 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Combined CNN and LSTM Model for Arabic Sentiment Analysis
Jul 22, 2018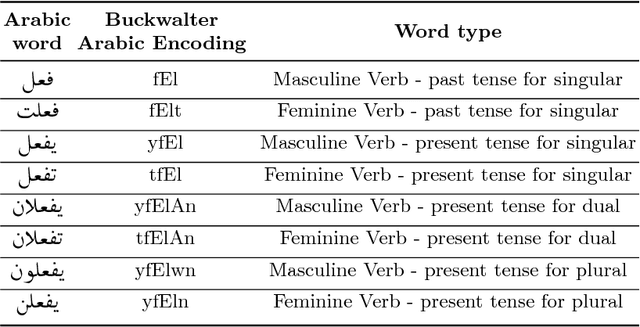
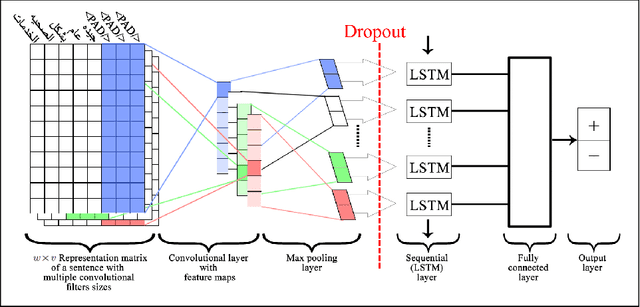
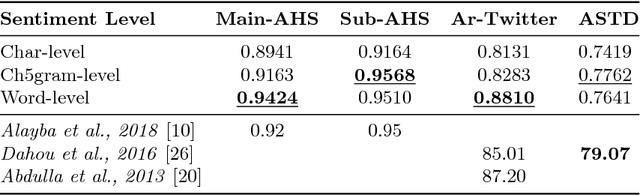
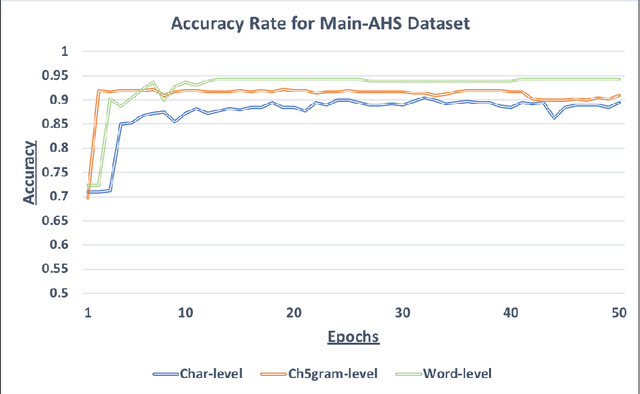
Deep neural networks have shown good data modelling capabilities when dealing with challenging and large datasets from a wide range of application areas. Convolutional Neural Networks (CNNs) offer advantages in selecting good features and Long Short-Term Memory (LSTM) networks have proven good abilities of learning sequential data. Both approaches have been reported to provide improved results in areas such image processing, voice recognition, language translation and other Natural Language Processing (NLP) tasks. Sentiment classification for short text messages from Twitter is a challenging task, and the complexity increases for Arabic language sentiment classification tasks because Arabic is a rich language in morphology. In addition, the availability of accurate pre-processing tools for Arabic is another current limitation, along with limited research available in this area. In this paper, we investigate the benefits of integrating CNNs and LSTMs and report obtained improved accuracy for Arabic sentiment analysis on different datasets. Additionally, we seek to consider the morphological diversity of particular Arabic words by using different sentiment classification levels.
* Authors accepted version of submission for CD-MAKE 2018
Improving Sentiment Analysis in Arabic Using Word Representation
Mar 30, 2018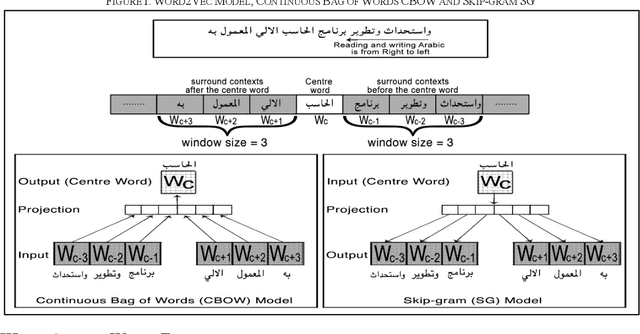
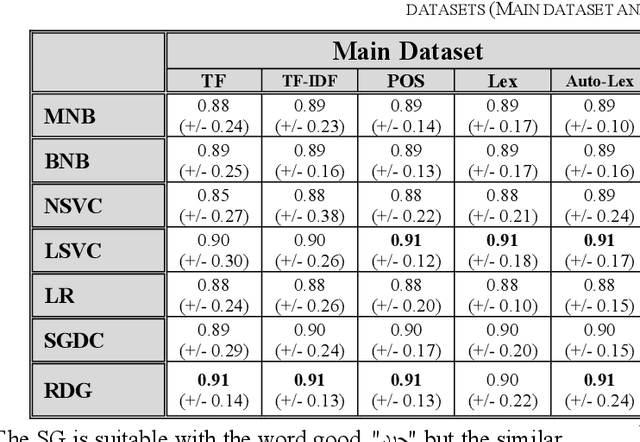
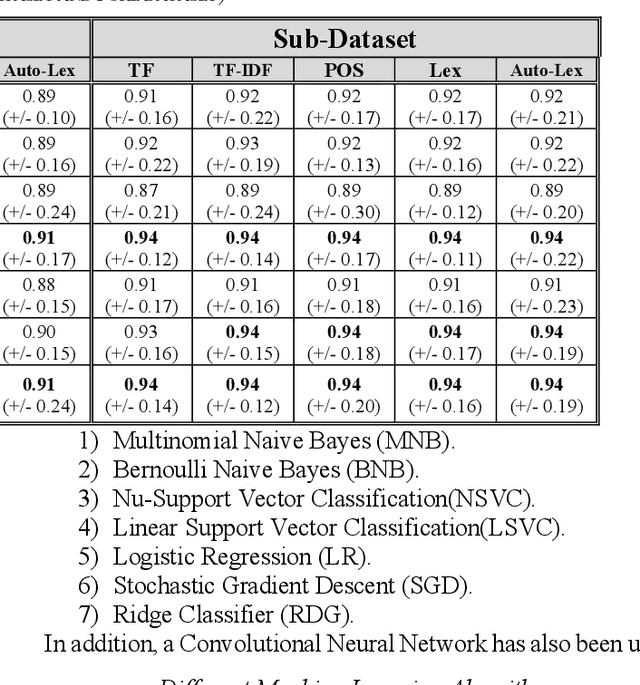
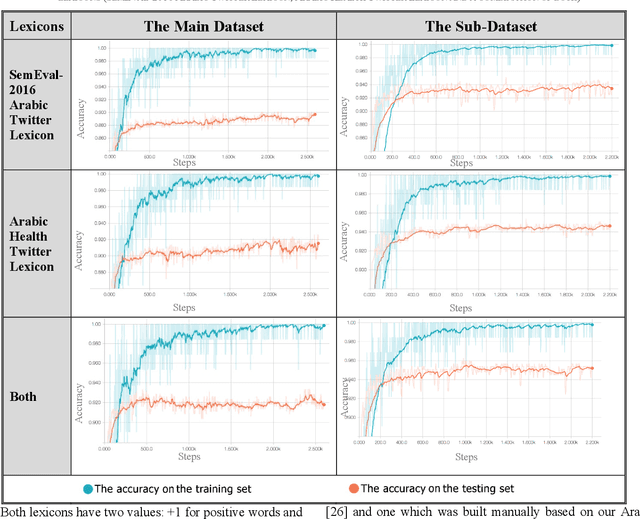
The complexities of Arabic language in morphology, orthography and dialects makes sentiment analysis for Arabic more challenging. Also, text feature extraction from short messages like tweets, in order to gauge the sentiment, makes this task even more difficult. In recent years, deep neural networks were often employed and showed very good results in sentiment classification and natural language processing applications. Word embedding, or word distributing approach, is a current and powerful tool to capture together the closest words from a contextual text. In this paper, we describe how we construct Word2Vec models from a large Arabic corpus obtained from ten newspapers in different Arab countries. By applying different machine learning algorithms and convolutional neural networks with different text feature selections, we report improved accuracy of sentiment classification (91%-95%) on our publicly available Arabic language health sentiment dataset [1]
* Authors accepted version of submission for ASAR 2018