 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdish Singla
Evaluating ChatGPT and GPT-4 for Visual Programming
Jul 30, 2023
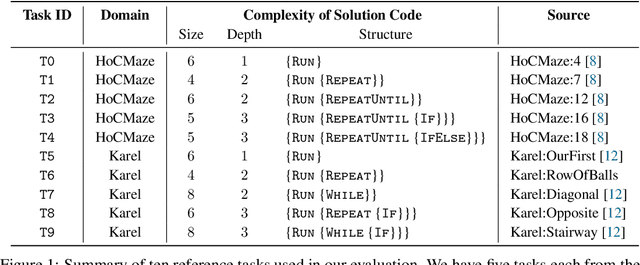

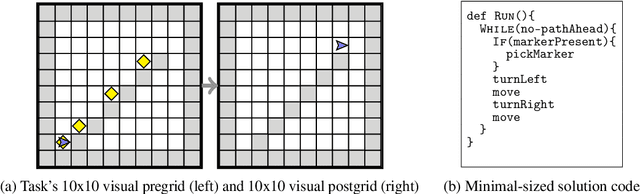

Generative AI and large language models have the potential to drastically improve the landscape of computing education by automatically generating personalized feedback and content. Recent works have studied the capabilities of these models for different programming education scenarios; however, these works considered only text-based programming, in particular, Python programming. Consequently, they leave open the question of how well these models would perform in visual programming domains popularly used for K-8 programming education. The main research question we study is: Do state-of-the-art generative models show advanced capabilities in visual programming on par with their capabilities in text-based Python programming? In our work, we evaluate two models, ChatGPT (based on GPT-3.5) and GPT-4, in visual programming domains for various scenarios and assess performance using expert-based annotations. In particular, we base our evaluation using reference tasks from the domains of Hour of Code: Maze Challenge by Code-dot-org and Karel. Our results show that these models perform poorly and struggle to combine spatial, logical, and programming skills crucial for visual programming. These results also provide exciting directions for future work on developing techniques to improve the performance of generative models in visual programming.
Generative AI for Programming Education: Benchmarking ChatGPT, GPT-4, and Human Tutors
Jun 30, 2023
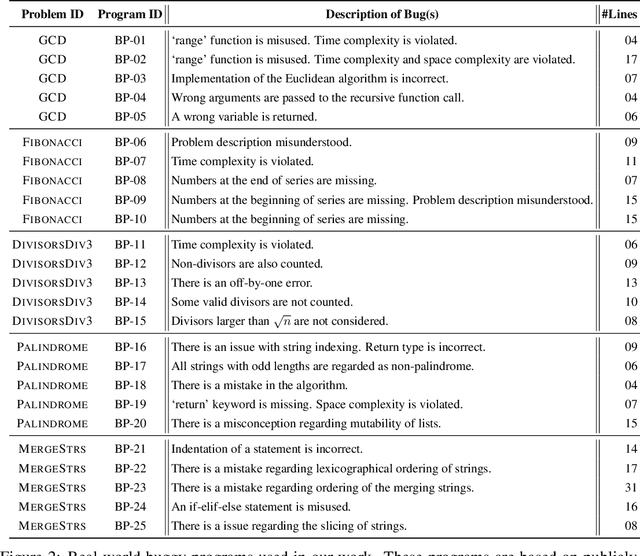
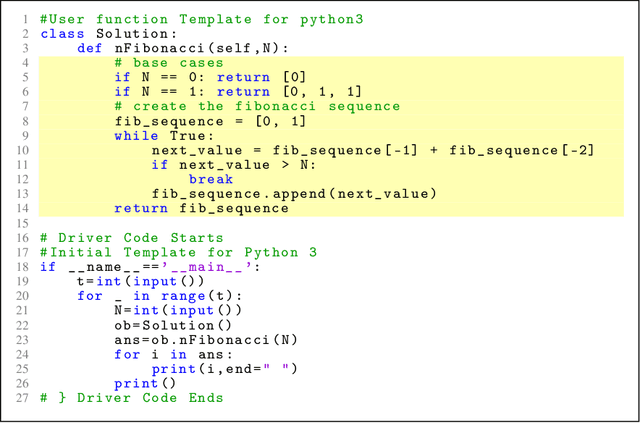

Generative AI and large language models hold great promise in enhancing computing education by powering next-generation educational technologies for introductory programming. Recent works have studied these models for different scenarios relevant to programming education; however, these works are limited for several reasons, as they typically consider already outdated models or only specific scenario(s). Consequently, there is a lack of a systematic study that benchmarks state-of-the-art models for a comprehensive set of programming education scenarios. In our work, we systematically evaluate two models, ChatGPT (based on GPT-3.5) and GPT-4, and compare their performance with human tutors for a variety of scenarios. We evaluate using five introductory Python programming problems and real-world buggy programs from an online platform, and assess performance using expert-based annotations. Our results show that GPT-4 drastically outperforms ChatGPT (based on GPT-3.5) and comes close to human tutors' performance for several scenarios. These results also highlight settings where GPT-4 still struggles, providing exciting future directions on developing techniques to improve the performance of these models.
Learning Embeddings for Sequential Tasks Using Population of Agents
Jun 05, 2023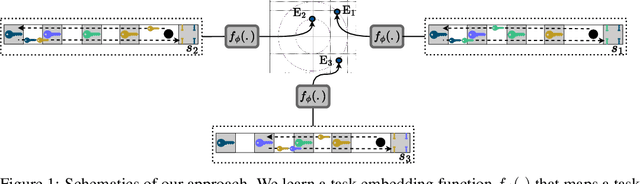
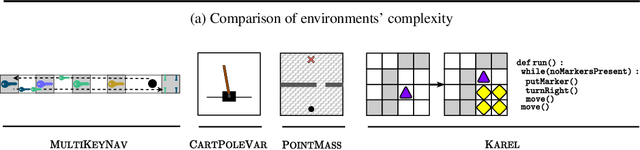
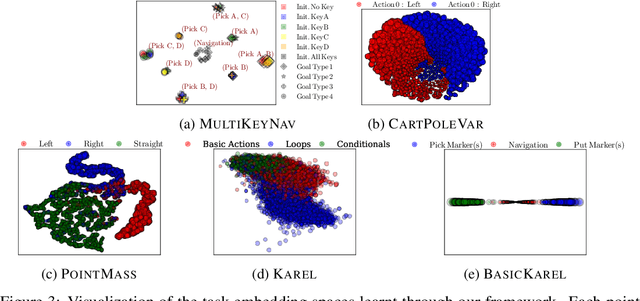

We present an information-theoretic framework to learn fixed-dimensional embeddings for tasks in reinforcement learning. We leverage the idea that two tasks are similar to each other if observing an agent's performance on one task reduces our uncertainty about its performance on the other. This intuition is captured by our information-theoretic criterion which uses a diverse population of agents to measure similarity between tasks in sequential decision-making settings. In addition to qualitative assessment, we empirically demonstrate the effectiveness of our techniques based on task embeddings by quantitative comparisons against strong baselines on two application scenarios: predicting an agent's performance on a test task by observing its performance on a small quiz of tasks, and selecting tasks with desired characteristics from a given set of options.
Neural Task Synthesis for Visual Programming
Jun 01, 2023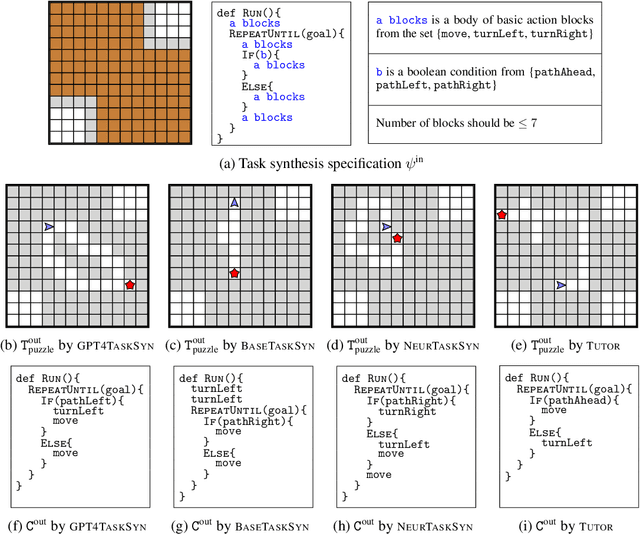
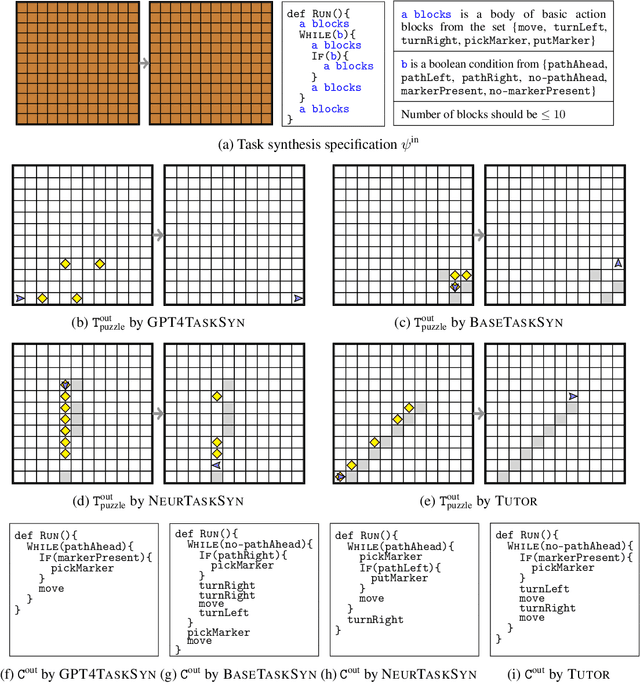
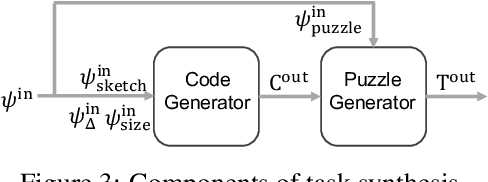
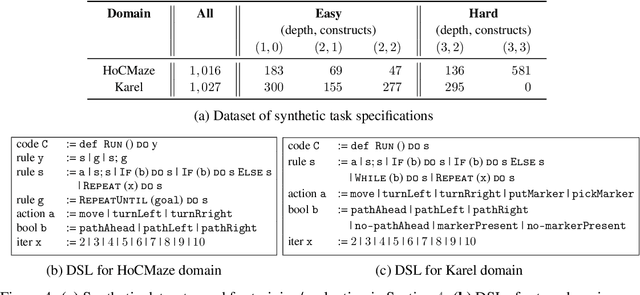
Generative neural models hold great promise in enhancing programming education by synthesizing new content for students. We seek to design neural models that can automatically generate programming tasks for a given specification in the context of visual programming domains. Despite the recent successes of large generative models like GPT-4, our initial results show that these models are ineffective in synthesizing visual programming tasks and struggle with logical and spatial reasoning. We propose a novel neuro-symbolic technique, NeurTaskSyn, that can synthesize programming tasks for a specification given in the form of desired programming concepts exercised by its solution code and constraints on the visual task. NeurTaskSyn has two components: the first component is trained via imitation learning procedure to generate possible solution codes, and the second component is trained via reinforcement learning procedure to guide an underlying symbolic execution engine that generates visual tasks for these codes. We demonstrate the effectiveness of NeurTaskSyn through an extensive empirical evaluation and a qualitative study on reference tasks taken from the Hour of Code: Classic Maze challenge by Code-dot-org and the Intro to Programming with Karel course by CodeHS-dot-com.
Synthesizing a Progression of Subtasks for Block-Based Visual Programming Tasks
May 27, 2023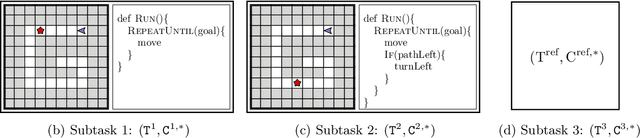
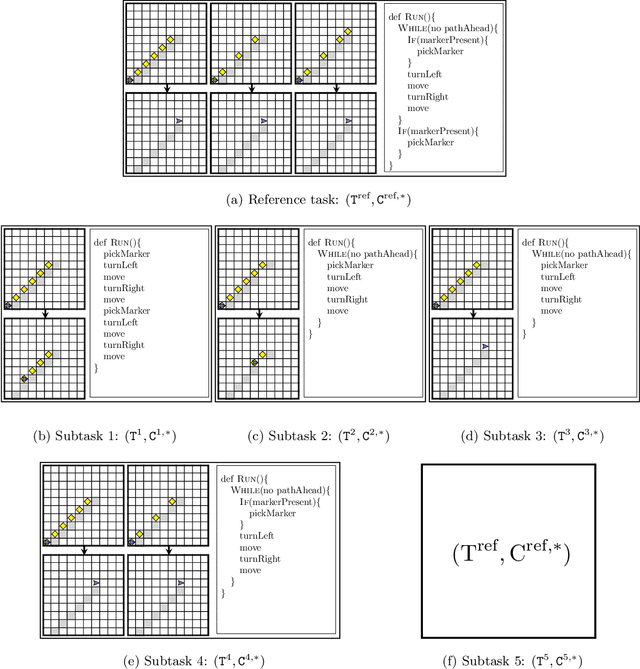
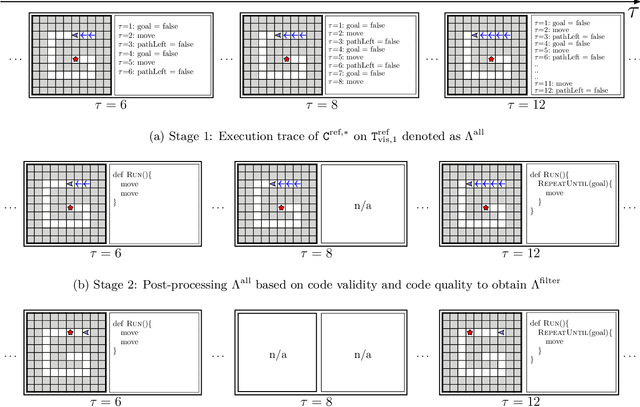
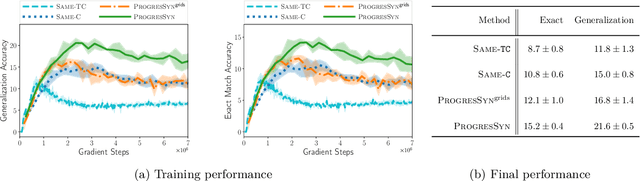
Block-based visual programming environments play an increasingly important role in introducing computing concepts to K-12 students. In recent years, they have also gained popularity in neuro-symbolic AI, serving as a benchmark to evaluate general problem-solving and logical reasoning skills. The open-ended and conceptual nature of these visual programming tasks make them challenging, both for state-of-the-art AI agents as well as for novice programmers. A natural approach to providing assistance for problem-solving is breaking down a complex task into a progression of simpler subtasks; however, this is not trivial given that the solution codes are typically nested and have non-linear execution behavior. In this paper, we formalize the problem of synthesizing such a progression for a given reference block-based visual programming task. We propose a novel synthesis algorithm that generates a progression of subtasks that are high-quality, well-spaced in terms of their complexity, and solving this progression leads to solving the reference task. We show the utility of our synthesis algorithm in improving the efficacy of AI agents (in this case, neural program synthesizers) for solving tasks in the Karel programming environment. Then, we conduct a user study to demonstrate that our synthesized progression of subtasks can assist a novice programmer in solving tasks in the Hour of Code: Maze Challenge by Code-dot-org.
Proximal Curriculum for Reinforcement Learning Agents
Apr 25, 2023
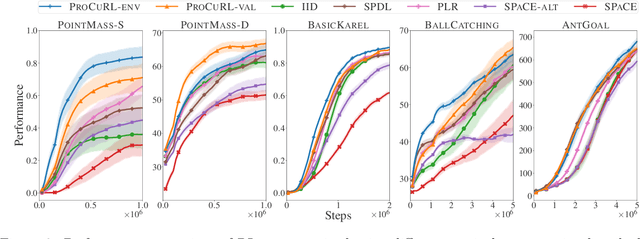
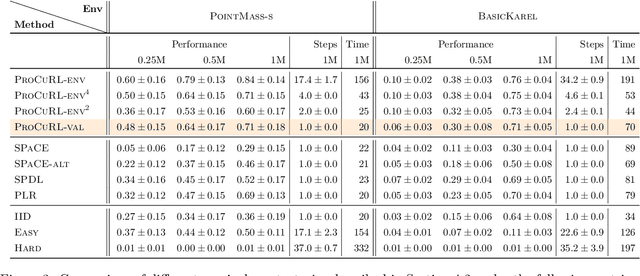
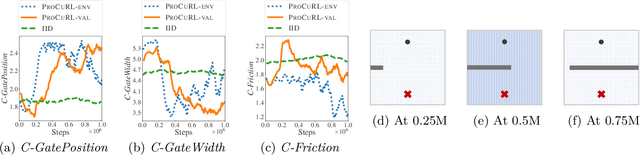
We consider the problem of curriculum design for reinforcement learning (RL) agents in contextual multi-task settings. Existing techniques on automatic curriculum design typically require domain-specific hyperparameter tuning or have limited theoretical underpinnings. To tackle these limitations, we design our curriculum strategy, ProCuRL, inspired by the pedagogical concept of Zone of Proximal Development (ZPD). ProCuRL captures the intuition that learning progress is maximized when picking tasks that are neither too hard nor too easy for the learner. We mathematically derive ProCuRL by analyzing two simple learning settings. We also present a practical variant of ProCuRL that can be directly integrated with deep RL frameworks with minimal hyperparameter tuning. Experimental results on a variety of domains demonstrate the effectiveness of our curriculum strategy over state-of-the-art baselines in accelerating the training process of deep RL agents.
Adaptive Scaffolding in Block-Based Programming via Synthesizing New Tasks as Pop Quizzes
Mar 28, 2023Block-based programming environments are increasingly used to introduce computing concepts to beginners. However, novice students often struggle in these environments, given the conceptual and open-ended nature of programming tasks. To effectively support a student struggling to solve a given task, it is important to provide adaptive scaffolding that guides the student towards a solution. We introduce a scaffolding framework based on pop quizzes presented as multi-choice programming tasks. To automatically generate these pop quizzes, we propose a novel algorithm, PQuizSyn. More formally, given a reference task with a solution code and the student's current attempt, PQuizSyn synthesizes new tasks for pop quizzes with the following features: (a) Adaptive (i.e., individualized to the student's current attempt), (b) Comprehensible (i.e., easy to comprehend and solve), and (c) Concealing (i.e., do not reveal the solution code). Our algorithm synthesizes these tasks using techniques based on symbolic reasoning and graph-based code representations. We show that our algorithm can generate hundreds of pop quizzes for different student attempts on reference tasks from Hour of Code: Maze Challenge and Karel. We assess the quality of these pop quizzes through expert ratings using an evaluation rubric. Further, we have built an online platform for practicing block-based programming tasks empowered via pop quiz based feedback, and report results from an initial user study.
Implicit Poisoning Attacks in Two-Agent Reinforcement Learning: Adversarial Policies for Training-Time Attacks
Feb 27, 2023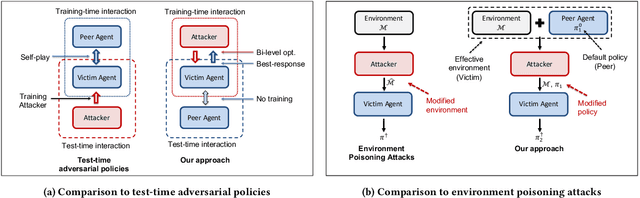

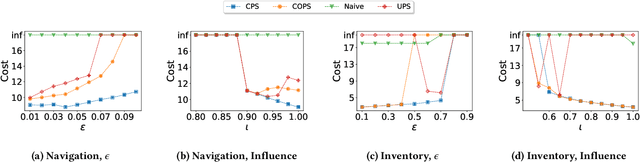
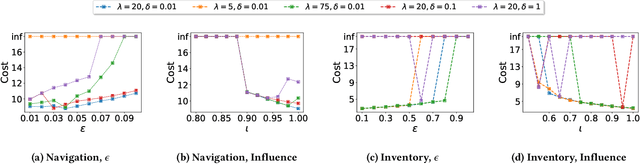
In targeted poisoning attacks, an attacker manipulates an agent-environment interaction to force the agent into adopting a policy of interest, called target policy. Prior work has primarily focused on attacks that modify standard MDP primitives, such as rewards or transitions. In this paper, we study targeted poisoning attacks in a two-agent setting where an attacker implicitly poisons the effective environment of one of the agents by modifying the policy of its peer. We develop an optimization framework for designing optimal attacks, where the cost of the attack measures how much the solution deviates from the assumed default policy of the peer agent. We further study the computational properties of this optimization framework. Focusing on a tabular setting, we show that in contrast to poisoning attacks based on MDP primitives (transitions and (unbounded) rewards), which are always feasible, it is NP-hard to determine the feasibility of implicit poisoning attacks. We provide characterization results that establish sufficient conditions for the feasibility of the attack problem, as well as an upper and a lower bound on the optimal cost of the attack. We propose two algorithmic approaches for finding an optimal adversarial policy: a model-based approach with tabular policies and a model-free approach with parametric/neural policies. We showcase the efficacy of the proposed algorithms through experiments.
Online Reinforcement Learning with Uncertain Episode Lengths
Feb 07, 2023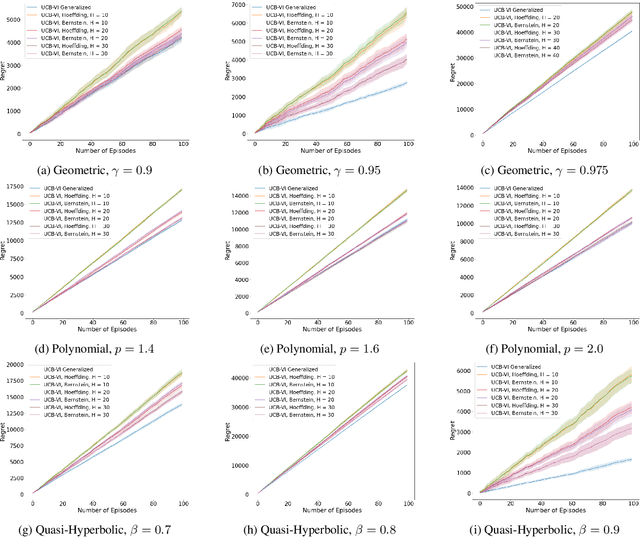
Existing episodic reinforcement algorithms assume that the length of an episode is fixed across time and known a priori. In this paper, we consider a general framework of episodic reinforcement learning when the length of each episode is drawn from a distribution. We first establish that this problem is equivalent to online reinforcement learning with general discounting where the learner is trying to optimize the expected discounted sum of rewards over an infinite horizon, but where the discounting function is not necessarily geometric. We show that minimizing regret with this new general discounting is equivalent to minimizing regret with uncertain episode lengths. We then design a reinforcement learning algorithm that minimizes regret with general discounting but acts for the setting with uncertain episode lengths. We instantiate our general bound for different types of discounting, including geometric and polynomial discounting. We also show that we can obtain similar regret bounds even when the uncertainty over the episode lengths is unknown, by estimating the unknown distribution over time. Finally, we compare our learning algorithms with existing value-iteration based episodic RL algorithms in a grid-world environment.