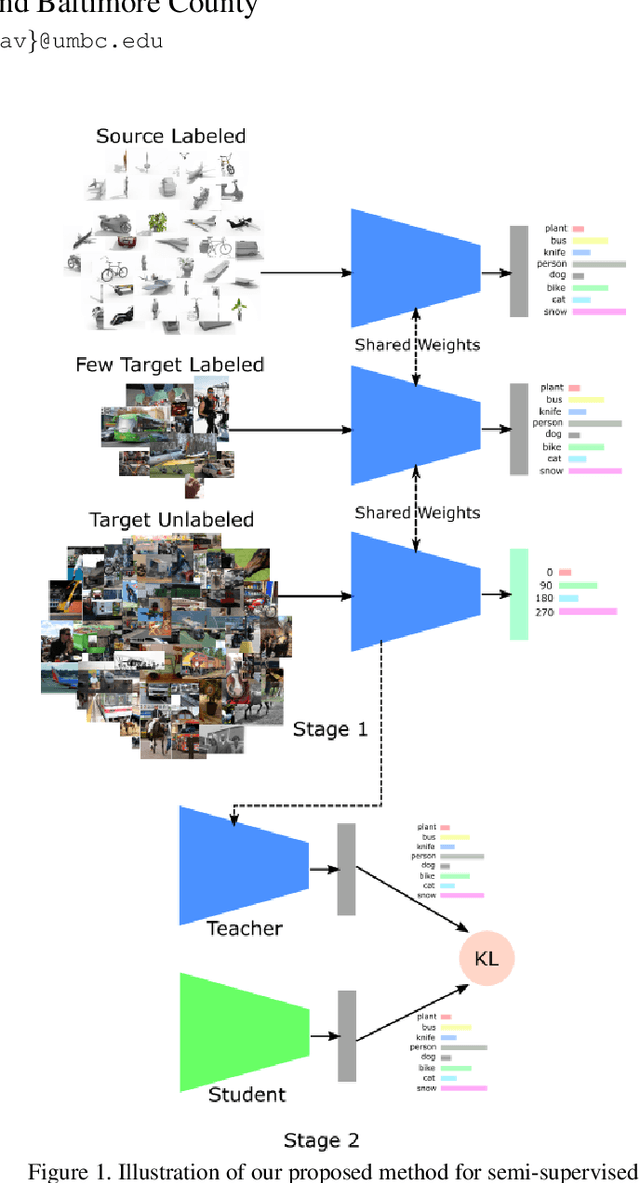
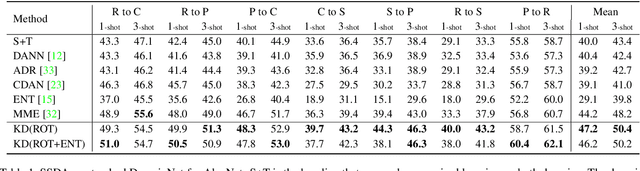

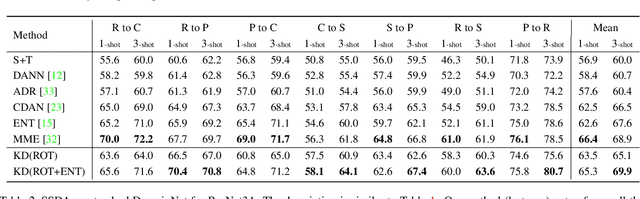
Recently, domain adaptation has become a hot research area with lots of applications. The goal is to adapt a model trained in one domain to another domain with scarce annotated data. We propose a simple yet effective method based on self-supervised learning that outperforms or is on par with most state-of-the-art algorithms, e.g. adversarial domain adaptation. Our method involves two phases: predicting random rotations (self-supervised) on the target domain along with correct labels for the source domain (supervised), and then using self-distillation on the target domain. Our simple method achieves state-of-the-art results on semi-supervised domain adaptation on DomainNet dataset. Further, we observe that the unlabeled target datasets of popular domain adaptation benchmarks do not contain any categories apart from testing categories. We believe this introduces a bias that does not exist in many real applications. We show that removing this bias from the unlabeled data results in a large drop in performance of state-of-the-art methods, while our simple method is relatively robust.